
I hope this will clear up some of the confusion around WebRTC flows: WebRTC media flows.
I guess this is one of the main reasons why I started with my new project of an Advanced WebRTC Architecture Course. In too many conversations I've had recently it seemed like people didn't know exactly what happens with that WebRTC magic - what bits go where. While you can probably find that out by reading the specifications and the explanations around the WebRTC APIs or how ICE works, they all fail to consider the real use cases - the ones requiring media engines to be deployed.
So here we go.
In this article, I'll be showing some of these flows. I made them part of the course - a whole lesson. If you are interested in learning more - then make sure to enroll to the course.
#1 - Basic P2P Call
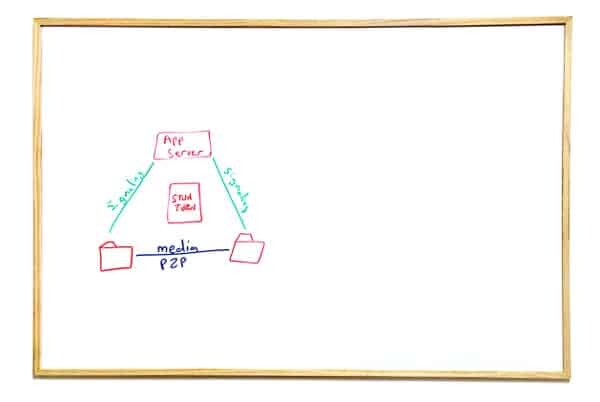
We will start off with the basics and build on that as we move along.
Our entities will be colored in red. Signaling flows in green and media flows in blue.
What you see above is the classic explanation of WebRTC. Our entities:
- Two browsers, connected to an application server
- The application server is a simple web server that is used to "connect" both browsers. It can be something like the Facebook website, an ecommerce site, your heatlhcare provider, etc.
- Our STUN and TURN server (yes. You don't need two separate servers. They almost always come as a single server/process). And we're not using it in this case, but we will in the next scenarios
What we have here is the classic VoIP (or WebRTC?) triangle. Signaling flows vertically towards the server but media flows directly across the browsers.
BTW - there's some signaling going off from the browsers towards the STUN/TURN server for practically all types of scenarios. This is used to find the public IP address of the browsers at the very least. And almost always, we don't draw this relationship (until you really need to fix a big, STUN seems obvious and too simple to even mention).
Summing this one up: nothing to write home about.
Moving on...
#2 - Basic Relay Call
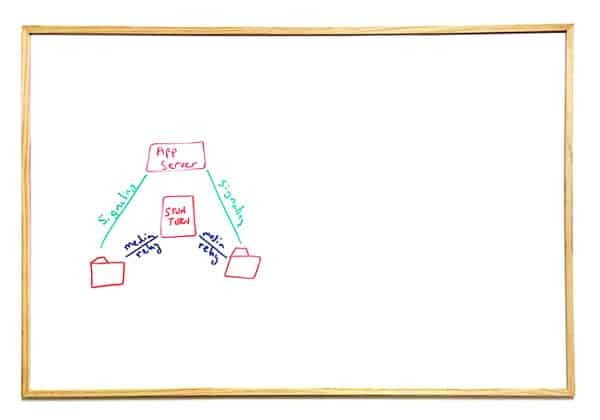
This is probably the main drawing you'll see when ICE and TURN get explained.
In essence, the browsers couldn't (or weren't allowed) to reach each other directly with their media, so a third party needs to facilitate that for them and route the media. This is exactly why we use TURN servers in WebRTC (and other VoIP protocols).
This means that WebRTC isn't necessarily P2P and P2P can't be enforced - it is just a best effort thing.
So far so go. But somewhat boring and expected.
