
Learn about WebRTC LLM and its applications. Discover how this technology can improve real-time communication using conversational AI.
Talk about an SEO-rich title… anyways. When Philipp suggests something to write about I usually take note and write about it. So it is time for a teardown of last month’s demo by OpenAI - what place WebRTC takes there, how it affects the programmable video market of Video APIs. For the bigger picture of how this all runs under the hood, see WebRTC for Voice AI.
I’ve been dragged into this discussion before. In my monthly recorded conversation with Arin Sime, we talked about LLMs and WebRTC:
Time to break down the OpenAI demo that was shared last month and what role WebRTC and its ecosystem plays in it.
The OpenAI GPT-4o demo
Just to be on the same page, watch the demo below - it is short and to the point:
(for the full announcement demos video check out this link. You really should watch it all)
There were several interfaces shown (and not shown) in these demos:
- No text prompts. Everything was done in a conversational manner
- And by conversation I mean voice. The main interface was a person talking to ChatGPT through his phone app
- There were a few demos that included “vision”
- They were good and compelling, but they weren’t video per se
- It felt more like images being uploaded, applying OCR/image recognition on them or some such
- This can be clearly indicated when in the last demo on this, the person had to tell ChatGPT to use the latest image and not an older one - there are still a few polishes needed here and there
Besides the interface used, there were 3 important aspects mentioned, explained and shown:
- This was more than just speech to text or text to speech. It gave the impression that ChatGPT perceived and generated emotions. I dare say, the OpenAI team did above and beyond to show that on stage
- Humor. It seems humor and in general humans are now more understandable by ChatGPT
- Interruptions. This wasn’t a turn by turn prompting but rather a conversation. One where the person can interrupt in the middle to veer and change the conversation’s direction
Let's see why this is different from what we’ve seen so far, and what is needed to build such things.
Text be like…
ChatGPT started off as text prompting.
You write something in the prompt, and ChatGPT obligingly answers.
It does so with a nice “animation”, spewing the words out a few at a time. Is that due to how it works, or does it slow down the animation versus how it works? Who knows?
This gives a nice feel of a conversation - as if it is processing and thinking about what to answer, making up the sentences as it goes along (which to some extent it does).
This quaint prompting approach works well for text. A bit less for voice.
And now that ChatGPT added voice, things are getting trickier.
“Traditional” voice bots are like turn based games

Before all the LLM craze and ChatGPT, we had voice bots. The acronyms at the time were NLP and NLU (Natural Language Processing and Natural Language Understanding). The result was like a board game where each side has its turn - the customer and the machine.
The customer asks something. The bot replies. The customer says something more. Oh - now’s the bot’s turn to figure out what was said and respond.
In a way, it felt/feels like navigating the IVR menus via voice commands that are a bit more natural.
The turn by turn nature means there was always enough time.
You could wait until you heard silence from the user (known as endpointing). Then start your speech to text process. Then run the understanding piece to figure out intents. Then decide what to reply and turn it into text and from there to speech, preferably with punctuation, and then ship it back.
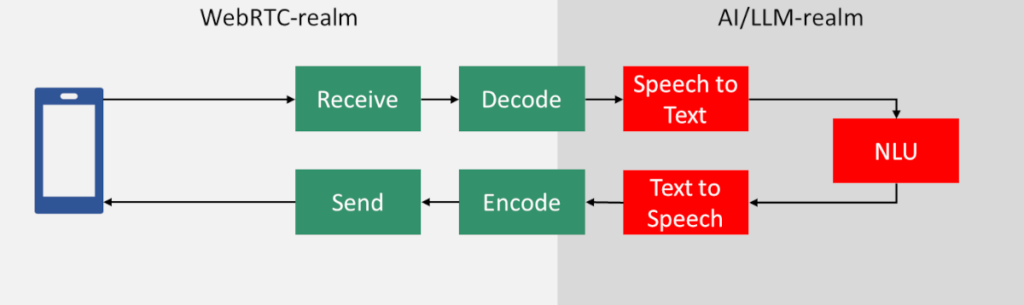
The pieces in red can easily be broken down into more logic blocks (and they usually are). For the purpose of discussing the real time nature of it all, I’ve “simplified” it into the basic STT-NLU-TTS
To build bots, we focused on each task one at a time. Trying to make that task work in the best way possible, and then move the output of that task to the next one in the pipeline.
If that takes a second or two - great!
But it isn’t what we want or need anymore. Turn based conversations are arduous and tiring.
Realtime LLMs are like… real-time games

