
Small, Medium, Big or Extra Large? How do you like your WebRTC Media Server (SFU)?
I just checked AWS. If I had to build the most bad-ass, biggest, meanest, scalest, siziest server for WebRTC. One that can handle gazillions of sessions, I’d go for this one:
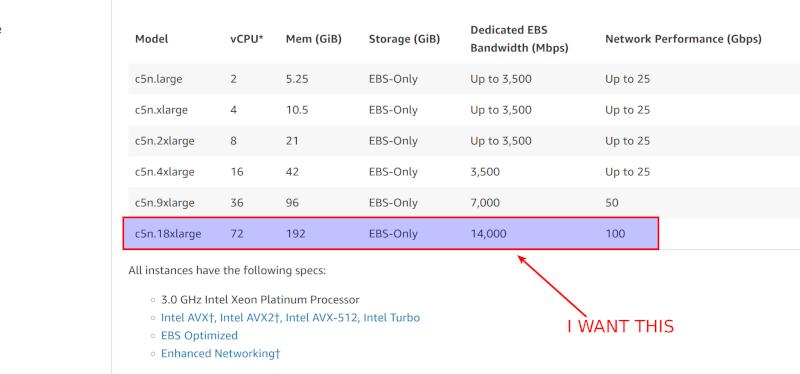
A machine to drool over… Should buy such a toy to write my articles on.
Or should I go for the biggest machine out there?
While this question can be asked for all types of WebRTC servers, I'd like to look here at WebRTC media servers, and more specifically, at SFUs.
I did a round-up of some of the people who develop these SFUs. And guess what? None of them is ordering the XL machine.
They go for a Medium or Medium Well. Or should I say Medium Large?
If you want to learn more about the challenges of group calling in WebRTC, then this free 5-part video course on Mastering Group Call Performance in WebRTC SFUs is exactly for you.
Anyways - here are a few things to think about when picking a machine for your SFU:
Going BIG on your SFU Media Server

As big as they come that’s how big you wanna take them.
We called it scale up in the past. Taking the same monolith application and put it on a bigger machine to get more juice out of it.
It’s not all bad, and there are good reasons to go that route with a media server:
Managing less machines

If one big machine does the work of 10 smaller machines, then all in all, you’ll need 1/10 the number of machines to handle the same workload.
In many ways, scaling is non-linear. To get to linear scaling, you’ll need to put a lot of effort. Different bits and pieces of your architecture will start breaking once you scale too much. In this sense, having less machines to manage means less scaling headaches as well.
Having bigger rooms

Group calling is what we’re after with media servers. Not always, but mostly.
Getting 4 people in a room is easy. 20? Harder. 500? Doable.
The bigger the rooms, the more you’ll need to start addressing it with your architecture and scale out strategies.
If you take smaller machines, say ones that can handle up to 100 concurrent users, then getting any group meeting to 100 participants or more is going to be quite a headache - especially if the alternative is just to use a bigger machine spec.
The bigger the rooms you want, the bigger the machines you’ll aim for (up to a point - if you want to cater for 100+ users in a room, I’d aim for other scaling metrics and factors than just enlarging the machines).
Less fragmentation

Similar to how you fit chunks of memory allocations into physical memory, fitting group sessions into media servers, and maybe even cascading them across machines will end up with fragmentation headaches for you.
Let’s say some of your meetings are really large and most are pretty smallish. But you don’t really know in advance which is which. What would be the best approach of starting to fit new rooms into existing media servers? This isn’t a simple question to answer, and it gets harder the smaller the machines are.
Simpler architecture (=no cascading)

If you are setting up the media server for a specific need, say catering for the needs of a hospital, then the size is known in advance - there’s a given number of hospital beds and they aren’t going to expand exponentially over night. The size of the workforce (doctors and nurses) is also known. And these numbers aren’t too big. In such a case, aiming for a large machine, with an additional one acting as active/passive server for high availability will be rather easy.
Aiming for smaller machines might get you faster to the need to scale out in your architecture. And scaling out has its own headaches and management costs.
Simpler
Bigger machines are going to be simpler in many ways.
Going small on your SFU

This is something I haven’t thought about as an alternative - at least not until a few years ago when I was helping a client in picking a media server for his cloud based service. One of the parameters that interested him was how small was considered too small by each media server vendor - trying to understand the overhead of a single media server process/machine/application.
I asked, and got good answers. I since decided to always look at this angle as well with the projects I handle. Here’s where smaller is better for WebRTC media servers:
Easier to upgrade

