
Lip synchronization is a solved problem in WebRTC. That’s at least the case in the naive 1:1 sessions. The challenges start to amount once you hit multiparty architectures or when audio and video get generated/rendered separately.
Let’s dive into the world of lip synchronization, understand how it is implemented in WebRTC and in which use cases we need to deal with the headaches it brings with it.
Table of contents
Connecting audio and video = lip synchronization
Discover the fascinating world of lip synchronization technology and its impact on WebRTC applications.

When you watch a movie or any video clip for that matter on your device – be it a PC display, tablet, smartphone or television – the audio and video that gets played back at you gets lip synced. There’s no “combination” of audio and video. These are two separate data sets / files / streams that are associated with one another in a synchronized fashion.
When you play out an mp4 file for example, it is actually a container file of multiple media streams. Each decoded and played out independently, synchronized again by timing the playout.
This was a decision made long ago that enables more flexibility in encoding technologies – you can use different codecs for the audio and the video of the content, based on your needs and the type of content you have. It also makes more sense since the codecs and technologies for compression audio and video are quite different from one another.
The RTP/RTCP solution to lip synchronization

When we’re dealing with WebRTC, we’re using SRTP as the protocol to send our media. SRTP is just the secure variant of RTP which is what I want to focus on here.
RTP is used to send media over the internet. RTCP acts as the control protocol for RTP and is tightly coupled with it.
The solution used for lip synchronization of RTP and RTCP was to rely on timestamps. To make sure we’re all confused though, the smart folks who conjured this solution up, decided to go with different types of timestamps and frequencies (it likely made them feel smart, though there’s probably a real reason I am not aware of that at least made sense at some point in the past).
We’re going to dive together into the charming world of RTP and NTP timestamps and see how together, we can lip sync audio and video in WebRTC.
RTP timestamp

RTP timestamp is like using “position: relative;” in CSS. We cannot use it to discern the absolute time a packet was sent (and we do not know the receiver’s clock in relation to ours).
What we can do with it, is discern the time that has passed between one RTP timestamp to another.

The slide above is from my Low-level WebRTC protocols course in the RTP lesson. Whenever we send a packet of media over the internet in WebRTC, the RTP header for that packet (be it audio or video) has a timestamp field. This field has 32 bits of data in it (which means it can’t be absolute in a meaningful way – not enough bits).
WebRTC picks the starting point for the RTP timestamps randomly, and from there it increases the value based on the frequency of the codec. Why the frequency of the codec and not something saner like “milliseconds” or similar? Because.
For audio, we increment the RTP timestamp by 48,000 every second for the Opus voice codec. For video, we increment it by 90,000 every second.
The headache we’re left dealing with here?
- Audio and video streams have different starting points in RTP timestamps
- Their corresponding RTP timestamps move forward at a totally different pace
NTP timestamp

We said RTP timestamp is relative? Then NTP timestamp is like using “position: absolute;” in CSS. It gives us the wallclock time. It is 64 bits of data, which means we don’t want to send it as much over the network.
Oh, and it covers 1900-2036 after which it wraps around (expect a few minor bugs a decade from now because of this). This is slightly different from the more common Unix 1970 startpoint timestamp.

The slide above is from my Higher-level WebRTC protocols course in the Inside RTCP lesson.
You can see that when an RTCP SR block is sent over the network (let’s assume once every 5 seconds), then we get to learn about the NTP timestamp of the sender, as well as the RTP timestamp associated with it.
In a way,we can “sync” between any given RTP timestamp we bump into with the NTP/RTP timestamp pair we receive for that stream in a RTCP SR.
What are we going to use this for?
- Once we see RTCP SR blocks for BOTH audio and video channels, we can understand the synchronization needed
- Since this is sent every few seconds, we can always resync and overcome packet losses as well as clock drifts
Calculating absolute time for lip synchronization in WebRTC

