It's the money stupid.
Group calls may and usually do require WebRTC media servers to be deployed.
We all love to hate the model of an MCU (besides those who sell MCUs that is).
There are in general 3 main models of deploying a multiparty video conference:
- Mesh - where each participant sends his media to all other participants
- MCU - where a participant is "speaking" to a central entity who mixes all inputs and sends out a single stream towards each participant
- SFU - where a participant sends his media to a central entity, who routes all incoming media as he sees fit to participants - each one of them receiving usually more than a single stream
I've taken the time to use testRTC to show the differences on the network between the 3 multiparty video alternatives on the network.
To sum things up:
- Mesh fails miserably relatively fast. Anything beyond 3 isn't usable anywhre in a commercial product if you ask me
- MCU seems the best approach when it comes to load on the network
- SFU is asymmetric in nature - similar to how ADSL is (though this can be reduced, just not in Jitsi in the specific scenario I tried)
This being the case, how can I even say that SFU is the winning model for WebRTC?
It all comes down to the cost of operating the service.
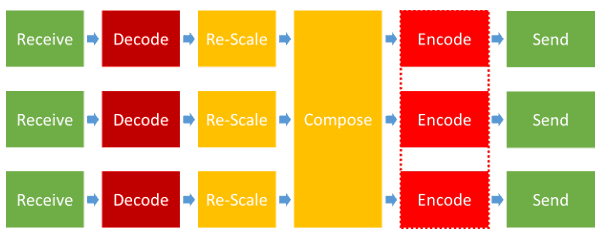
Here's what an MCU does in front of each participant:
Here's what an SFU does in front of each participant:
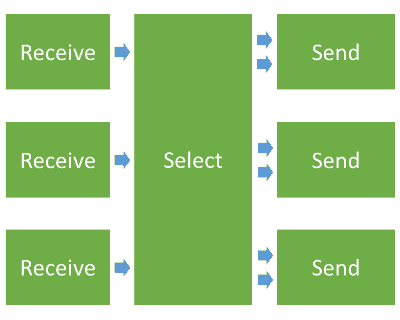
To make things easy for you, I've marked with colors varying from green to red the amount of effort it puts on a CPU to deal with it.
The most taxing activity in an MCU is the encoding and decoding of the video. With the current and upcoming changes in video and displays, this isn't going to lessen any time soon:
- Google just switched to VP9, which takes up more CPU
- 4K displays and cameras are becoming a reality. 8K is being discussed already. This means 4 times the resolutions of full HD
If anything - things are going to get worse here before they get any better.
It is no surprise then that MCUs scale on single machines in the 10's of ports or low 100's at best; while SFUs scale on single machines in the 1,000's of ports or low 10,000's.
Which brings us to two very important aspects of this:
- Price per port, where an SFU will ALWAYS be lower than MCU - by several factors
- Deployment complexity
The first reason is usually answered by people that if you want quality - you need to pay for it. Which is always true. Until you start reminding yourself that video calling today is priced at zero for the most part.
The second reason isn't as easy to ignore. If you aim for cloud based services needing to serve multiple customers, your aim is to go to 10,000 or more parallel sessions. Sometimes millions or more. Here would be a good time to remind you that WhatsApp crossed the billion monthly active users and most messaging services become interesting when they cross 100 million monthly active users.
With such numbers, placing 100 times more machines to support an MCU architecture instead of an SFU one is... prohibitive. There are more costs that needs to be factored in, such as power consumption, rack space and higher administration costs.
The end result?
An SFU model is by far the most popular deployment today for WebRTC services.
Does it fit all use cases? No
Will it fit your use case? Maybe
Do customers care? No