Let's start looking at more interesting scenarios. Ones where we need a media server to handle the media:
#3 - WebRTC Media Server Direct Call, Centralized Signaling
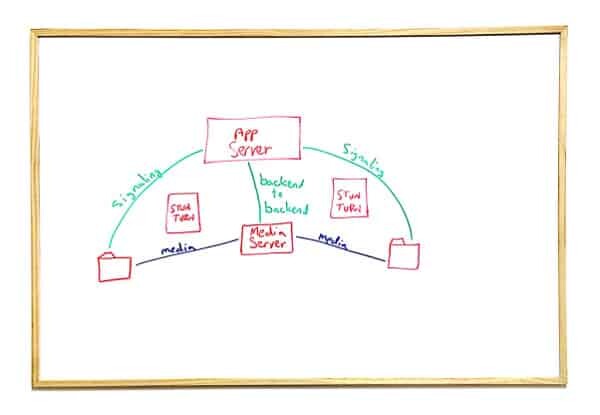
Now things start to become interesting.
We've added a new entity into the mix - a media server. It can be used to record the calls, manage multiparty scenarios, gateway to other networks, do some other processing on the media - whatever you fancy.
To make things simple, we've dropped the relay via TURN. We will get to it in a moment, but for now - bear with me please.
Media
The media now needs to flow through the media server. This may look like the previous drawing, where the media was routed through the TURN server - but it isn't.
Where the TURN server relays the media without looking at it - and without being able to look at it (it is encrypted end-to-end); the Media Server acts as a termination point for the media and the WebRTC session itself. What we really see here is two separate WebRTC sessions - one from the browser on the left to the media server, and a second one from the media server to the browser on the right. This one is important to understand - since these are two separate WebRTC sessions - you need to think and treat them separately as well.
Another important note to make about media servers is that putting them on a public IP isn't enough - you will still need a TURN server.
Signaling
On the signaling front, most assume that signaling continues as it always have. In which case, the media server needs to be controlled in some manner, presumably using a backend-to-backend signaling with the application server.
This is a great approach that keeps things simple with a single source of truth in the system, but it doesn't always happen.
Why? Because we have APIs everywhere. Including in media servers. And these APIs are sometimes used (and even abused) by clients running browsers.
Which leads us to our next scenario:
#4 - WebRTC Media Server Direct Call, Split Signaling
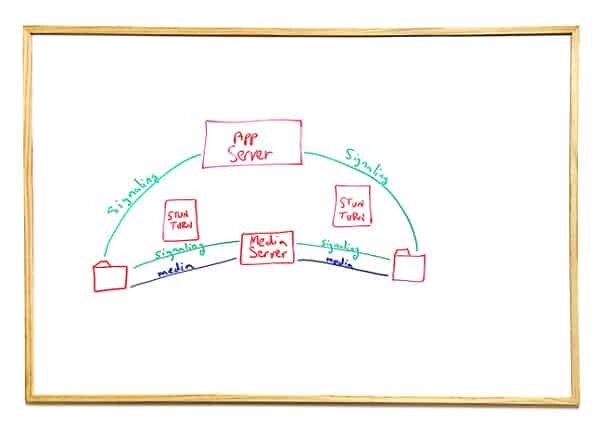
This scenario is what we usually get to when we add a media server into the mix.
Signaling will most often than not be done between the browser and the media server while at the same time we will have signaling between the browser and the application server.
This is easier to develop and start running, but comes with a few drawbacks:
- Authorization now needs to take place between multiple different servers written in different technologies
- It is harder to get a single source of truth in the system, which means it is harder for the application server to know what is really going on
- Doing such work from a browser opens up vulnerabilities and attack vectors on the system - as the code itself is wide open and exposes more of the backend infrastructure
Skip it if you can.
Now lets add back that STUN/TURN server into the mix.
