
In group calls there are different ways to decide on WebRTC server allocation. Here are some of them, along with recommendations of when to use what.
In WebRTC group calling, media server scaling is one of the biggest challenges. There are multiple scaling architectures that are used, and most likely, you will be aiming at a routing alternative, where media servers are used to route media streams around between the various participants of a session.
As your service grows, you will need to deal with scale:
- Due to an increase in the number of users in a single session
- Because there’s a need to cater for a lot more sessions concurrently
- Simply due to the need to support users in different geographical locations
In all these instances, you will have to deal with the following challenge: How do you decide on which server to allocate a new user? There are various allocation schemes to choose from for WebRTC group calling. Each with its own advantages and challenges. Below, I’ll highlight a few such schemes to help you with implementing the WebRTC allocation scheme that is most suitable for your application.
Single data center allocation techniques

First things first. Media servers in WebRTC don’t scale well. For most use cases, a single server will be able to support 200-500 users. When more than these numbers are supported, it will usually be due to the fact that it sends lower bitrates by design, supports only voice or built to handle only one way live streaming scenarios.
This can be viewed as a bad thing, but in some ways, it isn’t all bad - with cloud architectures, it is preferable to keep the blast radius of failures smaller, so that an erroneous machine ends up affecting less users and sessions. WebRTC media servers force developers to handle scaling earlier in their development.
Our first order of the day is usually going to be deciding how to deal with more than a single media server in the same data center location. We are likely to load-balance these media servers through our signaling server policy, effectively associating a media server to a user or a media stream when the user joins a session. Here are a few alternatives to making this decision.
Server packing

This one is rather straightforward. We fill out a media server to capacity before moving on to fill out the next one.
Advantages:
- Easy to implement
- Simple to maintain
Challenges:
- Increase blast radius by design
- Makes little use of other server resources that are idle
Least used
In this technique, we look for the media server that has the most free capacity on it and place the new user or session on it.
Advantages:
- Automatically balances resources across servers
Challenges:
- Requires the allocation policy to know all sever’s capacities at all times
Round robin
Our “don’t think too much” approach. Allocate the next user or session to a server and move on to the next one in the list of servers for the next allocation.
Advantages:
- Easy to implement
Challenges:
- Feels arbitrary 🙂
Random
Then there’s the approach of picking up a server by random. It sounds reckless, but in many cases, it can be just as useful as least used or round robin.
Advantages:
- Easy to implement
Challenges:
- Feels really arbitrary 😃
Region selection techniques

