
RTC@Scale is Facebook’s virtual WebRTC event, covering current and future topics. Here’s the summary for RTC@Scale 2024 so you can pick and choose the relevant ones for you.
WebRTC Insights is a subscription service I have been running with Philipp Hancke for the past three years. The purpose of it is to make it easier for developers to get a grip of WebRTC and all of the changes happening in the code and browsers – to keep you up to date so you can focus on what you need to do best – build awesome applications.
We got into a kind of a flow:
- Once every two weeks we finalize and publish a newsletter issue
- Once a month we record a video summarizing libwebrtc release notes (older ones can be found on this YouTube playlist)
Oh – and we’re covering important events somewhat separately. Last month, a week after Meta’s RTC@Scale event took place, Philipp sat down and wrote a lengthy summary of the key takeaways from all the sessions, which we distributed to our WebRTC Insights subscribers.
As a community service (and a kind of a promotion for WebRTC Insights), we are now opening it up to everyone in this article 😎
Why this issue?
Meta ran their rtc@scale event for the third time. Here’s what we published last year and in 2022. This year was “slightly” different for us:
- Philipp was in-between jobs. March 25th was his first day at Meta and this was the reason he got a notebook
- Tsahi was a speaker at rtc@scale
While you can say we’re both biased on this one, we will still be offering an event summary here for you. And we will be doing it as objectively as we can.
Our focus for this summary is what we learned or what it means for folks developing with WebRTC. Once again, the majority of speakers were from Meta. At times they crossed the line of “is this generally useful” to the realm of “Meta specific” but most of the talks provide value.
Writing up these notes takes a considerable amount of time, but is worth it (we know - we’ve done this before). You can find the list of speakers and topics on the conference website, the playlist of the videos can be found here (there’s also a 6+ hours long session there that includes all the Q&As). You can also just scroll down below for our summary.
Our top picks
Our top picks:
- “Improving International Calls” since it is quite applicable to WebRTC
- “Improving Video Quality for RTC” since you can learn quite a bit about AV1
- “Enhanced RTC Network Resiliency with Long-Term-Reference and Reed Solomon code” since you can learn about FEC for video (LTR is not in libWebRTC currently)
- “Machine Learning based Bandwidth Estimation and Congestion Control for RTC” since BWE is crucial to quality.
We find these most applicable to how you deal with WebRTC in general, even outside of Meta.
General thoughts (TL;DR)
- Meta is taking the route of most large vendors who do millions of minutes a day
- It is gutting out WebRTC in the places that are most meaningful to it, replacing them with their own proprietary technology
- Experiences in native applications are being prioritized over browser ones, and the browser implementation of WebRTC is kept as a fallback and interoperability mechanism
- Smaller vendors will not be able to play this game across all fronts and will need to settle for the vinyl quality and experience given by WebRTC
- Sadly, this may lead to WebRTC’s demise a few within a few years’ time
- Meta can take this approach because the majority of their calls take place in mobile native applications, so they are less reliant and dependent on the browser
- Other large vendors are taking a similar route
- Even Google did that with Duo and likely is doing similar server-side things with Meet
SESSION 1 - RTC@Scale
Li-Tal Mashiach, Meta / Host Welcome
(4 minutes)
Watch if you: need a second opinion on what sessions to watch
Key insights:
- Pandemic is over and still Meta is seeing growth. That said, no numbers were shared around usage
Nitin Khandelwal, Meta / Keynote: From Codec to Connection
(13 minutes)
Watch if you: are a product person
