
Soda and Mentos.
Last week I wrote about the difference between WebRTC and VoIP development. This week let’s see how WebRTC development is different from web development.
Let’s start by saying this for starters:
WebRTC is about Web Development
Well, mostly. It is more about doing RTC (real time communications). And enabling to do it over the web. And elsewhere. And not necessarily RTC.
WebRTC is quite powerful and versatile. It can be used virtually everywhere and it can be used for things other than VoIP or web.
When we do want to develop WebRTC for a web application, there are still differences - in the process, tools and infrastructure we will need to use.
Why is that?
Because real time media is different and tougher than most of the rest of the things you happen to be doing on the browser itself.
It boils down to this illustration (from last week):
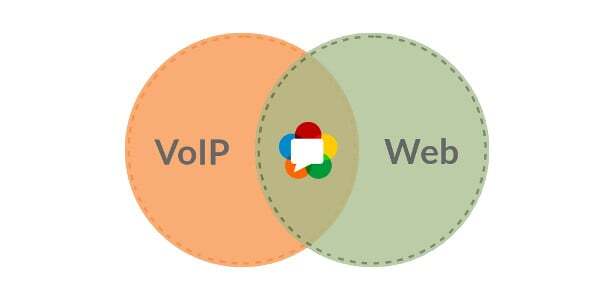
So yes. WebRTC happens to run in the web browser. But it does a lot of things the way VoIP works (it is VoIP after all).
If you want to learn more about the challenges of group calling in WebRTC, then this free 5-part video course on Mastering Group Call Performance in WebRTC SFUs is exactly for you.
If you plan on doing anything with WebRTC besides a quick hello world page, then there’s lots of new things for you to learn if you’re coming from a web development background. Which brings me to the purpose of this article.
If you are looking for WebRTC talent, make sure to also read my WebRTC hiring tips!
Here are 10 major differences between developing with WebRTC and web development:
#1 - WebRTC is P2P
Seriously. You can send voice, video and any other arbitrary data you wish directly from one browser to another. On a secure connection. Not going through any backend server (unless you need a relay - more on that in #6).
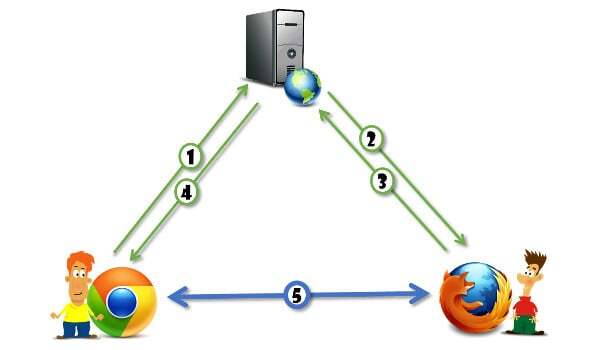
That triangle you see there? For VoIP that’s obvious. But for the web that’s magical. It opens up a lot of avenues for new types of services that are unrelated to VoIP - things like WebTorrent and Peer5; The ability to send direct private messages; low latency game controllers; the alternatives here are endless.
But what does this triangle mean exactly?
It means that you are not going to send your media through a web server. You are going to either send it directly between the browsers. Or you are going to send it to a media server - dedicated to this task.
This also means that a lot of the things you’ll need to keep track of and monitor don’t even get to your servers unless you do something about it to make it happen.
#2 - It isn’t all Javascript and JSON
Yes. I know last time I said it is all Javascript.
But if what you know is limited to Javascript then life is going to be a world of pain for you with WebRTC.
Media servers for example are almost always developed using C/C++ or Java. If you’ll need to debug them (and the serious companies do that), then you’ll need to understand these languages as well.
The second part is more JSON and less Javascript related - there’s one part of WebRTC that is ugly as hell but working. That’s the SDP that is used in the offer-answer negotiation process.
Besides being hard to interpret (different people understand SDP differently which later means they develop parsers and code for it differently), SDP is also hard to parse using Javascript. It isn’t built as a JSON blob, so the code to fetch a field or modify a field in SDP isn’t trivial (doable, but a pain).
#3 - There’s This Thing Called UDP
I guess this is the start of the following points as well, so here we go.
Today, the web is built on top of TCP. It started with HTTP. Moved to Websockets (also on top of TCP). And now HTTP/2 (also TCP).
There are attempts to allow for UDP type of traffic - QUIC is an example of it. But that isn’t there yet. And for most web developers that’s just under the hood anyway.
