
Voice AI runs on real-time transport, and in 2026 that transport is almost always WebRTC. It is the only browser-native option built for live, low-latency audio, with the Opus codec, echo cancellation, and voice activity detection already inside. WebSocket and WebTransport are the alternatives, but WebRTC is the pragmatic default, and the one that scales when a session grows beyond one human and a bot.
This is a map of the transport layer underneath voice agents in 2026: what the options actually are, what the current players use, how WebRTC behaves today, and where the tuning that nobody does yet is going to matter.
WebRTC vs WebSocket vs WebTransport: which transport for voice AI?
In the browser there are three ways to move audio between a user and a voice agent. Native apps add a fourth, a raw QUIC or UDP path, which is what Google Gemini Live appears to use.
| Technology | Transport | Audio handling | Typical bitrate |
|---|---|---|---|
| WebRTC | UDP based Media over SRTP Data over SCTP | Built-in via getUserMedia and MediaStreamTrack | Opus codec ~32 kbps target ~20 kbps average client Some servers often do stereo 32-128 kbps |
| WebSocket | TCP based | getUserMedia combined with WebAudio and PCM encoding and playout. WebCodecs not used typically | PCM codec (base64) ~512 kbps ~10x Opus |
| WebTransport | UDP based QUIC / HTTP-3 | Like WebSocket, but no head-of-line blocking challenge | Same approach as WebSocket |
Why these differences matter:
- WebRTC was built for real-time audio and video, which makes it a good, if not ideal, fit for talking to an LLM. It is a stable well known technology, available in every browser, and easy on the client side. That makes it the pragmatic default
- WebSocket puts the client fully in charge of audio. It is a heavy base64-PCM bitrate - roughly 10x Opus. Embedding audio as base64 in JSON instead of binary frames is pragmatism, not design. WebSocket also shows up backend to backend, between an audio provider like ElevenLabs and an application backend, on the hypothesis that TCP between data centers is more reliable and less loss-prone. This fits less in the edges of the network, where us mortals connect from
- WebTransport is nascent. Safari only added support in 2026. The approach will end up mirroring WebSocket but without head-of-line blocking issues. It is more of a concept than a solution at the moment
Here’s something to understand about WebRTC: it has always been focused and optimized at human-to-human conversations - 1:1 or groups. Since its inception it has been adopted to other domains such as live streaming and cloud gaming, and in a way, Voice AI is another such domain. What is missing for WebRTC here is a better fit to LLM behaviors. The assumption of human-to-human 1-1 conversation is close enough to begin with and then optimize for the non-human behavior of the second endpoint.
The beauty of it compared to other transport solutions is that the moment you need a conversation with virtual agents to grow to multiple human participants, WebRTC gets involved anyways - so you might as well start early, with that single participant.
The data channel in WebRTC is a building block worth calling out on its own. Today it acts as a control and event channel, carrying text and rarely, base64-encoded images - the simplest way to answer what am I looking at, which matters for smart glasses; the heavier alternative is decoding a video stream server-side and picking the latest frame. It is also a likely path for steering a response mid-turn, though we have not seen that in production.
Working on voice AI over WebRTC? Philipp Hancke and I teach exactly this in a private 2-hour technical workshop.
STT-LLM-TTS vs Speech-to-Speech: which voice loop?
Separate from transport, there are two competing models for the voice loop itself.