Key insights:
- Great user stories with a very personal motivation
- Meta is all about “Connection” and “Presence” and RTC is the technical vehicle for creating “Presence when People are apart”
- Large group calling is first mentioned for collaboration and only then for social interactions but we wonder why “joining ongoing group calls at any time” is being specifically mentioned as a feature
- Codec avatars and the Metaverse are mentioned here, but aren’t discussed in any of the talks, which would have been nice to have as well
- Interoperability and standards are called out as an absolute requirement which ties in with the recent WhatsApp announcement
Sriram Srinivasa + Hoang Do, Meta / Revamping Audio Quality for RTC Part 1: Beryl Echo Cancellation
(20 minutes)
Watch if you: are an engineer working on audio and enjoyed last year’s session
Key Insights:
- Meta implemented a new proprietary AEC called Beryl to replace the one that WebRTC uses by default. This session explains the motivation, technical details and performance results of Beryl
- The audio pipeline diagram at 1:10 remains great and gives context for this year's enhancements which are in AEC and a low-bitrate audio codec:
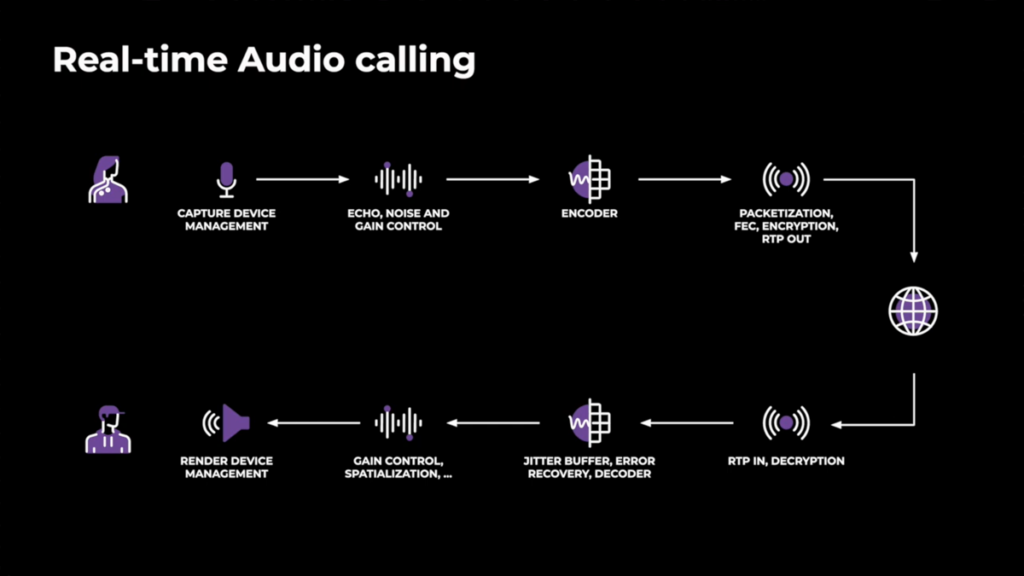
- At 2:50 we get a good summary of what “AI” can do in this area. Unsurprisingly this depends a lot on how much computational effort can be spent on the device
- Meta’s Beryl is for more general usage and aims to be a replacement for WebRTC’s AEC3 (on desktop) and AECM (on mobile). At 4:00 we get a proper definition of acoustic echo as a block diagram. Hardware AEC is noted as not effective on a large number of devices and does not support advanced features like stereo/spatial audio anyway
- At 06:00 the Beryl part gets kicked off with a hat-tip to the WebRTC echo cancellation and at 7:50 another block diagram. One of the key features is that Beryl is one AEC working in two modes, with a “lite” mode for low-powered devices. The increase in quality compared to WebRTC comes at the expense of 7-10% more CPU being used:
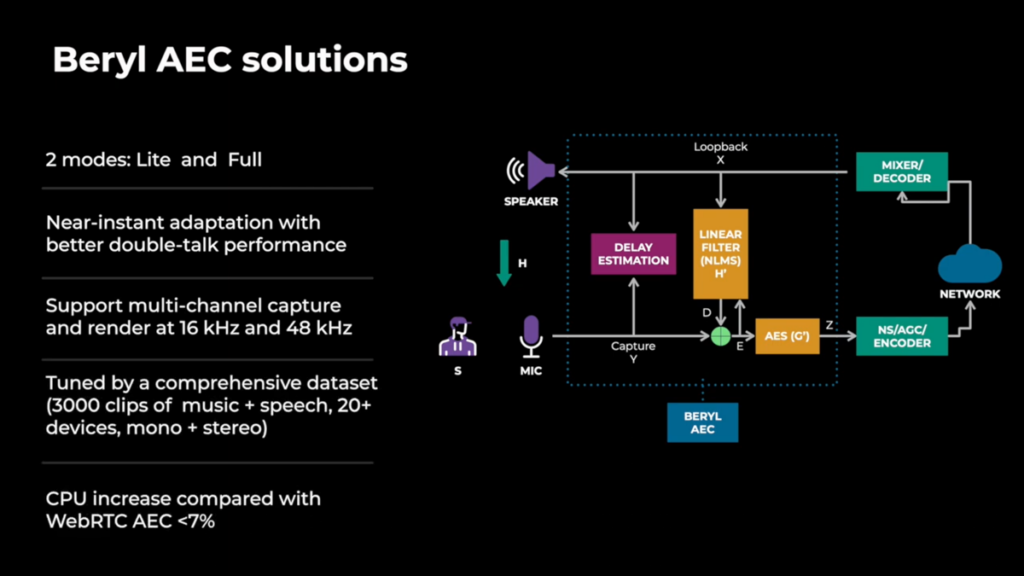
- At 09:00 we get an intro to the different subcomponents of AEC, delay estimation, linear echo cancellation (AEC) and “leftover” echo suppression (AES)
- At 13:30 come the learnings from implementing the algorithms, a demo at 16:30 and a apples-to-apples comparison with libWebRTCs AEC (which should be relatively fair since the rest of the pipeline is the same) showing a 30% increase in quality for a number of scenarios
- This is a nice alternative summary if you still need convincing to watch the video
Jatin Kumar + Bikash Agarwalla, Meta / Revamping Audio Quality for RTC Part 2: MLow Audio Codec
(17 minutes)
Blog post: we hope there will be one!
Watch if you: are an engineer working on audio
Key Insights:
- Meta implemented a new proprietary audio codec called MLow to improve upon and replace Opus within its applications
- We start (if you skip the somewhat repeated intro) at 2:30 with the already familiar audio pipeline block diagram and a motivation for a new codec including the competitive landscape. Meta aims to provide good quality even on low-end devices
- At 4:30 we get a good overview of the requirements. Fast integration by reusing the Opus API is an interesting one. ML/AI would be nice to use but would increase complexity in ways which lead to worse overall quality:

- At 5:50 we get an overview of how the new codec works at a high level followed by the approach taken to develop the codec at 8:15 which is interesting because you don’t hear about the compromise between “move fast when trying things” and “be extremely performant” very often
- At 9:30 we get some insight into how the evaluation was done using diverse and representative input and the actual crowdsourced listening tests (which are a lot of effort and are therefore expensive) at 11:30. Tools like VISQOL and POLQA are used for regression testing. 1.5 years of development time sounds quite fast!
