
And while at it - don’t mix signaling with NAT traversal.
Somehow, many people are asking these question in different phrasing, taking different angles and approaches to it. The thing is, if you want to build a robust production worthy service using WebRTC, you need to split these three entities.
If you want to learn more about the challenges of group calling in WebRTC, then this free 5-part video course on Mastering Group Call Performance in WebRTC SFUs is exactly for you.
Now, let’s dive into the details a bit -
Signaling Servers
Signaling servers is something we all have in our WebRTC products.
Why?
Because without them there’s no call. At all. Not even a Hello World example.
It is that simple.
You can co-locate the signaling server with your application server.
Here are a few things that you probably surmised about these servers already:
- You can scale a single server to handle 1000’s or event 100,000’s of connections and sessions in parallel
- These servers must maintain state for each user connected to them, making them hard to scale out
- Oftentimes, decisions that take place in these servers rely on external databases
- Latency of a couple 100’s of milliseconds is fine for these servers, but it is rather easy to be abusive and have that blown out of proportion if not designed and implemented properly (a few high profile services that I use daily come to mind here)
Did I mention signaling servers are written in higher level languages? Java, Node.js, Rails, Python, PHP (god forbid), ...
NAT Traversal Servers
STUN and TURN is what I mean here.
And yes, we usually cram STUN along with TURN. TURN is the resource hog out of the two, but STUN can be attached to the same server just because they both have the same general purpose in life (to get the media flowing properly).
This is why I will ignore STUN here and focus on TURN.
Sometimes, people forget to TURN. They do so because WebRTC works great between two browser tabs or two people in the same office without the need for TURN, and putting Google’s STUN server URL is just so simple to do… that this is how they “ship” the product. Until all hell breaks loose.
TURN ends up relaying media between session participants. It does that when the participants can’t reach each other directly for one reason or another. This kind of a relay mechanism dictates two things:
- TURN will eat up bandwidth. And a lot of it
- Your preference is to place your TURN server as close it to the participant as possible. It is the only way to improve media quality and reduce latency, as from that TURN server, you have more control over the network (you can pay for better routes for example)
While you might not need many TURN servers, you probably want one at each availability zone of the cloud provider you are using.
Oh - and most NAT traversal servers I know are written in C/C++.
Media Servers
Media Servers are optional. So much so that they aren’t really a part of the specification - they’re just something you’d add in order to support certain functions. Group calls and recording are good examples of features that almost always translate into needing media servers.
The problem is that media servers are resource hogs compared to any of the other servers you’ll be needing with WebRTC.
This means that they end up scaling quite differently - a lot faster to be exact. And when they fail or crash (which happens), you still want to be able to reconnect the session nicely in front of the customer.
But the main thing is that it has different specs than the other servers here.
Which is why in most cases, media servers are placed in “isolation”.
There’s a point in placing media servers co-located with TURN servers - they scale somewhat together when TURN is needed. But I am not in favor of this approach most times, because TURN is a lot more Internet facing than the media server. And while I haven’t seen any publicity around hackers attacking media servers, it is probably only a matter of time.
And guess what? Media Servers? They are usually implemented in C/C++. They say it’s for speed.
Why Split them up?
Because they are different.
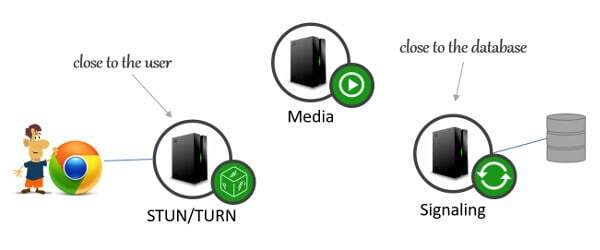
They serve different purposes.
And most likely, they need to be located in different parts of your deployment.
So just don’t. Place them in separate machines. Or VMs. Or Docker. Or whatever. Just have them logically separated and be prepared to separate them physically when the need arise.
If you want to learn more about the challenges of group calling in WebRTC, then this free 5-part video course on Mastering Group Call Performance in WebRTC SFUs is exactly for you.