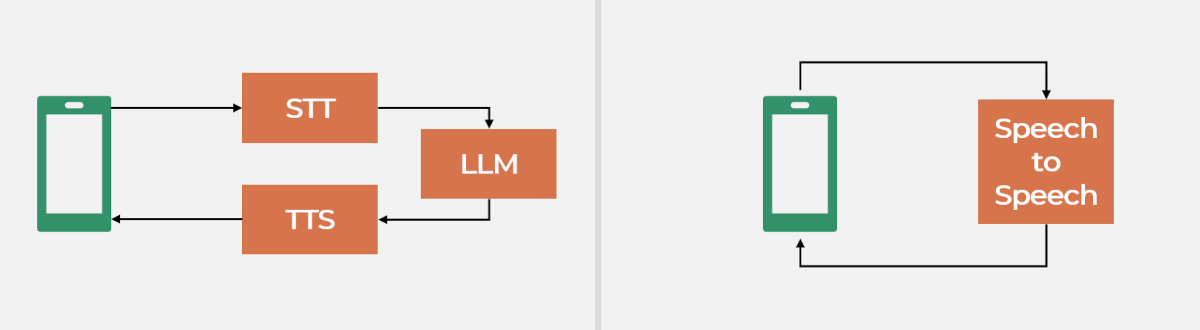
STT to LLM to TTS is the traditional pipeline, well understood, with swappable parts:
- A speech-to-text model like Whisper. The hard question is when to transcribe, since these models are trained on chunks of around 30 seconds. So voice activity detection and end-of-turn logic have to run before STT and trigger it. VAD can run on a server CPU with a package like Silero-VAD, which is more accurate than the WebRTC supplied VAD
- The LLM, on the inference backend. It gets a single blob of text, so one GPU can and should serve many sessions. The response is usually streamed so TTS can start before the LLM finishes
- A text-to-speech model, typically the latest and greatest open-weights option of the moment
Speech-to-Speech feeds encoded PCM, not Opus, straight to the model. The model can then use pitch and timing that transcription throws away. The downside is that it is more of a black box for WebRTC developers and harder to adapt as the underlying LLM advances.
📌 Here’s something important: inside STT, TTS, and Speech-to-Speech, the transport is almost never WebRTC and Opus. It is mostly WebSocket and uncompressed raw audio (L16). This is how things were years ago, before ChatGPT and LLMs; and this is how it is today.
How do OpenAI, LiveKit, Gemini and ElevenLabs use WebRTC for voice AI?
One of the long-standing virtues of WebRTC in the browser is visibility: chrome://webrtc-internals shows exactly how the stack behaves. Here is what it shows for the current players.
| Service | Edge transport | Notes |
|---|---|---|
| Google Gemini Live | Raw QUIC (native app) | Browser path done via third party vendors |
| OpenAI (Realtime) | WebRTC | REST-based signaling Events over the data channel Started on LiveKit, then built their own infrastructure |
| ElevenLabs | WebSocket / WebRTC | TURN misconfigured Stereo audio |
| LiveKit WebRTC | WebRTC with RED Ships turn detection plugin | No audio NACK seen, unlike Google Meet Uses the SFU infrastructure pattern |
The pattern across most deployments is fairly default: untuned WebRTC.
Vendors who came from the conferencing world keep shipping room-based APIs that renegotiate streams and think in a scope of a room. Voice AI is predominantly a 1:1 call, which was always the smaller WebRTC use-case.
WebRTC has been tuned for more than a decade for humans, who tolerate glitches far less than an LLM does. Moving past that default is the whole game.
Build vs buy

What we see across the industry is a pattern of buying into a WebRTC infrastructure for Voice AI transport.
Usually by going to Daily Pipecat and LiveKit Agents. Most production services pick one of these, with some mix-and-match components. Even the largest vendors out there such as OpenAI started on LiveKit before building their own WebRTC infrastructure.
What we’ve seen in WebRTC’s past is a pattern of the large players to opt for a cloud based WebRTC infrastructure and then switch to their own to control the whole pipeline. The allure of Pipecat and LiveKit Agents is their open source nature - they make that shift simpler, at least on paper. The actual shift is to a finely tuned WebRTC infrastructure that fits their Voice AI backend infrastructure and the use cases they are after.
Interestingly, Daily (and Pipecat if used with Daily’s transport) uses Twilio and/or Cloudflare for its own TURN infrastructure. That’s because running a large distributed TURN network is its own job - one with little vendor lock-in and little gratitude.
The build approach means rolling out your own WebRTC infrastructure technology stack and tuning it. We’ve seen some vendors take that route as well, though not as many. Here, Pion/Go seems to be the tried and true go-to solution - not LiveKit and not libWebRTC. Likely due to its Go heritage and the fact that what is needed is not an SFU as infrastructure but rather a small and focused WebRTC-LLM gateway - an entity without a specific name or identity that is likely to become an important part of Voice AI infrastructure everywhere.
How do you tune WebRTC for voice AI?

We’ve seen how WebRTC is used today for Voice AI. We have our reservations. It fits more into proof of concepts than actual production services.