#5 - WebRTC Media Server Call Relay
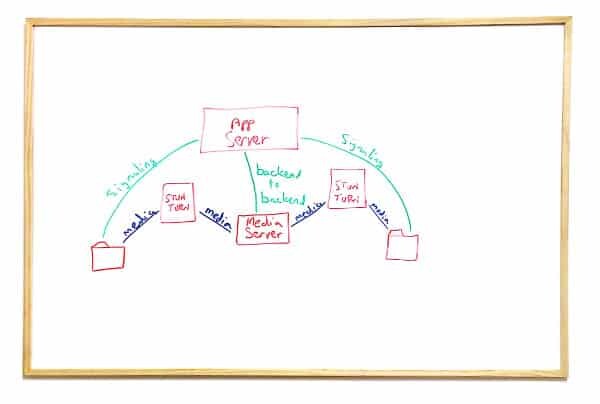
This scenario is actually #3 with one minor difference - the media gets relayed via TURN.
It will happen if the browsers are behind firewalls, or in special cases when this is something that we enforce for our own reasons.
Nothing special about this scenario besides the fact that it may well happen when your intent is to run scenario #3 - hard to tell your users which network to use to access your service.
#6 - WebRTC Media Server Call Partial Relay
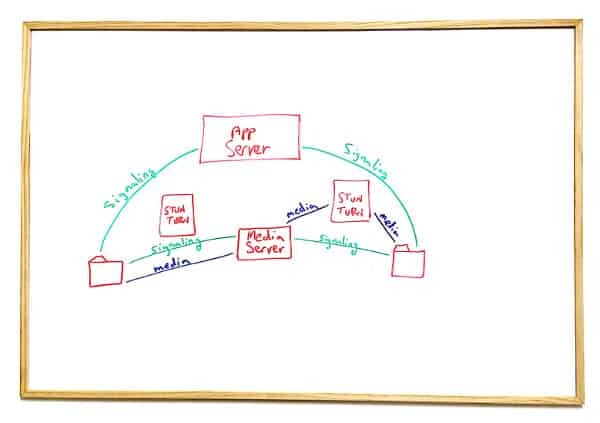
Just like #5, this is also a derivative of #3 that we need to remember.
The relay may well happen only in one side of the media server - I hope you remember that each side is a WebRTC session on its own.
If you notice, I decided here to have signaling direct to the media server, but could have used the backend to backend signaling.
#7 - WebRTC Media Server and TURN Co-location
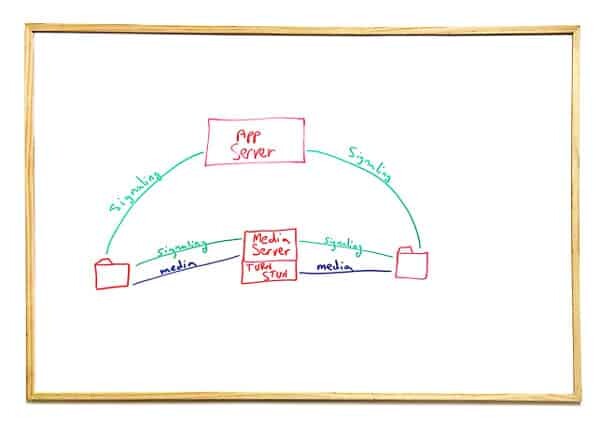
This scenario shows a different type of a decision making point. The challenge here is to answer the question of where to deploy the STUN/TURN server.
While we can put it as an independent entity that stands on its own, we can co-locate it with the media server itself.
What do we gain by this? Less moving parts. Scales with the media server. Less routing headaches. Flexibility to get media into your infrastructure as close to the user as possible.
What do we lose? Two different functions in one box - at a time when micro services are the latest tech fad. We can't scale them separately and at times we do want to scale them separately.
Know Your WebRTC Flows
These are some of the decisions you'll need to make if you go to deploy your own WebRTC infrastructure; and even if you don't do that and just end up going for a communication API vendor - it is worthwhile understanding the underlying nature of the service. I've seen more than a single startup go work with a communication API vendor only to fail due to specific requirements and architectures that had to be put in place.
One last thing - this is 1 of 40 different lessons in my Advanced WebRTC Architecture Course. If you find this relevant to you - you should join me and enroll to the course. There's an early bird discount valid until the end of this week.