Let’s sum this part up:
- We’ve got RTP timestamps on every packet we receive
- Every few seconds, we receive RTCP SR blocks with NTP+RTP timestamps. These can be used to calculate the absolute time for any RTP timestamp received
- Since we know the absolute time for the audio and video packets based on the above, we can now synchronize their playback accordingly
Easy peasy. Until it isn’t.
👉 RTP, RTCP and other protocols are covered in our WebRTC Protocols courses. If you want to dig deeper into WebRTC or just to upskill yourself, check out webrtccourse.com
When lip synchronization breaks in WebRTC

RTP/RTCP gives us the mechanism to maintain lip synchronization. And WebRTC already makes use of it. So why and how can WebRTC lose lip synchronization?
There are three main reasons for this to happen:
- The data used for lip synchronization is incorrect to begin with
- Network fluctuations are too bad, causing WebRTC to decide not to lip sync
- Device conditions and use case make lip synchronization impossible or undesirable
I’d like to tackle that from the perspective of the use cases. There are a few that are more prone than others to lip synchronization issues in WebRTC.
Group video conferences

In group video conferencing there are no lip synchronization issues. At least not if you design and develop it properly and make sure that you either use the SFU model or the MCU model.
Some implementations decide to decouple voice and video streams, handling them separately and in different architectural solutions:
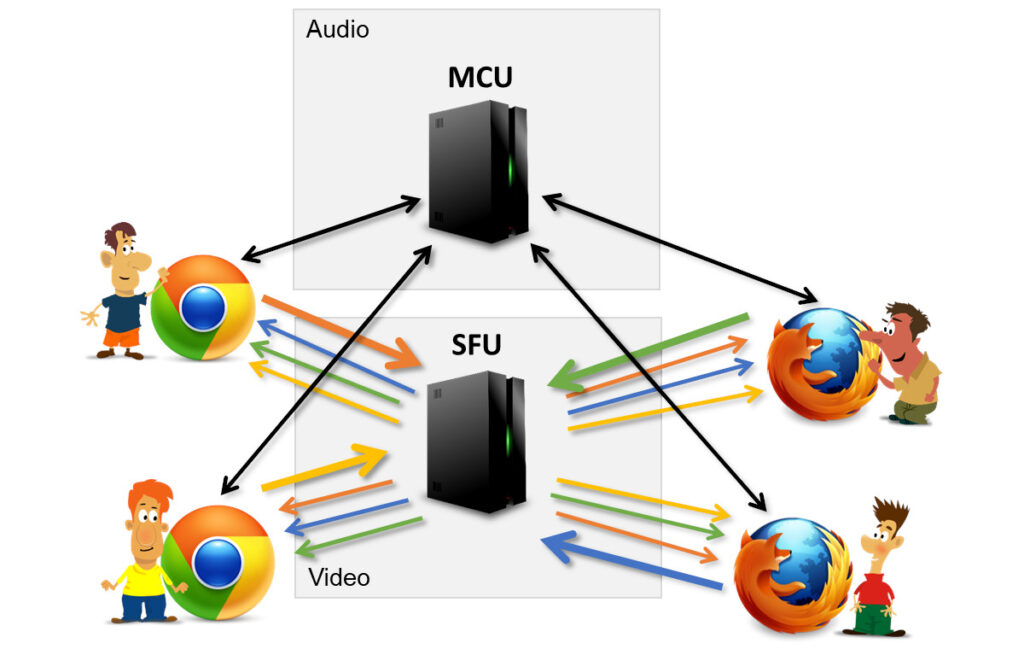
The diagram above shows what that means. Take a voice conferencing vendor that decided to add video capabilities:
- Voice conferencing traditionally was done using mixing audio streams (using an MCU)
- Now that the product needs to introduce video, there’s a decision to be made on how to achieve that:
- Add video streams to the MCU, mixing them. This is quite expensive to scale, and isn’t considered modern these days
- Use an SFU, and shift all audio traffic to an SFU as well. Great, but requires a complete replacement of all the media infrastructure they have. Risky, time consuming, expensive and no fun at all
- Use an SFU in parallel to the MCU. Have the audio continue the way it was up until today, and do the video part on a separate media server altogether
- The shortest path to video in this case is the 3rd one – splitting audio and video processing from one another, which causes immediate desynchronization
- You can’t lip synchronize the single incoming mixed audio stream with the multiple incoming video streams
In such cases, I often hear the explanation of “this is quite synchronized. It only loses sync when the network is poor”. Well… when the network is poor is when users complain. And adding this to their list of complaints won’t help. Especially if you want to be on par with the competition.
👉 What to do in this case? Go all in for SFU or all in for MCU – at least when it comes to the avoidance of splitting the audio and video processing paths.
Cloud rendering

