Are AI cameras in our future?

In last year’s AWS re:invent event, which took place end of November, Amazon unveiled an interesting product: AWS DeepLens
There’s decent information about this new device on Amazon’s own website but very little of anything else out there. I decided to put my own thoughts on “paper” here as well.
Interested in AI, vision and where it meets communications? There’s an extensive report I’ve written about the topic along with Chad Hart – check it out
What is AWS DeepLens?
AWS DeepLens is the combination of 3 components: hardware (camera + machine), software and cloud. These 3 come in a tight integration that I haven’t seen before in a device that is first and foremost targeting developers.
With DeepLens, you can handle inference of video (and probably audio) inputs in the camera itself, without shipping the captured media towards the cloud.
The hype words that go along with this device? Machine Vision (or Computer Vision), Deep Learning (or Machine Learning), Serverless, IoT, Edge Computing.
It is all these words and probably more, but it is also somewhat less. It is a first tentative step of what a camera module will look like 5 years from today.
I’d like to go over the hardware and software and see how they combine into a solution.
AWS DeepLens Hardware

AWS DeepLens hardware is essentially a camera that has been glued to an Intel NUC device:

Neither the camera nor the compute are on the higher end of the scale, which is just fine considering where we’re headed here – gazillion of low cost devices that can see.
The device itself was built in collaboration with Intel. As all chipset vendors, Intel is plunging into AI and deep learning as well. More on AWS+Intel vs Google later.
Here’s what’s in this package, based on the AWS blog post on DeepLens:
- 4 megapixel camera with the ability to capture 1080p video resolution
- Nothing is said about the frame rate in which this can run. I’d assume 30 fps
- The quality of this camera hasn’t been detailed either. In many cases, I’d say these devices will need to work in rather extreme lighting conditions
- 2D microphone array
- It is easy to understand why such a device needs a microphone, a 2D microphone array is very intriguing in this one
- This allows for better handling of things like directional sound and noise reduction algorithms to be used
- None of the deep learning samples provided by Amazon seem to make use of the microphone inputs. I hope these will come later as well
- Intel Atom X5 processor
- This one has 4 cores and 4 threads
- 8GB of memory and 16GB of storage – this is meant to run workloads and not store them for long periods of time
- Intel Gen9 graphics engine (here)
- If you are into numbers, then this does over 100 GFLOPS – quite capable for a “low end” device
- Remember that 1080p@30fps produces more than 62 million pixels a second to process, so we get ~1600 operations per pixel here
- You can squeeze out more “per pixel” by reducing frame rate or reducing resolution (both are probably done for most use cases)
- Like most Intel NUC devices, it has Wi-Fi, USB and micro HDMI ports. There’s also a micro SD port for additional memory based on the image above
The hardware tries to look somewhat polished, but it isn’t. Although this isn’t written anywhere, this is:
- The first version of what will be an iterative process for Amazon
- A reference design. Developers are expected to build the proof of concept with this, later shifting to their own form factor – I don’t see this specific device getting sold to end customers as a final product
In a way, this is just a more polished hardware version of Google’s computer vision kit. The real difference comes with the available tooling and workflow that Amazon baked into AWS DeepLens.
AWS DeepLens Software
The AWS DeepLens software is where things get really interesting.
Before we get there, we need to understand a bit how machine learning works. At its basic, machine learning is about giving a “machine” a large dataset, letting it learn the data in one way or another, and then when you introduce similar new data, it will be able to classify it.
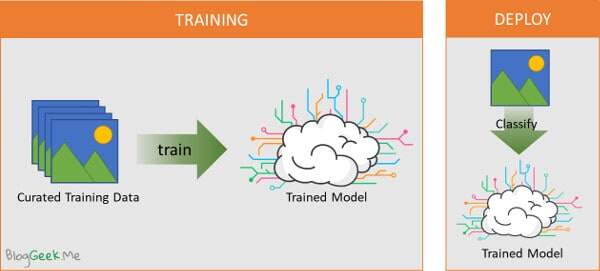
Dumbing the whole process and theory, at the end of the day, machine learning is built out of two main steps:
- TRAINING: You take a large set of data and use it for training purposes. You curate and classify it so the training process has something to check itself against. Then you pass the data through a process that ends up generating a trained model. This model is the algorithm we will be using later
- DEPLOY: When new data comes in (in our case, this will probably be an image or a video stream), we use our trained model to classify that data or even to run an algorithm on the data itself and modify it
With AWS DeepLens, the intent is to run the training in the AWS cloud (obviously), and then run the deployment step for real time classification directly on the AWS DeepLens device. This also means that we can run this while being disconnected from the cloud and from any other network.