As Voice AI services grow in popularity and scale, more time and energy will be focused on fine tuning them more - optimizing every part of their pipeline processing and with it - the WebRTC components. This is where great services will start diverging from the rest of the pack - a well tuned WebRTC implementation form-fitted to Voice AI is far better than a default WebRTC solution.
Here’s what we see coming:
- Signaling. Migrating away from the SFU model towards a WebRTC-LLM gateway. This reduces network hops, removes unnecessary signaling renegotiations and enables far better control and opportunities for optimizations. This is the approach OpenAI took when they rearchitected their realtime voice service away from LiveKit towards their own in-house solution
- Voice and codecs. From the client we see standard 32 kbps Opus, around 20 kbps on average. DTX should not be used with server-side VAD. From the server to the client, stereo should not be the default - it should be reserved only for use cases that need it. Encoding silence at a low bitrate, rather than constant bitrate, saves a lot of bytes over a turn-taking session. RED is nice to have. Audio NACK should be adopted at a higher priority. Noise suppression (Insertable Streams plus RNNoise) can run client- or server-side before VAD. And going through the well-tested WebRTC echo cancellation path keeps the agent from hearing its own voice echoed back
- Video. Still nascent. Today it is mostly avatar video sent to the user, synchronized with speech, usually H.264 with bitrate, frame rate, and resolution tuned to the use-case. Uploading user video has not taken off, but “what am I looking at” use case will matter for smart glasses
- WebRTC and LLM split. WebRTC is terminated on an endpoint close to the user, talking to the LLM in the inference backend. The split is mostly about scalability: expensive GPUs need to serve many sessions, while WebRTC is stateful and compute-oriented. The round-trip concerns do not vanish, they move into the data center. The OpenAI scale writeup documents exactly this LiveKit-to-own-stack transition
You can dig deeper into our Voice AI WebRTC best practices.
The metrics that matter

The one most looked at these days is latency and round trip time, focusing on the end-to-end approach of the user to LLM. Turn taking optimization, shaving milliseconds across the media pipeline, etc.
At the end of the day, the session should be smooth. Latency is only part of the headache that needs to be dealt with. Jitter, packet loss and other network behaviors need to be addressed and optimized. Sometimes, this may require changes in the infrastructure and location of servers and routes. Other times it will be about optimizations of the code and its behavior.
We serve humans talking to machines. The human side needs to be measured with human specific metrics - the same way we use today in WebRTC. That’s the standard getStats API we’ve been using for over a decade. Looking at bitrate, frame rate, round-trip time, packet loss, plus call-establishment time and time-to-open-datachannel - to name a few metrics.
Where the frontier is (and where to invest)

The honest map has open edges. These are the places the work is still being done:
- Faster connection times. Call-establishment time and datachannel-open time are the signals to watch, both via getStats. Concrete techniques to shorten them are still being developed
- Audio NACK. Unused in Voice AI today, standard in advanced conferencing. This enables an increased resiliency with little payment in the bitrate budget. An untapped lever
- Semantic turn-taking and steering. The move from VAD-silence to LLM-driven turn detection, and eventually to mid-turn steering, is where naturalness gets won
Who this is for
This is for two audiences converging on the same problem from opposite sides: WebRTC developers now being asked to support Voice AI, and Voice AI developers who need WebRTC, whether through LiveKit Agents and Pipecat or directly.
Building voice AI on WebRTC? Philipp Hancke and I run a private 2-hour technical workshop on exactly this.
Frequently asked questions
Most browser-based voice AI uses WebRTC because it is built for low-latency real-time audio. WebSockets are used by some services (notably ElevenLabs) and backend-to-backend, but at a much heavier bitrate (base64 PCM, roughly 10x Opus).
Natural conversation needs sub-second round trips. WebRTC is designed to prioritize low latency over guaranteed delivery, which is why it fits voice AI better than TCP-based transports.
No, not for a 1:1 person-to-bot session with server-side VAD. An SFU only earns its place when the conversation grows to multiple humans and bots.
Most production teams buy a framework (Daily/Pipecat, LiveKit). Building directly on Pion/Go has been tried but is less mature. OpenAI started on LiveKit before building its own, which makes sense at its scale.
Opus, targeting about 32 kbps and averaging around 20 kbps from the client. Speech-to-Speech models take raw PCM/G.711 rather than Opus.