With WebRTC, all media is sent over UDP as much as possible. It can work over TCP if needed (I sent you to #6 didn’t I?), but we try to refrain for it - you get better media quality with UDP.
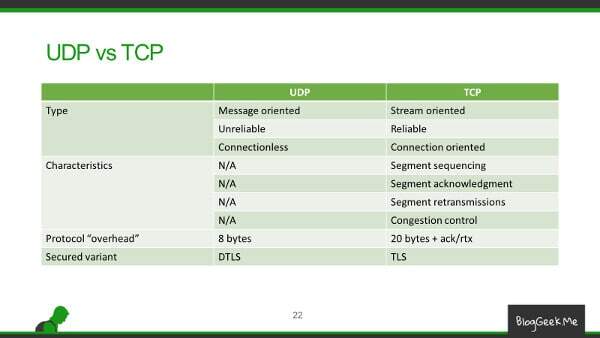
The table above shows the differences between UDP and TCP. This lies at the heart of how media is sent. We use unreliable connections with best effort.
#4 - Compromise is the Name of the Game
That UDP thing? It adds unreliability into the mix. Which also means that what you send isn’t what you get. Coupled with the fact that codecs are resource hogs, we get into a game of compromise.

In VoIP (and WebRTC), almost any decision we make to improve things in one axis will end up costing us in another axis.
Want better compression? Lose quality.
Don’t want to lose quality? Use more CPU to compress.
Want to lower the latency? Lose quality (or invest more CPU).
On and on it goes.
While CPUs are getting better all the time, and available bandwidth seems to be getting higher as well, our demand of our media systems is growing just as well. At times even a lot faster.
That ends up with the need to compromise.
All the time.
You’ll need to know and understand media and networking in order to be able to decide where to compromise and where to invest.
#5 - Best Effort is the Other Name

Here’s something I heard once in a call I had:
“We want our video quality to be a lot better than Skype and Hangouts”.
I am fine with such an approach.
But this is something I heard from:
- 2 entrepreneurs with no experience or understanding if video compression
- For a use case that needs to run in developing countries, with choppy cellular reception at best
- And they assumed they will be able to do it all by themselves using WebRTC
It just doesn’t work.
WebRTC (and VoIP) are a best effort kind of a play.
You make do with what you get, trying to make the best of it.
This is why WebRTC tries to estimate the bandwidth available to it, and will then commence eating up all that available bandwidth to improve the video quality.
This is why when the network starts to act (packet loss), WebRTC will reduce the bitrate it needs and reduce the media quality in order to accommodate what is now available to it.
Sometimes these approaches work well. Other times not so well.
And yes. A lot of the end result will be reliant on how well you’ve designed and laid out your infrastructure for the service.
#6 - NAT Traversal Rules Your Life
Networks have NATs and Firewalls. These are nothing new, but if you are a web developer, then most likely they never did make life any difficult for you.
That’s because in the “normal” web, the browser will reach out to the server to connect to it. And being the main concept of our current day web, NATs and Firewalls expect that and allow this to happen.
Peer to peer communications, direct across browsers, as WebRTC operates. And with the use of UDP no less (again, something that isn’t usually done in the web browser)... these are things that firewalls and the IT personnel configuring them usually don’t need to contend with.

For WebRTC, this means the addition of STUN/TURN servers. Sometimes, you’ll hear the word ICE. ICE is an algorithm and not a server. ICE makes use and STUN and TURN. STUN and TURN are two protocols for NAT traversal, each using its own server. And usually, STUN and TURN servers are implemented in the same code and deployed using a single process.
WebRTC is doing a lot of effort to make sure its sessions will get connected. But at the end of the day, even that isn’t always enough. There are times when sessions just can’t get connected - whoever configured the firewall made sure of it.
#7 - Server Scaling is Ridiculous
Server scaling with WebRTC is slightly different than that of regular web.
There are two main reasons for that:
- The numbers are usually way smaller. While web servers can handle 5 digit connections or more, their WebRTC counterparts will often struggle with the higher end of 3 digits. There’s a considerable cost of hosting HD video and media server processing
- WebRTC requires statefulness. Severing a connection and restarting it will always be noticeable - a lot more than in most other web related use cases. This makes high availability, fault tolerance, upgrading and similar activities harder to manage with WebRTC
You’ll need to understand how each of the WebRTC servers work in order to understand how to scale it.
#8 - Bandwidth is Expensive
With web pages things are rather simple. The average web page size is growing year to year. We’ve got above 2.3MB in 2016. But that page is constructed out of different resources pulled from different servers. Some can be cached locally in the browser.
