
WebRTC IP addresses and port ranges can be a bit tricky for those unfamiliar enough with VoIP. I’d like to shed some light about this topic.
A recent back and forth discussion that I had with one of the people taking my online WebRTC course made it clear to me that there are still things I take for granted because I come with a VoIP heritage to what it is I am doing today. Which is why this article here.
Connecting a WebRTC session takes multiple network connections and messages taking place over different types of transport protocols. There are two reasons why that decision was made for WebRTC:
- There was a desire to have it run peer to peer, directly exchanging real time media between two browsers. This requires a different look at how to handle network entities such as NATs and firewalls
- Real time media is different from other data sent over the internet in browsers. The transport and signaling protocols already available were just not good enough to preserve high quality and low latency
Lets see how connections get made over the internet and how WebRTC makes use of that.
A quick explainer to internet connections
We will start by looking at the building blocks of digital communications - TCP and UDP.
The table below summarizes a bit the differences between the two:
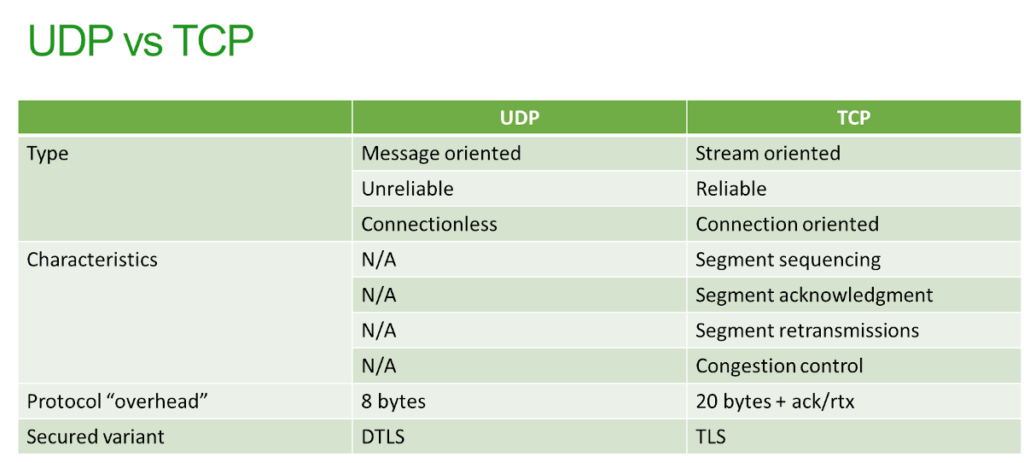
TCP connections
TCP is a reliable transport protocol. As such, it has a built-in retransmission mechanisms that is meant to make sure whatever is sent is received on the other end and in the same order of sending.
To do that properly, a TCP connection needs to be created. A TCP connection is a set of 4 values:
Source IP:Source port + Destination IP:Destination Port
How does one establish a TCP connection?
On your local machine you “bind” one of the local IP addresses of the machine to a local port number. That IP and port needs to be available and not taken for something else already. Then you need to try and connect to the destination IP:port.
Let's say I want to connect to google.com.
For me, google.com resolves to the IP address 172.217.23.110. Assuming I want to connect to port 80 (a “randomly” picked port), I’d do the following: Bind a local IP:port (arbitrary local port), and connect it to 172.217.23.110:80.
Knowing the IP:port on source and destination of the connection means knowing the connection - there cannot be two such connections. Once you bind a local port to connect it to a remote address over TCP, that port cannot be reused until the connection is closed and done with.
If I want to open another TCP connection from my machine to the same address, I will need to bind yet another port on my local address and connect it to the destination IP:port,
Obviously, there are some caveats and edge cases I am ignoring here, but for our needs, the above is enough of an explanation.
UDP “connections”
Since UDP is connectionless, there’s no real connection with UDP. No context whatsoever.