Here are the 4 things that struck a chord with me when GPT-4o was introduced from the announcement itself:
- GPT-4o is faster (you need that one for something that is real-time)
- Future of collaboration - somehow, they hinted on working together and not only man to machine, whatever that means at this early stage
- Natural, feels like talking to another person and not a bot (which is again about switching from turn based to real-time)
- Easier, on the user. A lot due to the fact that it is natural
Then there was the fact that the person in the demo cuts GPT-4o short in mid-sentence and actually gets a response back without waiting until the end.
There’s more flexibility here as well. Less to learn about what needs to be said to “strike” specific intents.
Moving from turn based voice bots to real-time voice bots is no easy feat. It is also what’s in our future if we wish these bots to become commonplace.
See also: Voice LLM
Real life and conversational bots

The demo was quite compelling. In a way, jaw dropping.
There were a few things there that were either emphasized or skimmed through quickly that show off capabilities that if arrive in the product once it launches are going to make a huge difference in the industry.
Here are the ones that resonated with me
- Wired and not wireless. Why on earth would they do a wired demo from a mobile device? The excuse was network reception. Somehow, it makes more sense to just get an access point in the room, just below the low table and be done with it. Something there didn’t quite work for me - especially not for such an important demo (4.6M views in 2 months on the full session on YouTube)
- Background noise. Wired means they want a clean network. Likely for audio quality. Background noise can be just as bad for the health of an LLM (or a real conversation). These tools need to be tested rigorously in real time environments… with noise in them. And packet loss. And latency. Well… you go the hint
- Multiple voices. Two or more people sitting around the table, talking to GPT-4o. Each time someone else speaks. Does GPT need to know these are different people? That’s likely, especially if what we aim at is conversations that are natural for humans
- Interruptions. People talking over each other locally (the multiple voices scenario). A person interrupting GPT-4o while it runs inference or answers. Why not GPT-4o interrupting a rumbling human, trying to focus him?
- Tone of voice. Again, this one goes both ways. Understanding the tone of voice of humans. And then there’s the tone of voice GPT-4o needs to play. In the case of the demo, it was friendly and humorous. Is that the only tone we need? Likely not. Should tone be configurable? Predetermined? Dynamic based on context?
There are quite a few topics that still need to be addressed. OpenAI and ChatGPT have made huge strides and this is another big step. But it is far from the last one.
We will know more on how this plays out in real life once we get people using it and writing about their own experiences - outside of a controlled demo at a launch event.
Working on the WebRTC and LLM infrastructure

In our domain of communication platforms and infrastructure, there are a few notable vendors that are actively working on fusing WebRTC with LLMs. This definitely isn’t an exhaustive list. It includes:
- Those that made their intentions clear
- Had something interesting to say besides “we are looking at LLMs”
- And that I noticed (sorry - I can’t see everyone all the time)
They are taking slightly different approaches, which makes it all the more interesting.
Before we start, let's take the diagram from above of voicebots and rename the NLU piece into LLM, following marketing hype as it is today:
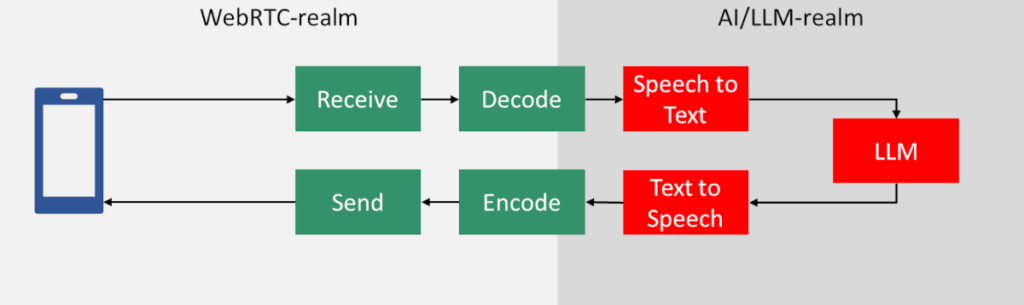
The main difference now is that LLM is like pure black magic: We throw corpuses of text into it, the more the merrier. We then sprinkle a bit of our own knowledge base and domain expertise. And voila! We expect it to work flawlessly.
Why? Because OpenAI makes it seem so easy to do…
Programmable Video and Video APIs doing LLM