- At 13:00 we got a demo. We wonder which Opus version was used for comparison due to the recent 1.5 improvements there which promise improvements in the same low-bandwidth area
- MLow can offer comparable quality to 25kbps opus at 18kbps but you might not care if you have more than 16kbps available since both codecs show very similar POLQA scores at that bitrate:
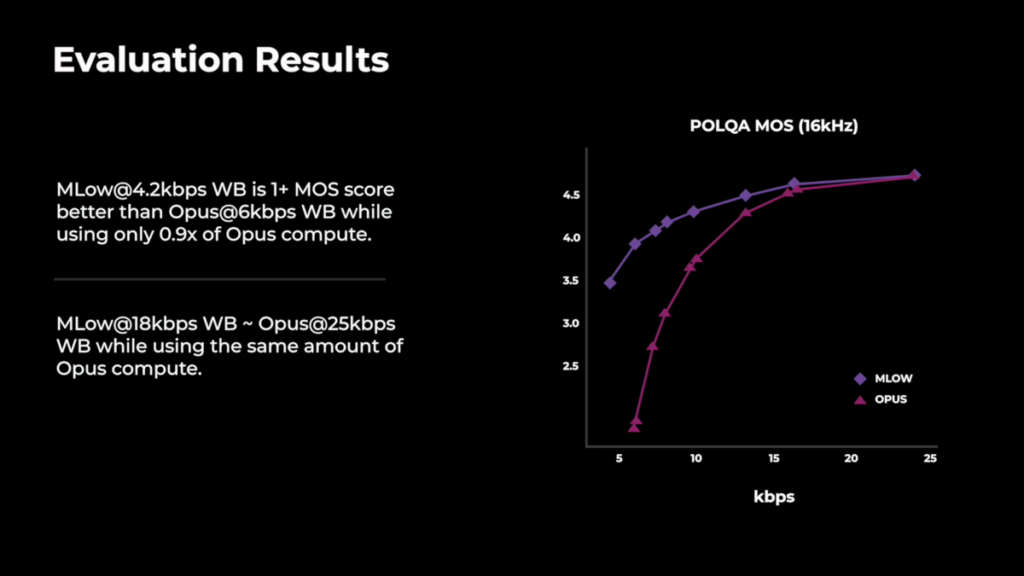
- At 15:40 we get production results which show improvements (which are not quantified in this talk). Improvements in video quality are a bit surprising, we would not spend more bits on video in low-bitrate scenarios
Yi Zhang + Saish Gersappa, Meta / Improving International Calls
(19 minutes)
Watch if you: are looking for architecture insights also applicable to WebRTC
Key Insights:
- Meta details how they are moving to a move decentralized architecture globally to make their calling experience more robust
- 20% of Whatsapp calls are international, half a billion a day and “bad quality” is 20% more likely on those calls due to the more complex technical challenges which are clearly spelled out on the slide at 2:00 with a good explanation of how network issues are visible to the user
- At 3:10 we get a very good introduction to the basics of how VoIP works. What Whatsapp calls a relay is slightly different from a TURN server since their “relay” is also used for multiparty calls. Being more than a TURN server allows the relay to do a bit more, in particular since it can decrypt and handle RTCP feedback
- At 4:20 we get a good discussion of what is sometimes known as the “USPS problem” - it is very rude to make the sender retransmit a packet that *you* lost (from a 2016 Twitter conversation)
- A packet/NACK cache is an essential component of SFUs and we consider this the norm, not forwarding the NACK.
- In cases of downstream packet loss it reduces the error correction time by half and makes the retransmission more effective
- Notably this is for audio where Meta is known to leverage libWebRTC audio nack support in Messenger that is not enabled by default there (Google Meet enables it as well)
- At 5:40 the relay is shown to be “smart” about upstream loss as well since it can detect the loss (i.e. a gap in the RTP sequence number) and proactively send a NACK, saving one RTT. This is followed by a summary on other things the relay can do such as duplicating packets (which is an alternative to RED for audio)
- At 6:30 we get an idea how these basics apply to international calls which generally have a longer RTT (which makes the NACK handling more important)
- At 8:00 we get into the new architecture called “cross relay routing” which is essentially a distributed or cascaded SFU (see e.g. the Jitsi approach from 2018 or the Vidyo talk from 2017)
- This keeps the RTT to the NACK handling low (for downstream packet loss to the level of local calls) which improves quality and also utilizes Meta’s networking backbone which has lower packet loss than the general internet
- They also have higher bandwidth so one can do more redundancy and duplication
- At Whatsapp scale this creates the problem of picking the right relays which is done by looking at latencies. This is a tricky problem, it took Jitsi from 2018 until 2022 to get the desired results
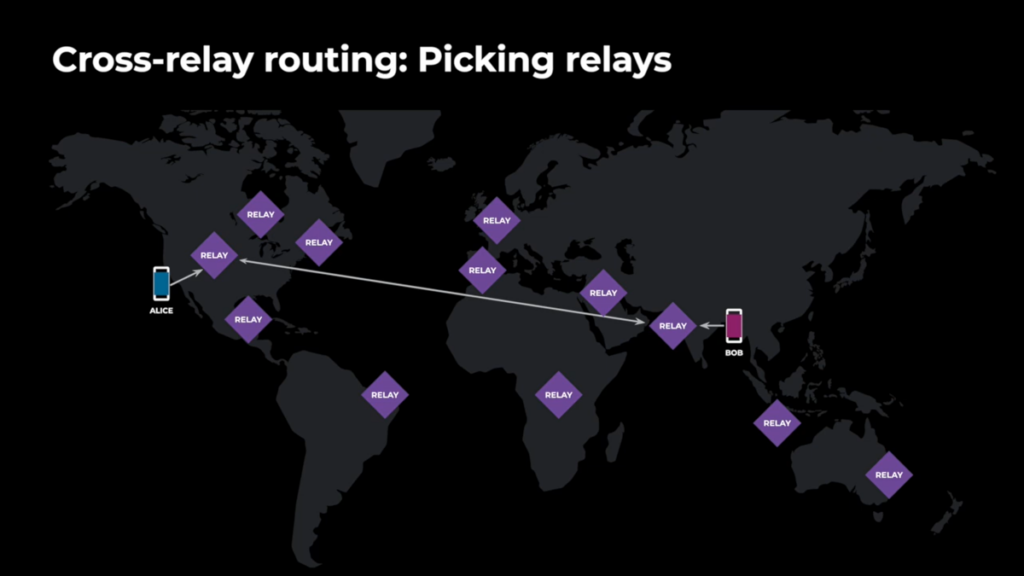
- At 11:00 (or 13:00) this gets expanded to group calls by using an architecture that starts with the centralized relay and extends it to a central router that only forwards the media packets combined with RTCP-terminating edge relays
- Some decisions like bandwidth estimation are delegated to the local relay while some decisions, in particular related to selective forwarding (e.g. active speaker determination which influences bandwidth allocation, see last year's talk) are run on the central relay which has a complete view of the call
- Simulcast and in particular temporal layer dropping is surprising to see only in the central relay, it should be done in the edge relays as well to adapt for short-term bandwidth restrictions
- Our opinion, is that over time, Meta would be moving most of these decisions from the central relay to the local relays, distributing the logic further and closer to the edge