The other big architectural headache for lip synchronization is cloud rendering. This is when the actual audio and/or video gets rendered and not acquired from a camera/microphone on some browser or mobile device.
In cloud gaming, for example, a game gets played, processed and rendered on a server in the cloud. Since this isn’t done in the web browser, the WebRTC stack used there needs to be aware of the exact timing of the audio and video frames – prior to them being encoded. This information should then be translated to the NTP+RTP timestamps that WebRTC needs. Not too hard, but just another headache to deal with.
For many cases of cloud gaming, we might even prioritize latency over lip synchronization, playing whatever we have when we get it as much as possible over having audio (or video) wait up for the other media type. That’s because in cloud games, a few milliseconds can be the difference between winning and game over.
When we’re dealing with our brave new world of conversational AI, now powered by LLM and WebRTC, then the video will usually follow the rendering of the audio, and might be done on a totally different machine. At the very least, it will occur using a different set of processes and algorithms.
👉 Here, it is critical to understand and figure out how to handle the NTP and RTP timestamps to get proper lip synchronization.
Latency and peripherals (and their effect on lip synchronization)

Something I learned a bit later in my life when dealing with video conferencing is that the devices you use (the peripherals) have their own built in latency.
- Displays? They might easily buffer a frame or two before showing it to the user – that can add 50 or more milliseconds easily.
- Cameras? They can be slow… old USB connectors were slower than the video frames captured by cameras in HD. Cameras used to compress the video to MJPEG, send it over USB and have the PC decode it before… encoding it again.
- Microphone and speakers? Again, lag. Especially if you’re using bluetooth devices. Gamers go to lengths to use connected headsets or low latency wireless headsets for this reason.
The sad thing here is that there’s NOTHING you can do about it. Remember that this is the user’s display or headset we’re talking about – you can’t tell them to buy something else.
On top of this, you have software device drivers that do noise reduction on the audio or add silly hats on the video (or replace the video altogether). These take their own sweet time to process the data and to add their own inherent latency into the whole media pipeline.
Device drivers on the operating system level should take care of this lag and this need to be factored into your lip synchronization logic – otherwise, you are bound to get issues here.
Got lip synchronization issues in your WebRTC application?

Lip synchronization is one of these nasty things that can negatively impact the perception of media quality in WebRTC applications. Solving it requires reviewing the architecture, sniffing the network, and playing around with the code to figure out the root cause prior to doing any actual fixing.
I’ve assisted a few clients in this area over the years, trying together to figure out what went wrong and working out suitable solutions around this.
Just to clarify a bit about the meaning of "NTP" here, according to RFC 3550:
An implementation is not required to run the Network Time Protocol in
order to use RTP. Other time sources, or none at all, may be used.
This means that you SHOULD NOT expect synchronized data in the NTP field, but just a consistent clock among media coming from the same source.
Said that, most implementations rely on the NTP local agent and often have NTP synchronized data in the SR, hence the assumption is mostly valid but not mandated by the RFC.
Thanks Alessandro!
That is correct. I wouldn’t expect to use NTP time as a synchronized global wall clock, but rather just to be able to synchronize the streams coming from that same source/device. Anything more is an assumption that might come bite you in the future.