How does all this come to play in AWS DeepLens software stack?
On device
On the device, AWS DeepLens runs two main packages:
- AWS Greengrass Core SDK – Greengrass enables running AWS Lambda functions directly on devices. If Lambda is called serverless, then Greengrass can truly run serverless
- Device optimized MXNet package – an Apache open source project for machine learning
Why MXNet and not TensorFlow?
- TensorFlow comes from Google, which makes it less preferable for Amazon, a direct cloud competitor. It is also preferable by Intel (see below)
- MXNet is considered faster and more optimized at the moment. It uses less memory and less CPU power to handle the same task
In the cloud
The main component here is the new Amazon SageMaker:
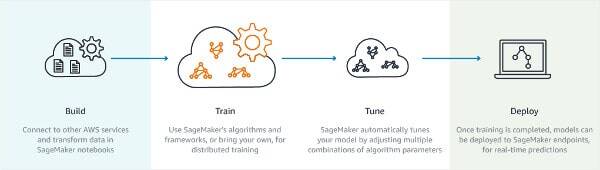
SageMarker takes the effort away from the management of training machine learning, streamlining the whole process. That last step in the process of Deploy takes place in this case directly on AWS DeepLens.
Besides SageMaker, when using DeepLens you will probably make use of Amazon S3 for storage, Amazon Lambda when running serverless in the cloud, as well as other AWS services. Amazon even suggests using AWS DeepLens along with the newly announced Amazon Rekognition Video service.
To top it all, Amazon has a few pre-trained models and sample projects, shortening the path from getting a hold of an AWS DeepLens device to seeing it in action.
AWS+Intel vs Google
So we’ve got AWS DeepLens. With its set of on-device and cloud software tools. Time to see what that means in the bigger picture.
I’d like to start with the main players in this story. Amazon, Intel and Google. Obviously, Google wasn’t part of the announcement. Its TensorFlow project was mentioned in various places and can be made to work with AWS DeepLens. But that’s about it.
Google is interesting here because it is THE company today that is synonymous to AI. And there’s the increasing rivalry between Amazon and Google that seems to be going on multiple fronts.
When Google came out with TensorFlow, it was with the intent of creating a baseline for artificial intelligence modeling that everyone will be using. It open sourced the code and let people play with it. That part succeeded nicely. TensorFlow is definitely one of the first projects developers would try to dabble with when it comes to machine learning. The problem with TensorFlow seems to be the amount of memory and CPU it requires for its computations compared to other frameworks. That is probably one of the main reasons why Amazon decided to place its own managed AI services on a different framework, ending up with MXNet which is said to be leaner with good scaling capabilities.
Google did one more thing though. It created its own special Tensor processing unit, calling it TPU. This is an ASIC type of a chip, designed specifically for high performance of machine learning calculations. In a research paper released by Google earlier last year, they show how their TPUs perform better than GPUs when it comes to TensorFlow machine learning work loads:
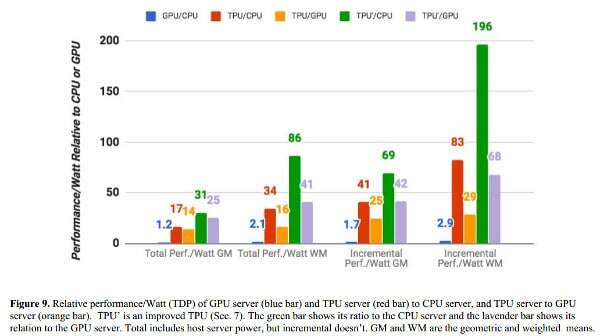
And if you’re wondering – you can get CLOUD TPU on the Google Cloud Platform, albait this is still in alpha stage.
This gives Google an advantage in hosting managed TensorFlow jobs, posing a threat to AWS when it comes to AI heavy applications (which is where we’re all headed anyway). So Amazon couldn’t really pick TensorFlow as its winning horse here.
Intel? They don’t sell TPUs at the moment. And like any other chip vendor, they are banking and investing heavily in AI. Which made working with AWS here on optimizing and working on end-to-end machine learning solutions for the internet of things in the form of AWS DeepLens an obvious choice.
Artificial Intelligence and Vision
These days, it seems that every possible action or task is being scrutinized to see if artificial intelligence can be used to improve it. Vision is no different. You can find it other computer vision or machine vision and it covers a broad set of capabilities and algorithms.