- At 16:40 we get a glimpse into the results. Unsurprisingly things work better with faster feedback! Putting servers closer to the users is an old wisdom but one of the most effective ways to improve the quality. The lesson of using dedicated networks applies not only to Meta’s backbone but also the one used by the big cloud providers. This quality increase is paid by increased network cost however
First Q&A with Speakers
https://www.youtube.com/live/dv-iEozS9H4?feature=shared&t=5821 (25 minutes)
Watch if: you found any of the sessions this covers interesting
Key Insights:
- Quite a few great questions
- One thing that stood out was the question whether NACK for audio helps vs FEC and the answer is “yes”, because they provide the full quality when the RTT is low. What to use in different situations depends on the conditions. Which is a sentiment that keeps coming up
SESSION 2 - RTC@Scale
Shyam Sadhwani, Meta / Improving Video Quality for RTC
(22 minutes)
Blog post: https://engineering.fb.com/2024/03/20/video-engineering/mobile-rtc-video-av1-hd/
Watch if: you are thinking of adopting AV1 or trying to improve video quality
Key Insights:
- Meta’s overview of the work and effort put into improving their video quality, and the route they took, especially with AV1 - the tradeoffs made when adopting it
- “Why is the video quality of RTC not as great as Netflix” is a good question to ask, followed by a history of video encoding since DVDs came out in 1997. The answer is somewhat obvious from the constraints RTC operates under (shown at 2:00)
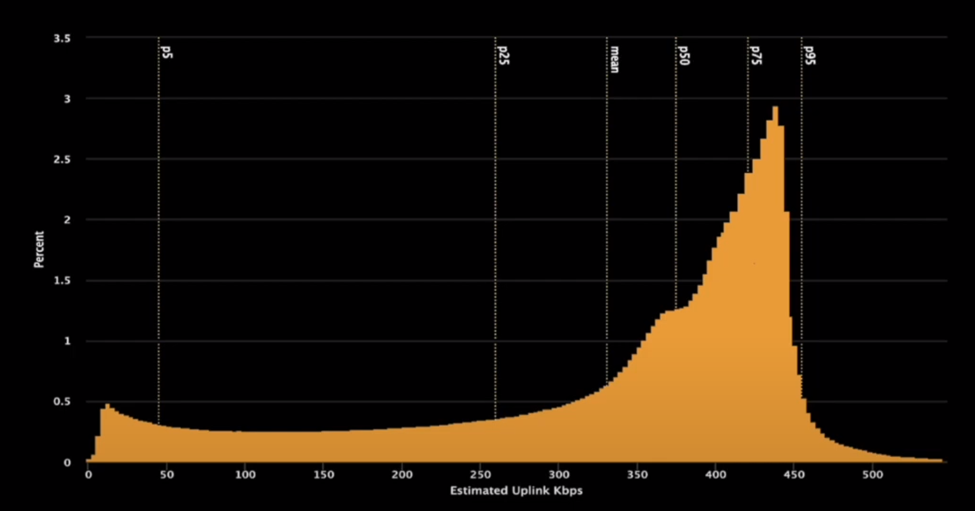
- At 3:20 we start with a histogram of the bandwidth estimation distribution seen by Meta. “Poor calls”, which are below 300kbps (for audio and video, including RTP overhead) have about 200kbps for the video target bitrate. Choosing a more efficient video codec like AV1 is one of the most effective knobs here (and we knew Meta was taking a route after last year's talk). The bandwidth distribution Meta sees is shown below:
- While AV1 is largely not there yet in hardware encoders, the slides at 06:00 explain why one actually wants software encoders; they provide better quality at the target bitrates used by RTC which is something we have seen in Chromium’s decision to use software encoding at lower resolutions a while back
- At 7:00 we get a demo comparison which of course is affected by re-encoding the demo with another codec but the quality improvement of AV1 is noticeable, in particular for the background. AV1 gives 30% lower bitrate compared to H.264, even more for screen sharing due to screen content coding tools
- Quite notably the 600kbps binary size increase caused by AV1 is a concern. WebRTC in Chrome was somewhat lucky in that regard since Chrome already had to include AV1 support for web video decoding
- Multiple codecs get negotiated through SDP and then the switch between them happens on the fly. From the blog post that is not happening through the more recent APIs available to web browsers though
- Originally a video quality score based on encoding bitrate, frame rate and quantization parameter was used (10:30) but the latter is not comparable between AV1 and H.264 so the team came up with a way to generate a peak signal to noise ratio like metric that was used for comparison. This allowed a controlled rollout with measurable improvements
- High end networks (with an available bitrate above 800kbps) also benefit from AV1 as we can see starting at 12:30. At least on mobile devices 1080p resolution does not provide perceived advantages over 720p
- “Isn’t it just a config change to raise max bitrate” is an excellent question asked at 13:45 and the answer is obviously “no” as this caused issues ranging from robotic voice to congestion. In particular annoying is constantly switching between high-quality video and low-quality which is perceived negatively (take this into account when switching spatial layers in SFUs). At high bitrates (2.5mbps and up) it makes a lot of sense to do 2-3x audio duplication (or redundancy) since audio quality matters more
- Mobile applications have the advantage of taking into account the battery level and conditionally enable AV1 which is, for privacy reasons, not available in the browser
- The talk gets wrapped up with a recap of the benefits of AV1 both in low-end (at 18:00) and high-end (at 19:10)
- And we even got a blog post!
