
Before jumping on the ML/AI bandwagon of WebRTC media quality, make sure you’ve exhausted all of your other optimization alternatives.
TL;DR - make sure you optimize for media quality without AI before jumping to using AI...
In 2018 and 2019 at Kranky Geek we’ve started looking at machine learning. We’ve handpicked speakers and sessions who deal with these topics. We’ve done so for both voice and video technologies. The intent and idea behind this was to fit to the times. Everyone’s been doing AI so why not us in the context and domain of WebRTC and communication technologies?
It made perfect sense.
Then came 2020 and… changed everything. No one was really interested in AI or how to improve quality of experience with it. It was now used mainly for bots with the purpose of handling large loads of calls (call deflection and agent assist type technologies).
At times, it seemed like we were all back to basics. We now had to start scratching our heads and see what can be done to improve quality.

At Google and elsewhere, I am sure that a manager somewhere higher up came, saw the work that is being done, received an explanation how research into this machine learning stuff was progressing and showing promise, but in many ways required, well, more research, before it could be seen as anything that is close to being production ready.
And as managers do in these situations, they smack the table and say something like “I want quick wins”. So the developers went back to the basics. Trying to figure out what quick wins they can find to squeeze a bit more quality of that thing they had called WebRTC.
Quite surprisingly - it worked!
There seems to be ample room for optimizations. If you ask me? Someone forgot to try and squeeze this lemon properly.

Google’s optimizations of WebRTC’s code
It started somewhere with the pandemic.
One of the first indications was this tweet by Serge Lachapelle (former product manager for WebRTC at Google and leading Google Meet at the time of tweeting).
Apparently, the video compositor wasn’t making the most out of the hardware it was using…
Since then we’ve seen some additional optimizations, though most of them taking place in the application level on top of the WebRTC implementation itself.
At Kranky Geek, Google discussed at length the optimization work it is working on. Mostly, making sure that video processing doesn’t take up too much CPU.
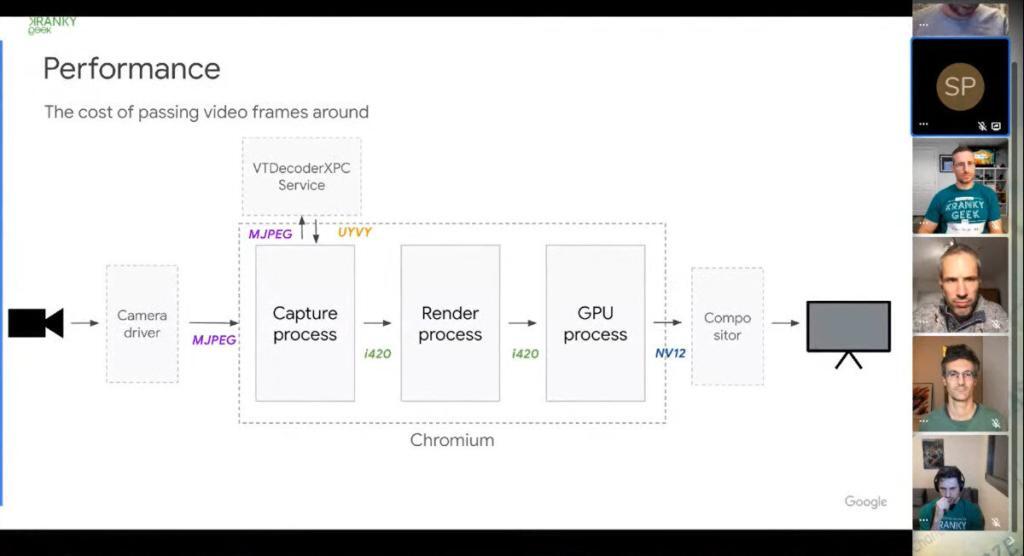
Apparently, Chrome is doing way too many video format conversions between getting the frames from the camera until it encodes and sends it out. Each conversion eats up CPU and I/O, generally killing the whole internal bus of the machine. Oh - and it means memory copies. Lots and lots of memory copies.
Video processing 101: zero copy is what you’re striving for.
We’re 10 years into WebRTC and the leading team behind WebRTC is just now starting to look at zero copying.
There are other areas and aspects where optimizations are taking place. Once the Kranky Geek videos will be ready and published, I’ll add the relevant one here.
Still got optimization juice in this lemon. Expect better performing WebRTC in the coming Chrome releases.
Rushing towards 49-gallery view and 50+ group sizes
As the pandemic hit, Zoom grew. The media was filled with their gallery view.