In our domain of programmable video, what we see are vendors trying to figure out the connectors that make up the WebRTC-LLM pipeline and doing that at as low latency as possible.
Agora
Agora just published a nice post about the impact of latency on conversational AI.
The post covers two areas:
- The mobile device, where they tout their native SDK as being faster and with lower latency than the typical implementation
- The network, relying on their SD-RTN infrastructure for providing lower latency than others
In a way, they focus on the WebRTC-realm of the problem, ignoring (or at least not saying anything about) the AI/LLM-realm of the problem.
It should be said that this piece is important and critical in WebRTC no matter if you are using LLMs or just doing a plain meeting between mere humans.
Daily
Daily take their unique approach for LLM the same way they do for other areas. They offer a kind of a Prebuild solution. They bring in partners and integrations and optimize them for low latency.
In a recent post they discuss the creation of the fastest voice bot.
For Daily, WebRTC is the choice to go for since it is already real time in nature. Sprinkle on top of it some of the Daily infrastructure (for low latency). And add the new components that are not part of a typical WebRTC infrastructure. In this case, packing Deepgram’s STT and TTS along with Meta’s Llama 3.
The concept here is to place STT-LLM-TTS blocks together in the same container so that the message passing between them doesn't happen over a network or an external API. This reduces latencies further.
Go read it. They also have a nice table with the latency consumers along the whole pipeline in a more detailed breakdown than my diagrams here.
LiveKit
In January this year, LiveKit introduced the LiveKit Agents. Components used to build conversational AI applications. They haven’t spoken since about this on their blog, or about latency.
That said, it is known that OpenAI is using LiveKit for their conversational AI. So whatever worries OpenAI has about latencies are likely known to LiveKit…
LiveKit has been lucky to score such a high profile customer in this domain, giving it credibility in this space that is hard to achieve otherwise.
Twilio’s approach to LLMs

Twilio took a different route when it comes to LLM.
Ever since its acquisition of Segment, Twilio has been pivoting or diversifying. From communications and real time into personalization and storage. I’ve written about it somewhat when Twilio announced sunsetting Programmable Video.
This makes the announcement a few months back quite reasonable: Twilio AI Assistant
This solution, in developer preview, focuses on fusing the Segment data on a customer with the communication channel of Twilio’s CPaaS. There’s little here in the form of latency or real time conversations. That seems to be secondary for Twilio at the moment, but is also something they are likely now exploring as well due to OpenAI’s announcement of GPT-4o.
For Twilio? Memory and personalization is what is important about the LLM piece. And this is likely highly important to their customer base. How will other vendors without access to something like Segment are going to deal with it is yet to be seen.
Fixie anyone?

When you give Philipp Hancke to review an article, he has good tips. This time it meant I couldn’t make this one complete without talking about fixie.ai. For a company that raised $17M they don’t have much of a website.
Fixie is important because of 3 things:
- Justin Uberti, one of the founders of WebRTC, is a Co-founder and CTO there
- It relies on WebRTC (like many others)
- It does things a wee bit differently, and not just by being open source
Fixie is working on Ultravox, an open source platform that is meant to offer a speech-to-speech model. No more need for STT and TTS components. Or breaking these into smaller pieces yet.
From the website, it seems that their focus at the moment is modeling speech directly into LLM, avoiding the need to go through text to speech. The reasoning behind this approach is twofold:
- You don’t lose latency on going through the translation to text and from there into the LLM
- Voice has a lot more to it than just the spoken words. Having that information readily available in the LLM can be quite useful and powerful
The second part of it, of converting the result of the LLM back into speech, is not there yet.
Why is that interesting?
- Justin… who is where WebRTC is (well… maybe apart from his stint at Clubhouse)
- The idea of compressing multiple steps into one
- It was tried for transcoding video and failed, but that was years ago, and was done computationally. Here we’re skipping all this and using generative AI to solve that piece of the puzzle. We still don’t know how well it will work, but it does have merit
What’s next?

There are a lot more topics to cover around WebRTC and LLM. Rob Pickering looks at scaling these solutions for example. Or how do you deal with punctuations, pauses and other phenomena of human conversations.
With every step we make along this route, we find a few more challenges we need to crack and solve. We’re not there yet, but we definitely stumbled upon a route that seems really promising.
