
There are multiple ways to implement WebRTC multiparty sessions. These in turn are built around mesh, mixing and routing.
In the past few days I've been sick to the bone. Fever, headache, cough - the works. I couldn't do much which meant no writing an article either. Good thing I had to remove an appendix from my upcoming WebRTC API Platforms report to make room for a new one.
Architectures in WebRTC
I wanted to touch the topic of Flow and Embed in Communication APIs, and how they fit into the WebRTC space. This topic will replace an appendix in the report about multiparty architectures in WebRTC, which is what follows here - a copy+paste of that appendix:
Multiparty conferences of either voice or video can be supported in one of three ways:
- Mesh
- Mixing
- Routing
The quality of the solution will rely heavily on the different type of architecture used. In Routing, we see further refinement for video routing between multi-unicast, simulcast and SVC.
WebRTC API Platform vendors who offer multiparty conferencing will have different implementations of this technology. For those who need multiparty calling, make sure you know which technology is used by the vendor you choose.
Mesh
In a mesh architecture, all users are connected to all others directly and send their media to them. While there is no overhead on a media server, this option usually falls short of offering any meaningful media quality and starts breaking from 4 users or more.
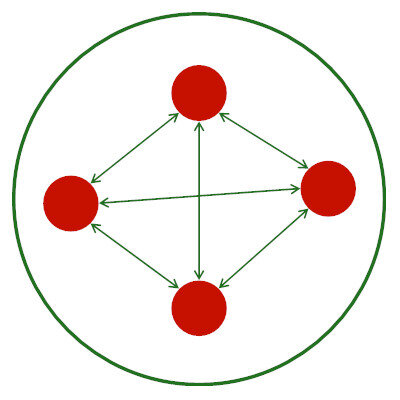
For the most part, consider vendors offering mesh topology for their video service as limited at best.
There's more to know about WebRTC P2P mesh architecture.
Mixing
MCUs were quite common before WebRTC came into the market. MCU stands for Multipoint Conferencing Unit, and it acts as a mixing point.
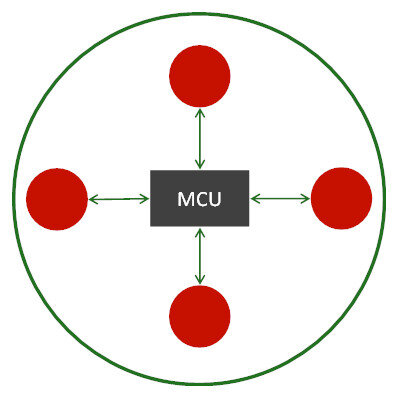
An MCU is a WebRTC media server that receives the incoming media streams from all users, decodes it all, creates a new layout of everything and sends it out to all users as a single stream.
This has the added benefit of being easy on the user devices, which see it as a single user they need to operate in front; but it comes at a high compute cost and an inflexibility on the user side.
Routing
SFUs were new before WebRTC, but are now an extremely popular solution. SFU stands for Selective Forwarding Unit, and it acts like a router of media.
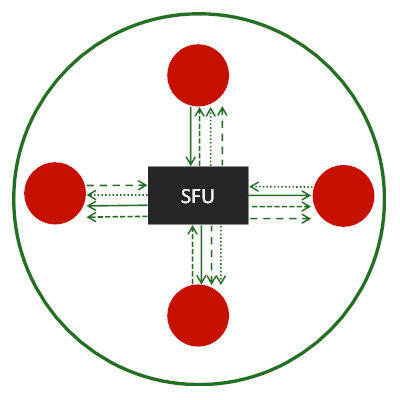
An SFU is a WebRTC media server that receives the incoming media streams from all users, and then decides which streams to send to which users.
This approach leaves flexibility on the user side while reducing the computational cost on the server side; making it the popular and cost effective choice in WebRTC deployments.
To route media, an SFU can employ one of three distinct approaches:
- Multi-unicast
- Simulcast
- SVC
Multi-unicast
This is the naïve approach to routing media. Each user sends his video stream towards he SFU, which then decide who to route this stream to.
If there is a need to lower bitrates or resolutions, it is either done at the source, by forcing a user to change his sent stream, or on the receiver end, by having the receiving user to throw data he received and processed.
It is also how most implementations of WebRTC SFUs were done until recently. [UPDATE: Since this article was originally written in 2017, that was true. In 2019, most are actually using Simulcast]
Simulcast
Simulcast is an approach where the user sends multiple video streams towards the SFU. These streams are compressed data of the exact same media, but in different quality levels – usually different resolutions and bitrates.
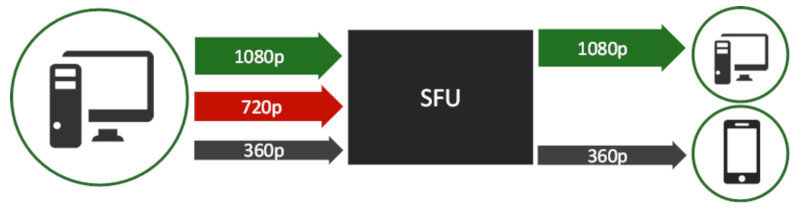
The SFU can then select which of the streams it received to send to which participant based on their device capability, available network or screen layout.
Simulcast has started to crop in commercial WebRTC SFUs only recently.
SVC
SVC stands for Scalable Video Coding. It is a technique where a single encoded video stream is created in a layered fashion, where each layer adds to the quality of the previous layer.
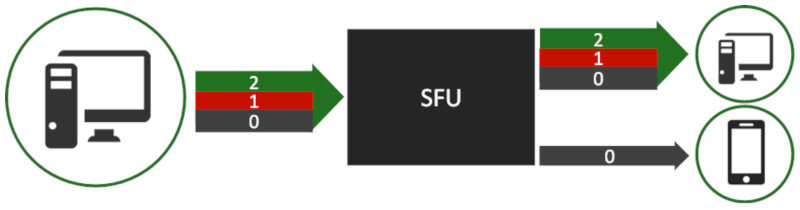
When an SFU receives a media stream that uses SVC, it can peel of layers out of that stream, to fit the outgoing stream to the quality, device, network and UI expectations of the receiving user. It offers better performance than Simulcast in both compute and network resources.
SVC has the added benefit of enabling higher resiliency to network impairments by allowing adding error correction only to base layers. This works well over mobile networks even for 1:1 calling.
SVC is very new to WebRTC and is only now being introduced as part of the VP9 video codec.