To send a message over UDP, I need again the quad of values:
Source IP:Source port + Destination IP:Destination Port
But this time, there’s no real connection. What happens here is that I open a local IP:port, and whenever I want to send out a message, I just tell it the destination IP:port and be done with it.
Will the message be received? Is there even anyone on the other side listening? That's out of scope of UDP. It doesn't even try to validate these things and leaves it to the developer.
WebRTC signaling connections and addresses
WebRTC signaling is just like any other web application connection.
In order to send and receive the SDP blobs to make the connection, I need to be able to communicate between the browsers and that is done using traditional networking means available in the browser: either HTTP or WebSocket. Both (ignoring HTTP/3) are implemented on top of TCP.
What does that mean?
- When my browser connects to the signaling server, it connects to an HTTPS or a Secure WebSocket address (because… security)
- The destination address will be whatever the DNS will resolve for the name of the server I connect to; and for the most part, this connection will be done towards port 443 (because... security)
- The local address will be whatever local address I have on my machine
- The local port will be an arbitrary local port that the operating system will allocate
The end result?

Local ports are arbitrary (and ephemeral). Destination port is 443 (or whatever advertised by the server).
WebRTC media connections and addresses
Media in WebRTC gets connected via SRTP. Most of the time, that would happen over UDP, which is what we will focus on in this section.
In naive SRTP implementations from before the WebRTC era, each video call usually used 4 separate connections:
- RTP for sending voice data
- RTCP for sending the control of the voice data
- RTP for sending video data
- RTCP for sending the control of the video data
While WebRTC can support this kind of craziness, it also uses rtcp-mux and BUNDLE. These two effectively bring us down to a single connection for voice, video, media and its control.
What happens though is this -
- You create a peer connection
- Then you add media tracks to it, effectively instructing it on what it is about to send or receive (or at least what you want it to send or receive)
- WebRTC will then allocate and bind local IP addresses and ports to handle that traffic. As with outgoing TCP connections, the local ports are going to be arbitrary and ephemeral
- The allocated IP:port addresses are now going to be used in the SDP being negotiated. These will be used as the local candidates
Since these addresses and ports are local, there’s high probability that they will be blocked by firewalls for incoming traffic.
Media servers work in the exact same way with a few differences. In most cases, the addresses that they will use will be public IP addresses, but the ports will be arbitrary. That’s because media servers usually prefer handling each incoming device/stream separately, by receiving its traffic on a dedicated socket connected to a specific port.
STUN “connections” and addresses
Since we’re all behind NATs with our private IP addresses, we need to know our public IP address so we can connect to others directly (peer-to-peer).
To do that, STUN is used. WebRTC will take the media's local IP:port address it created (in that section above), and use it to “connect” over UDP to a STUN server.
This is in concept somewhat similar to how our signaling works - the local IP address has an arbitrary port, while the remote IP:port is known - and configured in advance in our peer connection iceServers. My advice? Have that port be 443.
Why do we do all that with STUN? So that we create a pinhole through the NAT which will allocate for us a public IP address (and port). The STUN server will respond back with the IP address and port it saw, and we will publish that so that the other side will attempt reaching out to us on that public IP:port pair. If the NAT allows such binding, then we will have our session established.