One use case that didn’t exist before the pandemic is large video calls. Up until today, we used to take these video meetings in the office inside meeting rooms. Cramming a few people in each room in a remote office and doing a call with 2-4 such rooms. Maybe someone joined from home or a hotel. You could see meetings with 10 participants. Sometimes. But the need just wasn’t really there.
The pandemic hit. People are now at home. And communicate with video remotely. A meeting of 4 became a meeting of 20 just because the participants are now sitting at home.
Even worse, schools are now remote. Each class has 20-40 students in it. And the teacher wants to see them all.
This made Zoom’s gallery view so popular (even if a tad useless if you ask me). It also made the magical number 49 magical. The holy grail of what is needed of a video conferencing service in a pandemic. Doesn’t matter if everyone is muting their video.
49.
Microsoft and Google announced plans for supporting it. Then started running towards that value, each rising in the number of tiles in his gallery, reaching 49 recently.
Facebook grew from a meeting of 8 to meetings of 50.
Meetings are larger and longer now.
And again, we found the ways to make it happen with WebRTC.
Best practices on group video scaling being rewritten
There are a lot of mechanisms in WebRTC that enable an application to squeeze the lemon and gain back CPU cycles as it tries to optimize for larger group calls.
But we never did have a place where all these are found and explained. A body of knowledge and understanding of how to make it happen.
I’ve been in such conversations multiple times with multiple clients and developers. I’ve hosted a workshop on the topic and write an ebook on optimizing group video calls. Even went as far as building rtcstats.com with partners.
In my recent/upcoming update to the Advanced WebRTC Architecture course there’s a lesson dedicated to this specific topic. It isn’t as if the information isn’t there in the course - it is spread all over the course. But now there’s a lesson on this alone. Because it became interesting only in 2020.
We have traded the focus on what is important to us with video communications. A video conference’s scale trumps quality at the moment. While I do understand we all want both all the time, but there is still a tradeoff between these two qualities of a system.
The role of machine learning and AI in communications
Where does one fit machine learning and AI in this brave new world of large video conference calls?
Machine learning requires memory and CPU. Things we don’t have to spare at the moment in these large group calls. So we can’t just slap machine learning inference algorithms on the edge inside the web browser easily.
Edge inference in web browsers using WebAssembly is also brand new. So there’s no guide book to work with.
We won’t be using it to improve video quality or audio quality in the edge - we can’t really. Not enough CPU to spare.
There’s no real place for it on the server side either - that one requires decoding and encoding which are going to be CPU intensive and increase the costs of delivering the service. Pexip is doing that for auto zoom, but that’s because they are built as an MCU. Google decided to do this for noise suppression.
An interesting development is the focus on AI-powered audio codecs. Both Microsoft and Google announced new voice codecs around this trend - Satin from Microsoft and Lyra from Google.
There’s packet loss concealment using machine learning now. And you can do super resolution for video to get better video quality. But in the end, all these are going to make a difference once CPUs have their own dedicated, standardized AI accelerators, like the new Apple M1 chip in them brand new Intel-less MacBooks. We just don’t have cycles to spare.
Which is why media quality has gone back to its roots. Here’s something I have in that workshop of mine:

Machine learning should be added once we’re done squeezing that lemon for more performance and quality.
Google is now doing its part of optimizing the WebRTC codebase itself. It is your role to do it in your own infrastructure and application. Once done, the time will come to introduce some machine learning chops into it.
Until then? We need machine learning for two main tasks, and we see it already:
- Background blur and background replacements. We’re all humans but somehow we don’t want our kids to be in the way of our conversations
- Noise suppression. As we’re stuck at home, we can’t really control that crying kid of ours on the other side of the room
Where to start with AI in communications?
Does that mean you don’t need to invest in machine learning?
Hell no. you definitely MUST invest in machine learning.
Not for what you’ll be doing in 2021, but for what you’ll be launching in your product in early 2022. Which brings me to the heart of it all.
Machine learning is new and challenging. We’re still writing the playbook of what it means to use it for real time communications, inside a browser, using technologies such as WebAssembly.
You’ll need to decide on which use cases to invest, and what value you are going to derive of it. And you’ll need to plan for the long game here and be patient until you get results.
There’s a need to let the teams driving machine learning do the research and experimentation needed. But at the same time, they need guidance in where to look at and what to experiment with.
