It is fascinating to me to see how different companies with rather similar needs see the value or lack thereof of their cloud infrastructure.
Today, if you are planning on building a product, it will most probably have some kind of a server-side component – the part that gets hosted “in the cloud”. Scott M. Fulton does a great job of explaining this concept on ReadWriteWeb.
When you start developing applications with a server backend, there is a need to make the service reliable:
- Having it available to your target users
- Making sure the latencies are low when accessing the server
- Taking care of growth of the service with additional hardware
At the end of the day, your service will still experience downtime – every service does:

What are the main schools of thought when it comes to developing reliable services?
1. Outsourcing
This is probably going to be the way of the future for most.
To build an application, what you are interested in as a developer is to focus on the user experience – your actual service. In the same way that you outsource your gaming graphics to someone else’s OpenGL library, and your databases to MySQL; why not outsource your services needs to third parties?
Need to connect to multiple mobile devices? Why not use Urban Airship‘s service instead of writing your own?
Require connectivity to social networks? Why not go through oneall for that?
What about APIs for developers? Use Apigee or the likes of it.
Such reliance though comes with a price – in a way you outsource your control of being able to solve reliability issues to a third party – and in this case to multiple third parties.
The idea behind it is the expectation that each such provider is capable of being the best in his domain and that meshing them up together as part of the solution will be the best approach: it will be hard to “copy” and implement the features of all the 3 examples above – possible, but is it worth it?
2. IaaS
Infrastructure as a Service. That’s cloud for you: going to Amazon AWS, Rackspace Cloud or a bunch of other players that essentially offer managed hardware.
It is often considered a play for startups, where the investment in hardware infrastructure and management is not important and the cost of using an existing cloud solution is low.
The most known company using this approach is probably Netflix, who rely on Amazon for their service. As Barb Darrow notes:
Netflix is a good example of a company that uses Amazon for what it does best — provide scale and power — but layers its own key technologies — in the form of a “thin” PaaS atop those Amazon services. […] Netflix would like its own PaaS to get thinner over time as Amazon moves up the stack.
You stick to your core competencies – or the real added value you as a company do best and outsource the hardware infrastructure to others. You can think of it as selecting Linux as the operating system and not touching it again when you write an application. The cloud becomes the operating system.
The only problem then is reliability – you outsourced the infrastructure, but you want to rely on your own. Well, Netflix has done something about it as well with their Chaos Monkey:
Chaos Monkey randomly kills instances and services within Netflix’s AWS infrastructure to help developers to make sure each individual component returns something even when system dependencies aren’t responding.
In other words, they avoid failing by failing all the time.
3. BYODC
This approach is the one that may make sense once you start growing. As you scale up, the cost of using an external cloud to that of building your own (Build Your Own Damn Cloud) becomes a real consideration.
The most notable one I found is the Iserali company Outbrain, who is actually actively pitching companies to move from the cloud to their own data centers.
They did a very interesting talk about scalability last year [Hebrew – sorry], where Ori Lahav, the Co-founder and CTO, outlined Outbrain’s view of scalability. A part of it is the selection to go for a data center instead of a cloud installation: they opted for owning and managing their own hardware to outsourcing it to others (that would be at around 1:29:00 into the talk).
The concept behind it?
Cost
When you start growing in scale, your costs start going down if you do it on your own: you know your application best so you can optimize the hardware and the underlying operating system to fit your needs at a lower cost.
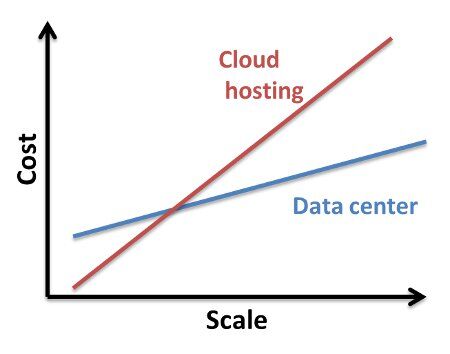
Data center vs. Cloud
Reliability
When you control the hardware as well, you are your own master. If the service goes down – you rely on your own workforce to fix it and not on an external source.
If Amazon goes down – there’s nothing you can do but wait for them. If your own servers go down in a data center, you can wake up the team and have them hack it through.
In BYODC, you gain reliability by relying only on yourself.
Hybrid?
There’s this option the creeps always – it tries to take the middle-ground, enjoying all the worlds: you use your own data centers to gain reliability, cost and control. And then you grow into the cloud when you need to scale fast.
I guess this would be the hardest one to develop and manage but the most cost effective one.