The second part is determining which region to send a session or a user in a session to.
If you plan on designing your service around a single media server handling the whole session, then the challenge is going to be where to open a brand new session (adding more users takes place on that same server anyway). Today, many services are moving away from the single server approach to a more distributed architecture.
Lets see what our options are here in general.
First in room
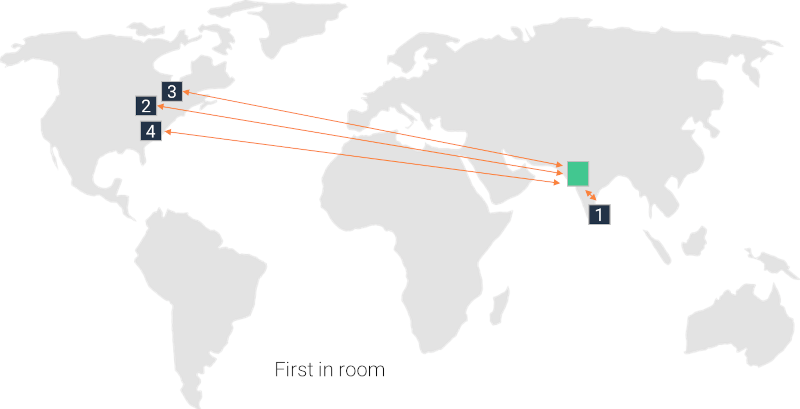
The first user in a session decides in which region and data center it gets created. If there are more than a single media server in that data center, then we go with our single data center allocation techniques to determine which one to use.
This is the most straightforward and naive approach, making it almost the default solution many start with.
Advantages:
- Easy to implement
Challenges:
- Group sizes are limited by a single machine size and scale
- If the first user to join is located from all the rest of the users, then the media quality will be degraded for all the rest of the participants
- It makes deciding capacities and availability of resources on servers more challenging due to the need to reserve capacity for potential additional users
👉 Note that everything has a solution. The solutions though makes this harder to implement and may degrade the user experience in the edge cases it deals with.
Application specific
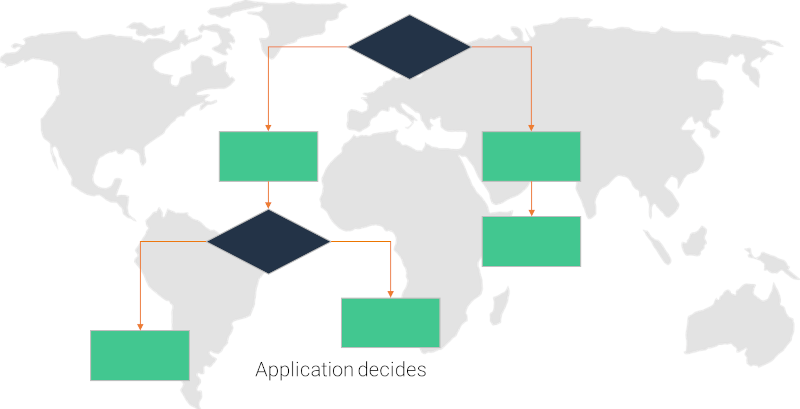
You can pick the first that joins the room to make the decision of geolocation or you can use other means to do that. Here, the intent is to use something you know in your application in advance to make the decision.
For example, if this is a course lesson with the teacher joining from India and all the students are joining from the UK, it might be beneficial to connect everyone to a media server in the UK or vice versa - depending on where you want to put the focus.
A similar approach is to have the session determine the location by the host (similar to first in room) or be the configuration of the host - at account creation or at session creation.
Advantages:
- Usually easy to implement
Challenges:
- Group sizes are limited by a single machine size and scale
- It makes deciding capacities and availability of resources on servers more challenging due to the need to reserve capacity for potential additional users
- Not exactly a challenge, but mostly an observation - to some applications, the user base is such that creating such optimizations makes little sense. An example can be a country-specific service
Cascading
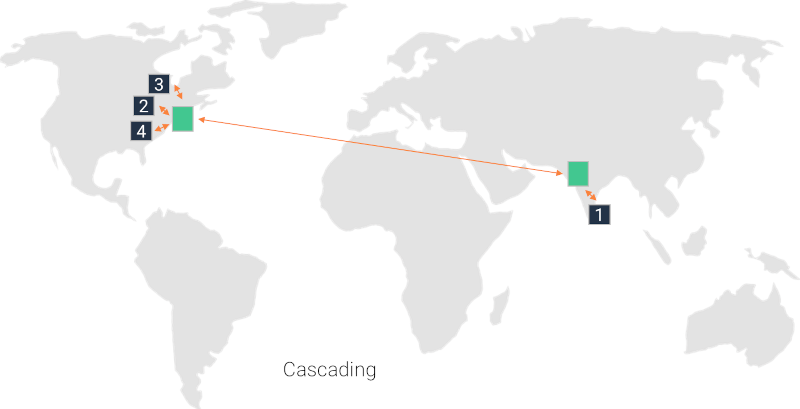
Cascading is also viewed as distributed/mesh media servers architecture - pick the name you want for it.
With cascading, we let media servers communicate with each other to cater for a single session together. This approach is how modern services scale or increase media quality - in many ways, many of the other schemes here are “baked” into this one. Here are a few techniques that are applicable here:
- Always connect a new user to the closest media server available. If this media server isn’t already part of the session, it will be added to the session by meshing it with the other media servers that cater for this session
- When capacity in a media server is depleted, add a new user to a session by scaling it horizontally in the same data center with one of the techniques described in single data server allocation at the beginning of this article
- In truly large scale sessions (think 10,000 users or more), you may want to entertain the option of creating a hierarchy of media servers where some don’t even interact with end users but rather serve as relay of media between media servers
Advantages:
- Can achieve the highest media quality per individual user
Challenges:
- Hard to implement
- Usually requires more server resources
Sender decides
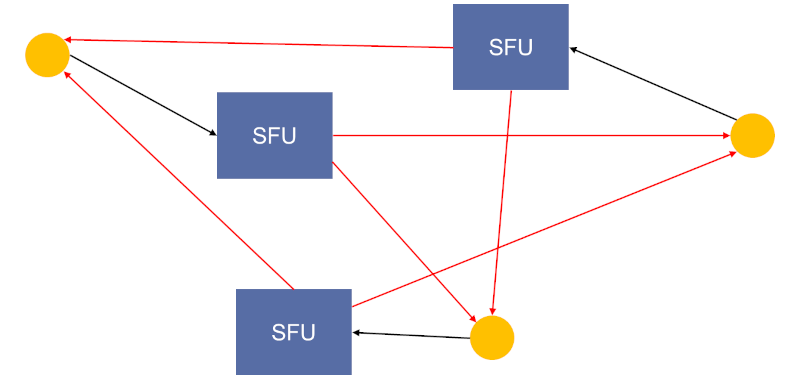
This one surprised me the first time I saw it. In this approach, we “disconnect” all incoming traffic from outgoing and treat each of them separately as if it were an independent live stream.
What does that mean? When a user joins, he will always connect to the media server closest to them in order to send their media. For the incoming media from other users, he will subscribe to their streams directly on the media servers of those users.
Advantages:
- Rather simple to implement
Challenges:
- Doesn’t use good inter-data center links between the servers
- Doesn’t “feel” right. Something about the fact that not a single media server knows the state of the user’s device bothers me in how you’d optimize things like bandwidth estimation in this architecture
A word about allocation metrics

One thing I ignored in all this is how do you know when a server is “full”. This decision can be done in multiple ways, and I’ve seen different vendors take different approaches here. There are two competing aspects here to deal with:
- Utilization - we want our servers to be utilized to their fullest. Resources we pay for and not use are wasted resources
- Fragmentation - if we cram more users on servers, we may have a problem when a new user joins a session but has no room on the media server hosting that session. So at times, we’d like to keep some slack for such users. The only question is how much slack
Here are a few examples, so you can make an informed decision on your end:
- Number of sessions. Limit the number of sessions on a server, no matter the number of users each session has. Good for services with rather small and predictable session sizes. Makes it easier to handle resource allocations in cases of server fragmentation
- Number of users. Limit the number of users a single server can handle
- CPU. Put a CPU threshold. Once that threshold is breached, mark the media server as full. You can use two thresholds here - one for not allowing new sessions on the server and one for not allowing any more users on the server
- Network. Put a network threshold, in a similar way to what we did above for CPU
Sometimes, we will use multiple metrics to make our allocation decision.
Final words
Scaling group calls isn’t simple once you dive into the details. There are quite a few WebRTC allocation schemes that you can use to decide where to place new users joining group sessions. There are various techniques to implement allocation of users in group calling, each with its own advantages and challenges.
Pick your poison 🧪
👉 One last word - this article was written based on a new lesson that was just added to the Advanced WebRTC Architecture course. If you are looking for the best WebRTC training, then check out my WebRTC Courses.