Thomas Davies, Visionular / AV1 at the coalface: challenges for delivering a next-generation codec for RTC
(19 minutes)
Watch if: you are interested in a deep dive on AV1 and video encoding in general
Key Insights:
- Visionular on what goes into the implementation of a AV1 video encoder
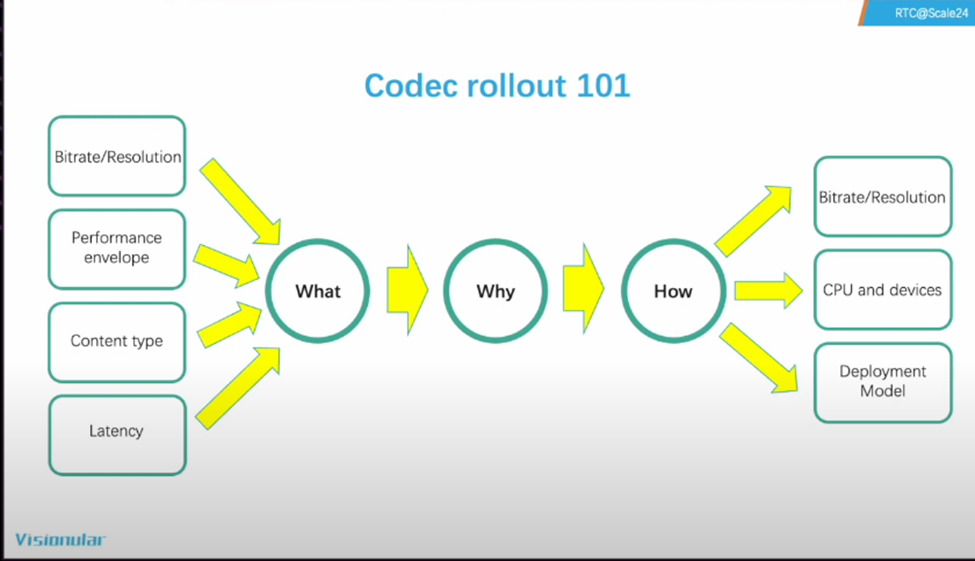
- The talk starts off with a very good explanation of the what, why and how of rolling out an additional codec to your system. For WebRTC in the browser you don’t control much beyond the bitrate and resolution but one can still ask many of the questions and use this is a framework:
- At 4:30 we go into the part that describes encoder performance (where you can really optimize). The big constraint in RTC is that the encoder needs to produce a frame every 33 milliseconds (for 30fps)
- Knowing the type of the content helps the encoder pick the right encoding tools (which is why we have the contentHint in WebRTC turning on screen content coding with good results)
- Rate control (10:00) is particularly important for RTC use-cases. Maximum smoothness is an interesting goal to optimize for, in particular since any variance in frame size is going to be magnified by the SFU and will affect its outgoing network traffic
- Adaptivity (12:50) for AV1 comes in two forms: SVC for layering and changing resolution without a keyframe
- The “sales pitch” for Visionulars encoder comes quite late at 14:15, is done in less than 90 seconds and is a good pitch, the last part (15:30) is an outlook where RTC video encoding might go in the future
Gang Shen, Intel / Delivering Immersive 360-degree video over 5G networks
(16 minutes)
Watch if: you are working in the 360-degree video domain
Key points:
- Intel, reviewing the challenges of 360-degree immersive video
- We’re not quite sure what to do with this one. The use-case of 360 degree video is hugely demanding and solving it means pushing the boundaries in a number of areas
- Until around 06:00, the discussion revolves around the unsuitability of HTTPS, and only from here, the discussion starts looking at UDP and WebRTC (an obvious choice for viewers of RTC@Scale)
- Latency being a challenge, Intel went with 5G networks
- It was hard to understand what Intel wanted to share here exactly
- What is the problem being solved here?
- Is 5G relevant and important here, or just the transport used, focusing on the latest and greatest cellular?
- What challenges 360-video poses that are unique (besides being 8K resolution)?
- Demo starts at 09:10, results at 11:00, a summary at 12:30 and an outlook at 14:30
- All in all, this session feels a bit like a missed opportunity
Fengdeng Lyu + Fan Zhou, Meta / Enhanced RTC Network Resiliency with Long-Term-Reference and Reed Solomon code
(19 minutes)
Watch if:
- you are using H.264 and are interested in features like LTR
- you are interested in video forward error correction
Key points:
- Secret sauce is promised!
