Here's how you handle multipoint for large groups using WebRTC.
This is the third post dealing with multipoint:
- Introduction
- Broadcast
- Small groups
- Large groups (this post)
-
It is time to discuss the real multipoint solution – large groups. And for that, I'd like to start with a quick glossary of a few terms:
- EVC – Enterprise Video Conferencing. A made-up term for this post to denote… what video conferencing is in enterprises today. Think of solutions coming from Polycom, Cisco, …
- MCU – Multipoint Conferencing Unit. The "box" on the data center that provides multi point support for both small and large groups
- Port – a term used by EVC vendors for their MCUs to denote an encoder in the box – the more ports you have, the more calls (and the larger calls) you can support
When we deal with server side multipoint video processing, there are two ways to implement it:
- Server does all, sending the endpoints the exact video stream they should be viewing (a single stream)
- Server sends multiple streams to the endpoints, delegating some of the work to them
Let's start with the first option then. In this case, the media processing path looks something like this:
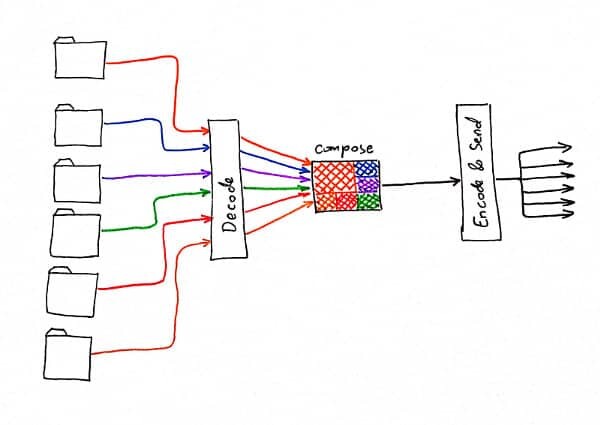
The server side gets all media streams. It decodes them. Decides how to create the layout of the end video stream. Encodes it and sends it to the participants.
It can do so by sending a different view to each participant (omitting the sender for example), in which case it is called "encoder per participant". It can decide to switch layouts, display a single speaker each time, etc.
There are some levels of freedom here – each one increases or decreases the complexity of the implementation: The MCU can reduce the effort it has by asking each endpoint to send an exact resolution and frame rate; it can work out only "simple" layouts, etc.
This option is classic in EVC, because it requires very little effort from the endpoints – they almost always assume it is a simple point-to-point call.
While the result is of high quality, it usually won't cut it for WebRTC use cases… the cost is too high.
The other option we have is going for multiple streams – something similar to what Google Hangout provides. In such a case, there is work that is relegated to the endpoints themselves – like deciding on the best layout to display and decoding multiple incoming streams. Here, the server will try to refrain as much as possible from decoding and re-encoding the content and instead act as a relay of the media.
I have no clue how different implementations of WebRTC deal with such a use case – do they require each incoming stream to be on a separate session, allow all streams to be part of a single session from the server side, or not support it at all. If you know – feel free to share your knowledge here.
Which of the two work best for WebRTC?
I don't know. My gut feeling? The second option: we have more control over the client side and can relegate more of the work from the server. This reduces the cost of deploying the server in the first place and allows scaling better and supporting more use cases.