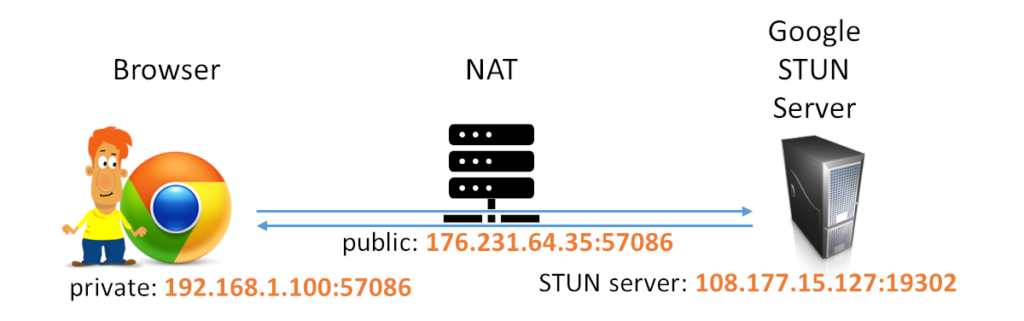
The above shows how Google’s STUN server works from my machine in a sample application:
- My private address was 192.168.1.100:57086
- The STUN address in the iceServers was 108.177.15.127:19302 (the 19302 is the static port Google decided to use - go figure)
- My public IP address as was allocated by the NAT was 176.231.64.35:57086 (it managed to maintain and mirror my internal arbitrary port, which might not always be the case). This is the address that will get shared with the other participant of the session
TURN connections, addresses and port ranges in WebRTC
With TURN, the server is relaying our media towards the other user. For that to happen, my browser needed to:
- Connect to a TURN server
- Ask the TURN server to allocate an address for the relay (and let me know what that address is)
- Use that address for incoming and outgoing traffic for the remote participant of the session
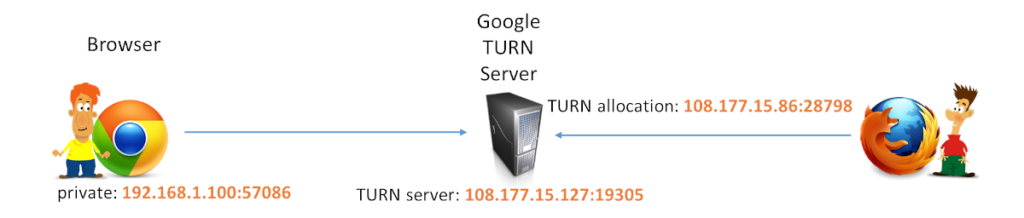
The above shows how Google’s TURN server works from my machine in AppRTC (AppRTC as well as Google's TURN servers are no longer available):
- My private IP for this session was 192.168.1.100:57086 (it was a different port, but I was too lazy to look it up, so bear with me)
- The STUN address in the iceServers was 108.177.15.127:19305 (as with STUN, the 19305 is the static port Google decided to use - still not sure why)
- The TURN server replied back with an allocation address of 108.177.15.86:28798. This was then placed as my ICE candidate. If the remote participant were to send media towards that address, the TURN server would forward that data to me
UDP, TCP and TLS work similarly in TURN when it comes to address and port allocation. What is important to notice here is how the TURN server opens up and allocates ports on its public IP address whenever someone tries to connect through it.
Understanding port ranges in WebRTC configurations
WebRTC makes use of a range of addresses, ports and transport protocols. Far more than anything else that we run in our browsers. As such, it can be quite complex to grasp. I cover how this fits together in my Advanced WebRTC Architecture course. There is order and logic in this chaos - this isn’t something inflicted on you because someone wanted to be mean.
In WebRTC the addresses and ports that get allocated by the end devices (=browsers), media servers and TURN servers are dynamic. This means that in many cases we have to deal with port ranges.
Go to any voice or video conferencing service running over the Internet. Search for their address and port configuration. They all have that information in their knowledgebase. A list of addresses and ports you need to open in your firewalls, written nicely on a page so that the IT guy will be able to copy it to his firewall rules.
Should these ranges be large? As in 49,152 to 65,535? Should this range be squeezed down maybe?
I’ve seen vendors creating a port range of 10 or 100 ports. That’s usually too little to run in scale when the time comes. I’d go with a range of 10,000 ports or more. I’d probably also try first to estimate the capacity of the machine in question and figure out if more ports might be needed to maintain the sessions per second I am planning on supporting (allocated TCP ports take some time to clear up).
Is this “wholesale” port range a real security threat or just an imaginary one? How do you go about explaining the need to customers who like their networks all clamped down and closed?
-
If you are looking to learn more about WebRTC, check out my WebRTC training courses. In the near future, I will start working on a new course about TURN installation and configuration - if you are interested in early access - do let me know.