- The talk starts by describing the “open source baseline”, RTX, keyframes and XOR-based FEC
- We would describe keyframes as a last resort that you really want to avoid and add temporal scalability (which allows dropping higher temporal layers) to the list of tools here
- Using half the overall traffic for FEC sounds like too much, see this KrankyGeek talk which discusses the FEC-vs-target bitrate split
- In the end this needs to be tuned heavily and we don’t know the details
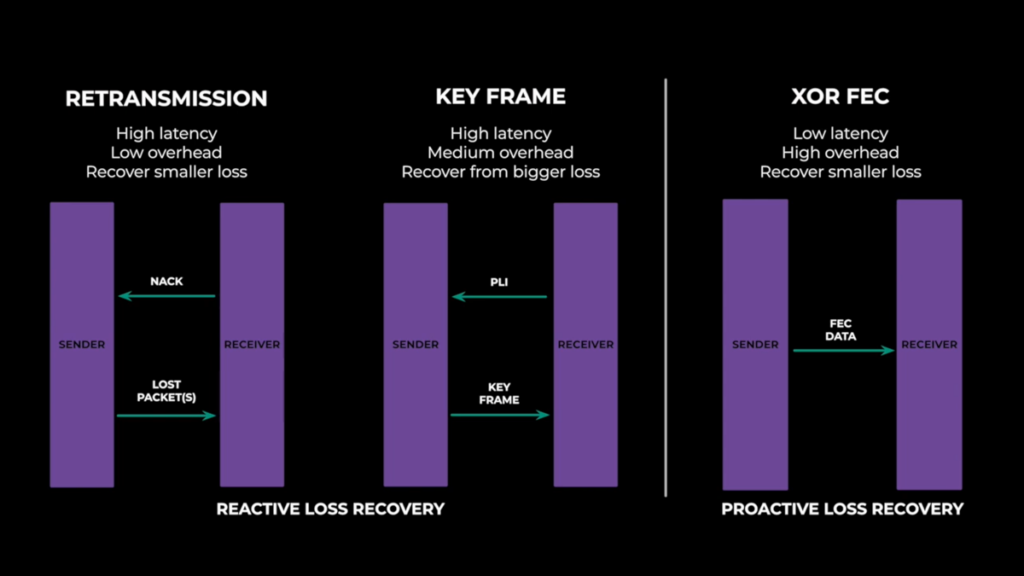
- At 4:20 we get a deep-dive on LTR, long-term reference frames, which is a fairly old H.264 feature
- The encoder and decoder keep those frames around for longer and can then use them as baseline from which a subsequent frame is encoded/decoded instead of a previous frame which was lost (and then no longer needs to be recovered)
- The implicit assumption here is 1:1, for multiparty LTR can not be used which is mentioned in the Q&A
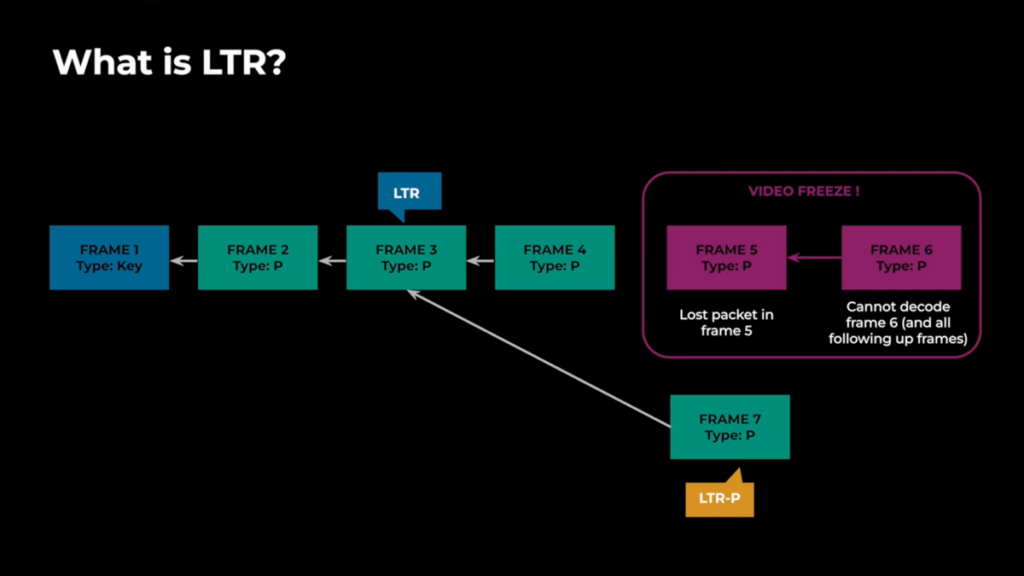
- When using LTR (vs NACK and FEC) makes sense is a question that is difficult to answer, we get to know Meta’s answer at 9:50: The largest gains seem to be in bandwidth-limited high-loss networks which makes sense
- As a “VP8 pipeline” with only very rudimentary H.264 support libWebRTC does not support H.264 LTR out of the box and we will see whether Meta will open source this (and Google merges it)
- At 10:30 we jump back to forward error correction, talking about the problems of the XOR-based approach and explaining the “only works if at most one packet covered by the recovery packet is lost” and the protection scheme
- At 13:00 the important property of Reed-Solomon-FEC is explained which is more advanced than the XOR-based approach since the number of packets that can be recovered is proportional to the number of parity packets. This is followed by some practical tips when doing RS-FEC (which you won’t be able to do in the browser which also can not send FlexFEC)
- At 16:30 there is a recap of the results. As with all other techniques, we are talking about single-digit improvements which is a great win. Meta promises to upstream their FEC to the open source repository which we are looking forward to (some of this already happened here)
- Surprisingly video FEC has remained relatively obscure in WebRTC, neither Google Meet nor any of the well-known open source SFUs use it.
Second Q&A with Speakers
https://www.youtube.com/watch?v=dv-iEozS9H4&t=13260s (23 minutes)
Watch if: you found any of the sessions this covers interesting
Key Insights:
- Quite a few great questions, including some from the one and only Justin Uberti who apparently cannot stop keeping an eye on what is going on in RTC
- A lot of interest in LTR
SESSION 3 - RTC@Scale
Tsahi Levent-Levi, bloggeek.me / The past and future of WebRTC, 2024 edition
(24 minutes)
Watch if: you like to hear Tsahi speaking. He does some juggling too!
