To reach out to you.

I’ve been asked recently to write a few more on the topic of WebRTC basics – explaining how it works. This is one of these posts.
There’s been a recent frenzy around with the NY Times use of WebRTC. The fraud detection mechanism for the ads there used WebRTC to find local addresses and to determine if the user is real or a bot. Being a cat and mouse game over ad money means this will continue with every piece of arsenal both sides have at their disposal, and WebRTC plays an interesting role in it. The question was raised though – why does WebRTC needs the browser’s IP address to begin with? What does it use it for?
To answer, this question, we need to define first how the web normally operates (that is before WebRTC came to be).
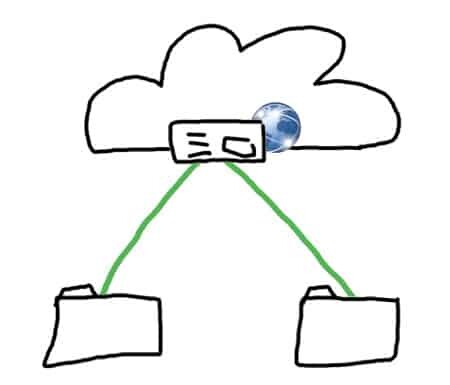
The illustration above explains it all. There’s a web server somewhere in the cloud. You reach it by knowing its IP address, but more often than not you reach it by knowing its domain name and obtaining its IP address from that domain name. The browser then goes on to send its requests to the server and all is good in the world.
Now, assume this is a social network of sorts, and one user wants to interact with another. The one and only way to achieve that with browsers is by having the web server proxy all of these messages – whatever is being sent from A to B is routed through the web server. This is true even if the web server has no real wish to store the messages or even know about them.
WebRTC allows working differently. It uses peer-to-peer technology, also known as P2P.
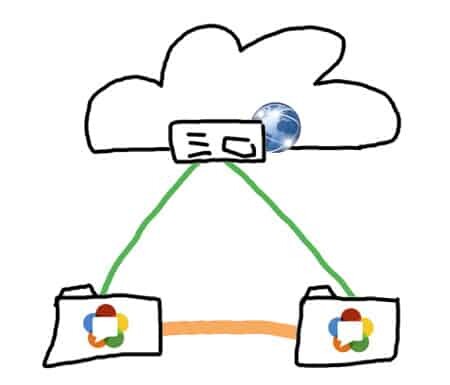
The illustration above is not new to VoIP developers, but it has a very important difference than how the web worked until the introduction of WebRTC. That line running directly between the two web browsers? That’s the first time that a web browser using HTML could communicate with another web browser directly without needing to go through a web server.
This is what makes all the difference in the need for IP addresses.
When you communicate with a web server, you browser is the one initiating the communication. It sends a request to the server, when will then respond through that same connection your browser creates. So there’s no real need for your browser to announce its IP address in any way. But when one browser needs to send messages to another – how can it do that without an IP address?
So IP addresses need to be exchanged between browsers. The web server in the illustration does pass messages between browsers. These messages contain SDP, which among other things contains IP addresses to use for the exchange of data directly between the browsers in the future.
Why do we need P2P? Can’t we just go through a server?
Sure we can go through a server. In fact, a lot of use cases will end up using a server for various needs – things like recording the session, multiparty or connecting to other networks necessitates the use of a server.
But in many cases you may want to skip that server part:
- Voice and video means lots of bandwidth. Placing the burden on the server means the service will end up costing more
- Voice and video means lost of CPU power. Placing the burden on the server means the service will end up costing more
- Routing voice and video through the server means latency and more chance of packet losses, which will degrade the media quality
- Privacy concerns, as when we send media through a server, it is privy to the information or at the very least to the fact that communication took place
So there are times when we want the media or our messages to go peer-to-peer and not through a server. And for that we can use WebRTC, but we need to exchange IP addresses across browsers to make it happen.
Now, this exchange may not always translate into two web browsers communicating directly – we may still end up relaying messages and media. If you want to learn more about it, then check out the introduction to NATs and Firewalls on webrtcHacks.
If you want to learn more about the challenges of group calling in WebRTC, then this free 5-part video course on Mastering Group Call Performance in WebRTC SFUs is exactly for you.
One of the points you make – not using P2P increases latency and chance for packet loss – is made others and often. But I feel this may not be case always. For example consider a service that has point of presence in many ISPs and these POPs are connected via optimal paths. Then it is more likely that P2P paths may have more latency or experience higher loss.
I am not sure that P2P paths maintain privacy either. After all, the service provider has access to call meta data since they have access to SDP and know the identity of the parties involved in the communication.
Even though the objective of your post, it is time we critically analyze the root causes IP address “leak”. WebRTC ensures that user permission is obtained when a server tries to access to mic and camera; but does not worry about Data connection. I don’t think there is a valid reason, except that it is an oversight. Furthermore, WebRTC has modified the original ICE protocol to Trickle ICE. Given Trickle ICE, it may be better to change the order of connectivity check procedure to try relay address (as some do), then try reflexive addresses and finally exchange local addresses only if that will work.
Granted that some NATs will not be able to hairpin a connection between two local hosts. To handle these cases, the browser and the app can ask permission from the user to exchange local addresses.
Aswath,
I can always rely on you on providing great feedback here – thanks 🙂
P2P is the basic possibility how to communicate via WebRTC. But if you need recording the session and some of additional control, the “star” topology is much more acceptable. So you need WebRTC server – we are working with Freeswitch or Kurento. Both are fine, thus both are used for different usecases …
And if your server sits in the GOOD cloud (Azure in our case) – the latency is no more the issue…
But your point with CPU consumpion is right. If you do some processing of streams in real time – you need a lot of CPU power. And it costs money.
Another trick is to pass the DMZ zones by large companies. P2P is not acceptable. We are using stunnel technology in the combination with WebRTC server. It works …