I dealt with upgrading WebRTC media servers in the past.
There are two things you need to remember and understand:
- WebRTC moves fast (and breaks things while doing so)
- You’ll need to update your backend rather frequently, including your media servers
The most common approach to upgrades these days is to drain media servers - when wanting to upgrade, block new sessions from going into some of the media servers, and once the sessions the are already handling are closed, kill and upgrade that media server. If it takes too long - just kill the sessions.
Smaller machines make it easier to drain them as they hold less sessions in them to begin with.
Having more machines also means you can mark more on them in parallel for draining without breaking the bank.
Blast radius of crashes

This is what started me on this article to begin with.
I took the time to watch Werner Vogels’s keynote from AWS re:Invent which took place November 2018. In it, he explains what got AWS on the route to build their own databases instead of using Oracle, and why cloud has different requirements and characteristics.
Here’s what Werner Vogels said:
With blast radius we mean that if a failure happens, and remember: everything fails all the time. Whether this is hardware or networking or transformers or your code. Things fail. And what you want to achieve is that you minimize the impact of such a failure on your customers.
Basically, if something fails, the minimum set of customers should be affected, if that’s the case.
Everything fails all the time.
And we do want to minimize who’s affected by such failures.
The more media servers we have (because they are smaller), the less customers will be affected if one of these servers fail. Why? Because our blast radius will be smaller.
CPU utilization

Here’s something about most modern media servers you might not have known - they don’t eat up CPU. Well… they do, but less than they used to a decade ago.
In the past, media servers were focused on mixing media - the industry was rallied around the MCU concept. This means that all video and audio content had to be decoded and re-encoded at least once. These days, it is a lot more common for vendors to be using a routing model for media - in the form of SFUs. With it, media gets routed around but never decoded or encoded.
If you want to learn more about the challenges of group calling in WebRTC, then this free 5-part video course on Mastering Group Call Performance in WebRTC SFUs is exactly for you.
In an SFU, network I/O and even memory gets far more utilized than the CPU itself. When vendors go for bigger machines, they end up using less of the CPU of the machines, which translates into wasted resources (and you are paying for that waste).
At times, cloud vendors throttle network traffic, putting a limit at the number of packets you can send or receive from your cloud servers, which again ends up as putting a limit to how much you can push through your servers. Again, causing you to go for bigger machines but finding it hard to get them fully utilized.
Smaller machines translates into better CPU utilization for your SFU in most cases.
Number of Cores/CPUs and Your SFU’s Architecture
Big or small, there’s another thing you’ll need to give your thought to - and that’s the architecture of the media server itself.
Media servers contain two main components (at least for an SFU):
- Control/signaling
- Media routing
Sometimes, they are coupled together, other times, they are split between threads or even processes.
In general, there are 3 types of architectures that SFUs take:
- Have a single process handle both control and media; doing it in a multithreaded mode
- Have separate processes that can scale out, running each on its own machine or thread
- Decoupling control and media and having both of them scale out independently of each other
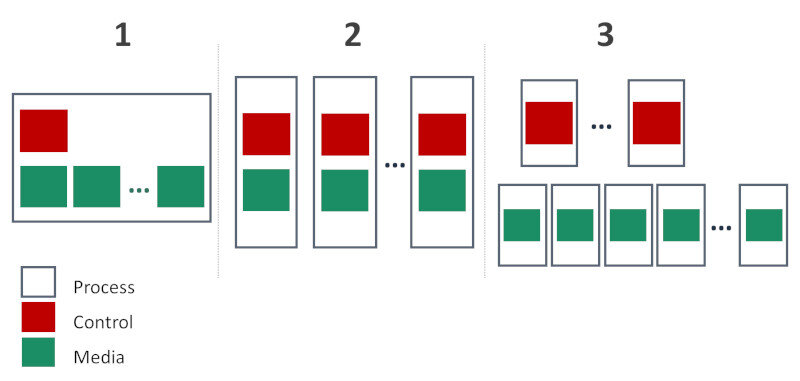
Me? I like the third alternative for large scale deployments. Especially when each process there is also running a single thread (I don’t really like multithreaded architectures and prefer shying away from them if possible).
That said, that third option isn’t always the solution I suggest to clients. It all depends on the use case and requirements.
In any case, you do need to give some thought to this as well when you pick a machine size - in almost all cases, you’ll be used a multi-core multi-threaded machine anyway, so better make the most of it.
How Do You Like Your SFU?
If you are interested in scaling of WebRTC, then check out my ebook on best practices of WebRTC scaling.
If you want to learn more about the challenges of group calling in WebRTC, then this free 5-part video course on Mastering Group Call Performance in WebRTC SFUs is exactly for you.