Roughly speaking, there are two types of use cases here:
- Classification – with classification, the images or video stream, is being analyzed to find certain objects or things. From being able to distinguish certain objects, through person and face detection, to face recognition to activities and intents recognition
- Modification – AWS DeepLens Artistic Style Transfer example is one such scenario. Another one is fixing the nagging direct eye contact problem in video calls (hint – you never really experience it today)
As with anything else in artificial intelligence and analytics, none of this is workable at the moment for a broad spectrum of classifications. You need to be very specific in what you are searching and aiming for, and this isn’t going to change in the near future.
On the other hand, there are many many cases where what you need is a camera to classify a very specific and narrow vision problem. The usual things include person detection for security cameras, counting people at an entrance to a store, etc. There are other areas you hear about today such as using drones for visual inspection of facilities and robots being more flexible in assembly lines.
We’re at a point where we already have billions of cameras out there. They are in our smartphones and are considered a commodity. These cameras and sensors are now headed into a lot of devices to power the IOT world and allow it to “see”. The AWS DeepLens is one such tool that just happened to package and streamline the whole process of machine vision.
Pricing
On the price side, the AWS DeepLens is far from a cheap product.
The baseline cost is of an AWS DeepLens camera? $249
But as with other connected devices, that’s only a small part of the story. The device is intended to be connected to the AWS cloud and there the real story (and costs) takes place.
The two leading cost centers after the device itself are going to be AWS Greengrass and Amazon SageMaker.
AWS Greegrass starts at $1.49 per year per device. Amazon SageMaker costs 20-25% on top of the usual AWS EC2 machine prices. To that, add the usual bandwidth and storage pricing of AWS, and higher prices for certain regions and discounts on large quantities.
It isn’t cheap.
This is a new service that is quite generic and is aimed at tinkerers. Startups looking to try out and experiment with new ideas. It is also the first iteration of Amazon with such an intriguing device.
I, for one, can’t wait to see where this is leading us.
3 Different Compute Models for Machine Vision
AWS DeepLens is one of 3 different compute models that I see in this space of machine vision.
Here are all 3 of them:
#1 – Cloud
In a cloud based model, the expectation is that the actual media is streamed towards the cloud:
- In real time
- Or at some future point in time
- When events occur; like motion being detected; or sound picked up on the mic
The data can be a video stream, or more often than not, it is just a set of captured images.
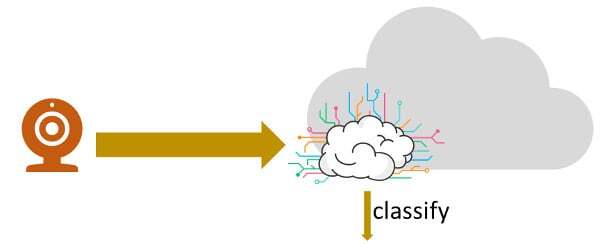
And that data gets classified in the cloud.
Here are two recent examples from a domain close to my heart – WebRTC.
At the last Kranky Geek event, Philipp Hancke shared how appear.in is trying to determine NSFW (Not Safe For Work):
The way this is done is by using Yahoo’s Open NSFW open source package. They had to resize images, send them to a server and there, using Python classify the image, determining if it is safe for work or not. Watch the video – it really is insightful at how to tackle such a project in the real world.
The other one comes from Chad Hart, who wrote a lengthy post about connecting WebRTC to TensorFlow for machine vision. The same technique was used – one of capturing still images from the stream and sending them towards a server for classification.
These approaches are nice, but they have their challenges:
- They are gravitating towards still images and not video streams at the moment. This relates to the costs and bandwidth involved in shipping and then analyzing such streams on a server. To give you an understanding of the costs – using Amazon Rekognition for one minute of video stream analysis costs $0.12. For a single minute. It is high, and the reason is that it really does require some powerful processing to achieve
- Sometimes, you really need to classify and make faster decisions. You can’t wait that extra 100’s of milliseconds or more for the classification to take place. Think augmented reality type of scenarios
- At least with WebRTC, I haven’t seen anyone who figured how to do this classification on the server side in real time for a video stream and not still images. Yet
#2 – In the Box
This alternative is what we have today in smartphones and probably in modern room based video conferencing devices.
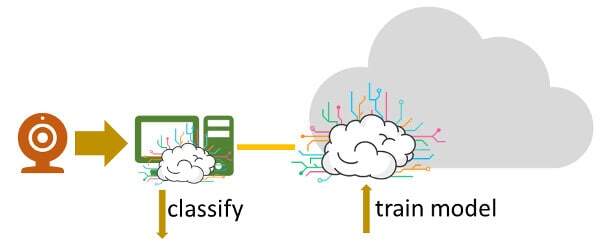
The camera is just the optics, but the heavy lifting takes place in the main processor that is doing other things as well. And since most modern CPUs today already have GPUs embedded as part of the SoC, and chip vendors are actively working on AI specific additions to chips (think Apple’s AI chip in the iPhone X or Google’s computational photography packed into the Pixel X phones).
