My life is miserable. They say password is hell, but you know what? Social login is just as shitty.
A couple of years ago, I understood it was time to step up my security by having stronger passwords. The way to do that is to have random complex ones that are different to each website. To deal with that, I am using a great small app called KeePass, which has its own Android counterpart. To keep them both in sync I use Google Drive (Dropbox in the past).
Then came Open ID. And went. It seems that everybody wanted to be an Open ID provider, but most sites ignored it and didn't allow registration or logging in using Open ID.
This past year I've been adding less and less new accounts to my KeePass. Social networks are now the main means to register to a site – sometimes the only way. So there's no more passwords and user names to remember – just apps that gather dust around our social network accounts.
Today I have 46 "apps" approved on my Facebook account, 17 on LinkedIn, 37 on Google and another 39. Some of I actually use, some are duplicates and others are ghosts. Though each platform provides ways to manage them and revoke their access, show me a person who actually uses that feature.
Up until now it wasn't a problem – I somehow managed to deal with it. But it is getting harder each day. I wanted to comment on a GigaOm post. Since I haven't done that in a while, the site didn't remember me. This is the options it provided:
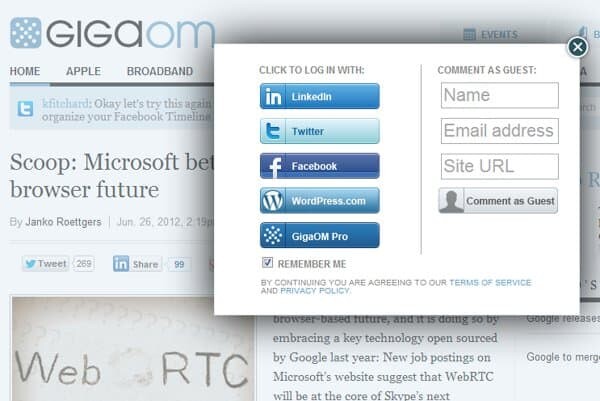
6 (!) different ways to sign in. Now, which one have I used in the past?
- Was it my long lost GigaOm Pro account?
- Maybe I used Facebook for this one
- Or was it Twitter? Not really sure…
- Might have been LinkedIn. I used it for "professional" settings
- Hell… why not use my WordPress one? I have that account somewhere
- Darn. Why not just submit it as a guest and be done with it?
And it isn't just GigaOm – it is everyone these days.
Sure. For commenting there is no harm in it. but what about services like GetSatisfaction? Where your context matters in the long run. But – you get there from different other web sites that use it. Guess what? I found out I have multiple accounts there – from different social networks I can see different parts of my discussions there.
Identity hell.