A 5 minute HD video at 2Mbps (not unheard of and rather common) will take up 75 MB during that 5 minutes.
If you are just doing 1:1 video calls with a 10% TURN relay factor, that can be quite taxing - running just 1,000 calls a day with an average of 5 minutes each will eat up 15 GB a day in your TURN server bandwidth costs. You probably want more calls a day and you want them running for longer periods of time as well.
Using a media server for group calling or recording makes this even higher.
As an example, at testRTC we can end up with tests that run into the 100’s of GBs of data per test. Easily…
When you start to work out your business model, be sure to factor in your bandwidth costs.
#9 - Geography is Everything for Media Delivery
For the most part, and for most services, you can get away with running your service off a specific data center.
This website of mine is hosted somewhere in the US (I don’t even care where) and hooked up to CDN services that take care of the static files. It has never been an issue for me. And performance is reasonable.
When it comes to real time live media, which is where WebRTC comes in, this won’t always do.
Getting data from New York to Paris can easily take 100 milliseconds or more, and since one of the things we’re striving for is real time - we’d like to be able to reduce that as much as we can.
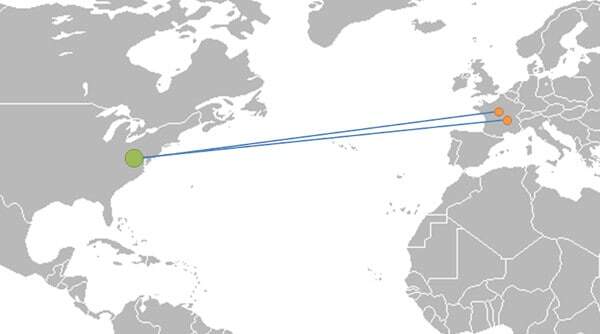
Which gets us to the illustration above. Imagine two people in Paris having a WebRTC conversation that gets relayed through a TURN server in New York. Not even mentioning the higher possibility of packet losses, there’s clearly a degradation in the quality of the call just by the added delay of this route taken.
WebRTC, even for a small scale service, may need a global deployment of its infrastructure servers.
#10 - Different Browsers Behave Differently
Well… you know this one.
As a web developer, I am sure you’ve bumped into browsers acting differently with your HTML and CSS. Just recently, I tried to use <button> outside of a form element, only to find out the link that I placed inside it got ignored by Firefox.
The same is true for WebRTC. The difference is that it is a lot easier to bump into and it messes things up in two different levels:
- The API behavior - not all browsers support the exact same set of APIs (WebRTC isn’t really an official standard specification yet - just a draft; and browser implementations mostly adhere to recent variants of that draft)
- The network behavior - WebRTC means you communicate between browsers. At times, you might not get a session connected properly from one browser to another if they are different. They process SDP differently, they may not support the same codecs, etc.
As time goes by, this should get resolved. Browser vendors will shift focus from adding features and running after the specification towards making sure things interoperate across browsers.
But until then, we as developers will need to run after the browsers and expect things to break from time to time.
#11 - You Know More Than You Think
The majority of WebRTC is related to VoIP. That’s because at the end of the day, is it a variant of VoIP (one of many). This means that VoIP developers have a huge head start on you when it comes to understanding WebRTC.
The problem for them is that they have a different education than you do. Someone taught them that a call has a caller and a callee. That you need to be able to put a call on hold. To transfer the call. To support blind transfer. Lots and lots of notions that are relevant to telephony but not necessarily to communications.
You aren’t “tainted” in this way. You don’t have to unlearn things - so that nagging part of an ego telling you how things are done with VoIP - it doesn’t exist. I had my share of training sessions where most of my time was spent on this unlearning part.
This means that in a way you already know one important thing with WebRTC - that there’s no right and wrong in how sessions are created - and you are free to experiment and break things with it before coming to a conclusion of how to use it.
That’s powerful.
What’s Next?
If you have web development background, then there’s much you need to learn about how VoIP is done in order to understand WebRTC better.
WebRTC looks simple when you start with it. Most web developers will complain after a day or two of how complex it is. What they don’t really understand is how much more complicated VoIP is without WebRTC. We’ve been given a very powerful and capable tool with WebRTC.
If you want to learn more about the challenges of group calling in WebRTC, then this free 5-part video course on Mastering Group Call Performance in WebRTC SFUs is exactly for you.
And if you’re really serious, enroll to my Advanced WebRTC Architecture Course, and if you're looking to grok signaling and WebRTC, then my free WebRTC codelab training is just the thing for you!