Key Insights:
- Quite often when trying to explain why some things in WebRTC are a bit weird the answer is “for historical reasons”. Tsahi gives his usual overview of the history of WebRTC, dividing it into the early age of exploration, the growth and the differentiation phases and looks at the usage of WebRTC we have seen in and since the pandemic
- Tsahi is undoubtedly the person who spent the most time with developers using WebRTC and thought a lot about how to explain it. What is interesting is that Tsahi has to explain what Google does while the WebRTC team at Google remains silent
- Google’s libWebRTC is a cornerstone of the ecosystem and is still tightly integrated into Chromium and its build and release process. Yet despite increased usage we see a slowdown in development looking at the number of commits and is effectively in maintenance mode. And it remains a Google-owned project (notably Meta is not affected by this since they can and have forked libWebRTC and they can release changes without open sourcing them)
- What we see (at 10:10) currently in libWebRTC and Chromium is Google striving for more differentiation through APIs like Insertable Streams and Breakout Box without being forced to opensource and make everything to their competitors for free (e.g. we do not have built-in background blur into Chromium). Philipp isn’t convinced that WebTransport will replace WebRTC altogether. It makes sense for use-cases for which WebRTC was not the right tool though
- Screen sharing is another topic (at 14:15) where we see a lot of improvements in Chromium and this is driven by the product needs of Google Meet. Some of the advances may only make sense for Google Meet but that is fair since Google is the party who pays the development cost
- Optimization and housekeeping (at 17:20) are something that is not to be underestimated. Google has paid for the development of libWebRTC for more than a decade which is a huge investment in addition to open sourcing the original intellectual property
- We heard a lot about AV1 as the most modern video codec and this continues in this talk. Lyra as an alternative audio codec has some competition (such as the new Meta audio codec) and it has not landed natively in the browser. Does Google use it together with WebRTC in native apps? Maybe…it requires effort to find out. As we have seen at KrankyGeek one can use it via WASM and insertable streams
- The outlook is at 22:30 and raises the question how WebRTC will fare in 2024
Mandeep Deol + Ishan Khot, Meta / RTC observability
(20 minutes)
Watch if: you deploy a WebRTC-based system in production
Key points:
- WebRTC is great when it works but sometimes it does not and then you need to debug why things do not work the way you expect. And you can not seriously ask your users to send you a chrome://webrtc-internals dump. Hence you need to make your system observable which means getting logs from the clients and servers
- Two of the points on the slide at 0:40 are applicable to any system you build: you need to ensure user privacy, in particular for IP addresses and you need to strike a balance between reliability and efficiency

- The “call debugging” section starting at 3:10 makes a good point: your system needs to provide both service-level metrics (such as what percentage of calls fail) as well as the ability to drill down to a particular session and understand the specific behavior (as you might have noticed, this is a topic close to the hearts of Philipp and Tsahi who evolved this project into rtcStats). At 4:15 we see Meta’s tool named “call dive”:
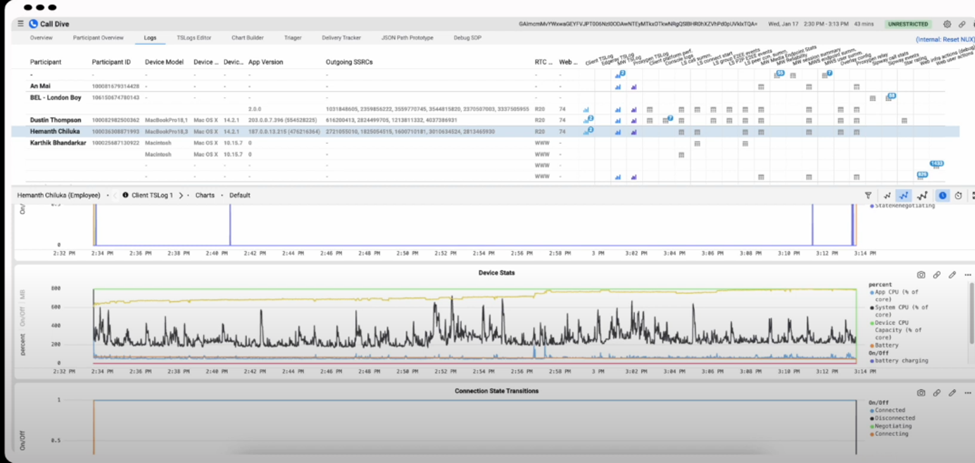
- From the looks of it, it provides the fairly standard “timeline” view of some statistics (since we are dealing with a mobile application there are battery stats) but note that this is aggregated at the call level with multiple users
- At 5:40 we get a deep dive into what it took Meta to develop the system. Some of these challenges are specific to their scale but the problem of how to aggregate the logs from the various clients and servers involved is very common
- At 10:50 we get a deep-dive into the RAlligator system where the big challenge is determining when a multiparty call is done, all logs have arrived and can be processed by the following parts of the pipeline (which is made more difficult by not uploading the logs in real-time to avoid competing with the actual call). Keeping the logs in memory until then at the scale of Meta must be quite challenging
- The system is designed for debugging, not for customer support where you need to explain to a customer why their call failed and need all logs reliably. Cost-effectiveness is a concern as well, you can’t spend more on the logging than you spend on the actual RTC media
- At 16:00 we get a nice overview of what might be next. A lot of the things make sense but real time call debugging is just a fancy showcase and not very useful in practice. We would really like to see GenAI summarize webrtc-internals logs for us!