The underlying concept here is that the camera is always tethered or embedded in a device that is powerful enough to handle the machine learning algorithms necessary.
They aren’t part of the camera but rather the camera is part of the device.
This works rather well, but you end up with a pricy device which doesn’t always make sense. Remember that our purpose here is to aim at having a larger number of camera sensors deployed and having an expensive computing device attached to it won’t make sense for many of the use cases.
#3 – In the Camera
This is the AWS DeepLens model.
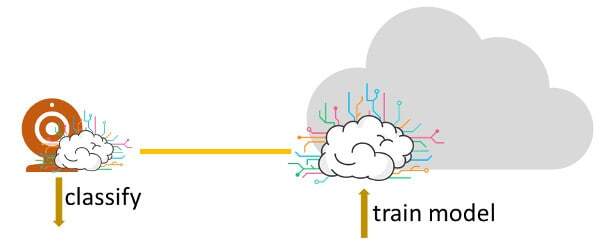
The computing power needed to run the classification algorithms is made part of the camera instead of taking place on another CPU.
We’re talking about $249 right now, but assuming this approach becomes popular, prices should go down. I can easily see such devices retailing at $49 on the low end in 2-3 technology cycles (5 years or so). And when that happens, the power developers will have over what use cases can be created are endless.
Think about a home surveillance system that costs below $1,000 to purchase and install. It is smart enough to have a lot less false positives in alerting its users. AND can be upgraded in its classification as time goes by. There can be a service put in place behind it with a monthly fee that includes such things. You can add face detection and classification of certain people – alerting you when the kids come home or leave for example. Ignoring a stray cat that came into view of the camera. And this system is independent of an external network to run on a regular basis. You can update it when an external network is connected, but other than that, it can live “offline” quite nicely.
No Winning Model
Yet.
All of the 3 models have their place in the world today. Amazon just made it a lot easier to get us to that third alternative of “in the camera”.
IoT and the Cloud
Edge computing. Fog computing. Cloud computing. You hear these words thrown in the air when talking about the billions of devices that will comprise the internet of things.
For IoT to scale, there are a few main computing concepts that will need to be decided sooner rather than later:
- Decentralized – with so many devices, IoT services won’t be able to be centralized. It won’t be around scale out of servers to meet the demands, but rather on the edges becoming smarter – doing at least part of the necessary analysis. Which is why the concept of AWS DeepLens is so compelling
- On net and off net – IoT services need to be able to operate without being connected to the cloud at all times. Think of an autonomous car that needs to be connected to the cloud at all times – a no go for me
- Secured – it seems like the last thing people care about in IoT at the moment is security. The many data breaches and the ease at which devices can be hijacked point that out all too clearly. Something needs to be done there and it can’t be on the individual developer/company level. It needs to take place a lot earlier in the “food chain”
I was reading The Meridian Ascent recently. A science fiction book in a long series. There’s a large AI machine there called Big John which sifts through the world’s digital data:
“The most impressive thing about Big John was that nobody comprehended exactly how it worked. The scientists who had designed the core network of processors understood the fundamentals: feed sufficient information to uniquely identify a target, and then allow Big John to scan all known information – financial transactions, medical records, jobs, photographs, DNA, fingerprints, known associates, acquaintances, and so on.
But that’s where things shifted into another realm. Using the vast network of processors at its disposal, Big John began sifting external information through its nodes, allowing individual neurons to apply weight to data that had no apparent relation to the target, each node making its own relevance and correlation calculations.”
I’ve emphasized that sentence. To me, this shows the view of the same IoT network looking at it from a cloud perspective. There, the individual sensors and nodes need to be smart enough to make their own decisions and take their own actions.
–
All these words for a device that will only be launched April 2018…
We’re not there yet when it comes to IoT and the cloud, but developers are working on getting the pieces of the puzzle in place.
Interested in AI, vision and where it meets communications? There’s an extensive report I’ve written about the topic along with Chad Hart – check it out
not worth.Easily you can buy decent laptop to do this job. With not just python but deeplearning 4j based code.
Great article. I wrote a medium post talking about other deep learning enabled vision developer kit. Check it out and let me know what you think.
https://medium.com/datadriveninvestor/iot-smart-camera-landscape-942442f88c8
Connecting cannabis, blockchain and AI. I guess I am old…
Thanks for sharing this wonderful articles.
Please visit this sites for more information:- https://recro.io/blog/aws-deeplens-developers-future-ai-cameras-vision/