- What is missing from the talk is how such a system is generating platform statistics which together with A/B experimentation must be the basis for the rollout results we see in many of the other talks
Sean Dubois, Livekit / Open Source from One to at Scale
(21 minutes)
Watch if you: like open source
Key takeaways:
- This talk is about Sean’s experience working in the open source community, and especially Pion
- Here, Sean tries to explain the benefits of open sources versus proprietary software, coming at it from the angle of the individual developer and his own experiences
- When viewing, remember that most of these experiences are with highly popular open source projects
- Your mileage may vary greatly with other types of open source projects
- At 05:50 Sean makes a point of why Product Managers aren’t needed (you can talk to the customers directly and they even pay for it)
- Tsahi as a Product Manager objects 😉
- Talking to customers directly is needed for developers in products, but guidance and decisions ultimately need to be taken by the right function - even for developer-centric products and services
- At 07:00 we get into how Amazon maintains their Chromium fork (Silk)
- They have lots of patches made that they keep internally and are able to stay two weeks behind Chromium. But this feat requires 6 full time employees to achieve. Igalia had a great blog post on “downstreaming Chromium” recently (part two should be more interesting)
- When using an open source project, careful decisions should be taken about contributing back versus keeping modifications proprietary. Reducing the cost of maintenance is quite an effective argument that Philipp has been using countless times
- Sean touches the topic of money and open source at around 15:00. We believe this viewpoint is naive, as it doesn’t factor in investors, competition and other market constraints. For example we have seen a lot of WebRTC CPaaS vendors engage in direct peeing contests in response to Twilio shutting down which had a bad effect on what was left of a sense of “community” in WebRTC

- All in all, quite an interesting session. Juxtapose this with how Meta is making use of open source for its own needs and how much of their effort gets contributed back when it comes to WebRTC for example. Or how Google open-sourced WebRTC and is pretty silent about it these days. Philipp’s approach of working with Google remains quite unique in that area but is not born from enthusiasm for WebRTC - more out of a necessity
Liyan Liu + Santhosh Sunderrajan, Meta / Machine Learning based Bandwidth Estimation and Congestion Control for RTC
(20 minutes)
Watch if: you are interested in BWE and machine-learning
Key takeaways:
- Meta explaining here the work and results they got from employing machine learning to bandwidth estimation
- That machine learning can help with BWE has been known for some time. Emil Ivov did a great presentation on the topic at KrankyGeek in 2017
- The talk starts with a recap of what Meta achieved by moving from receive-side bandwidth by rolling out send-side BWE (SSBWE) in 2021 and a lot of tuning of BWE-related parameters in 2022
- Not all networks are different and delivering the best quality requires understanding the type of network you are on
- This is followed by a high-level overview of the different components in the WebRTC SSBWE implementation. That implementation is quite robust but contains a lot of parameters that work in certain scenarios but can be tuned (which is not possible in the browser). See this block diagram of the components:
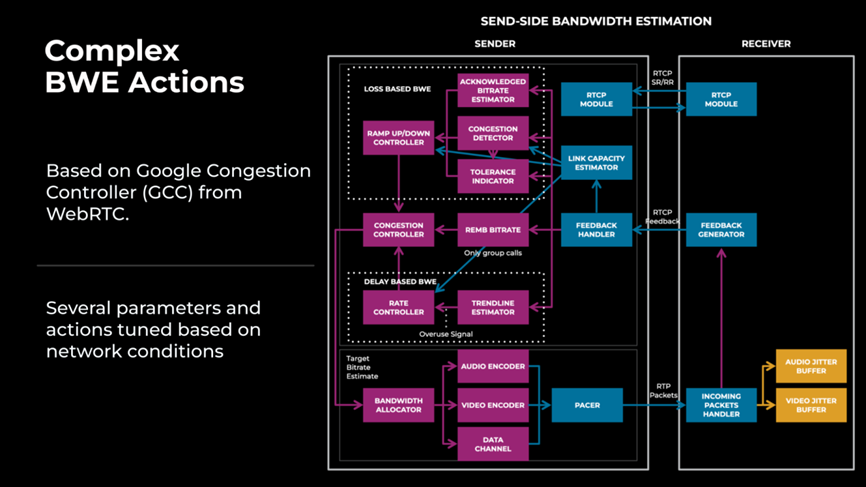
- The “what is the appropriate strategy in this situation” question is one that indeed needs to be answered holistically and is driving resilience mechanisms and encoding
- Applying ML to network characterization requires describing the network behavior in a way that can be understood by machine learning which is the topic of the part of the talk starting at 4:10. Make sure to talk to your favorite machine learning engineer to understand what is going on! The example that starts at 7:05 gets a bit more understandable and shows what input “features” are used
- Once random packet loss is detected the question is what to do with that information and we get some answers at 9:05. E.g. one might ignore “random” loss for the purpose of loss-based estimation (which Google’s loss-based BWE does in a more traditional way by using a trendline estimator for the loss)
- At 9:30 we got from network characterization to network prediction, i.e. predicting how the network is going to react in the next couple of seconds
- This is taking traditional delay-based BWE which takes an increase in receive-packet delay as input for predicting (and avoiding) congestion
- The decision matrix shown at 12:00 is a essentially a refined version of the GoogCC rate control table
- As we learn in the Q&A the ML model for this is around 30kb or ten seconds of Opus-encoded audio but binary size is a concern
- At 14:50 we get into the results section which shows a relatively large gain from the improvements. Yep, getting BWE right is crucial to video quality! We are not surprised that a more complex ML-based approach outperforms simplified hand-tuned models either. WebRTCs AudioNetworkAdapter framework is an early example of this
- An interesting point from the outlook that follows is how short the “window” used for the decisions is. 10 seconds is a lot of time in terms of packets but a relatively short window compared to the duration of the usual call
- As we learn in the Q&A the browser lacks APIs for doing this kind of BWE tuning. Yet the W3C WebRTC Working Group prefers spending time on topics like “should an API used by 1% be available on the main thread”...
Live Q&A with Speakers
https://www.youtube.com/live/dv-iEozS9H4?feature=shared&t=21000 (24 minutes)
Watch if: you found any of the sessions this covers interesting
Key Insights:
- Quite a few great questions again, including how to simulate loss in a realistic way (where the opus 1.5 approach may help)
- And we learn how many balls Tsahi can juggle!

Closing remarks
As in previous years, we tried capturing as much as possible, which made this a wee bit long. The purpose though is to make it easier for you to decide in which sessions to focus, and even in which parts of each session. And of course for us so we can look things up and reference it in future blog posts or courses!
