
What was nice to have is now becoming mandatory in WebRTC video calling applications. This includes background blurring, but also a lot of other features as well.
Do you remember that time not long ago that 16 participants on a call was the highest number that product managers asked for? Well… we’re not there anymore. In many cases, the number has grown. First to 49. Then to a lot more, with nuances on what exactly does it mean to have larger calls. We now see anywhere between 100 to 10,000 to be considered a “meeting”.
I’ve been talking and mentioning table stakes for quite some time - during my workshops, on my messages on LinkedIn, in WebRTC Insights. It was time I sat down to write it on my blog ✍️
WebRTC table stakes
This isn’t really about WebRTC, but rather what users now expect from WebRTC applications. These expectations are in many cases table stakes - features that are almost mandatory in order to be even considered as a relevant vendor in the selection process.
What you’ll see here is almost the new shopping list. Since users are different, markets are different, scenarios are different and requirements vary - you may not need all of them in your application. That said, I suggest you take a good look at them, decide which ones you need tomorrow, which you don’t need and which you have to get done yesterday.
Background blurring/replacement
Obvious. I have a background replacement. I never use it in my own calls. Because… well… I like my background. Or more accurately - I like showing my environment to people. It gives context and I think makes me more human.

This isn’t to say people shouldn’t use background replacement or that I’ll hate them for doing that - just that for me, and my background - I like keeping the original.
Others, though, want to replace their background. Sometimes because they don’t have a proper place where the background isn’t cluttered or “noisy”. Or because they just want to have fun with it.

Whatever the reason is, background blurring and replacement are now table stakes - if your app doesn’t have it, then the app that does in your market will be more interesting and relevant to the buyers.
Here’s how I see the development of the requirements here:
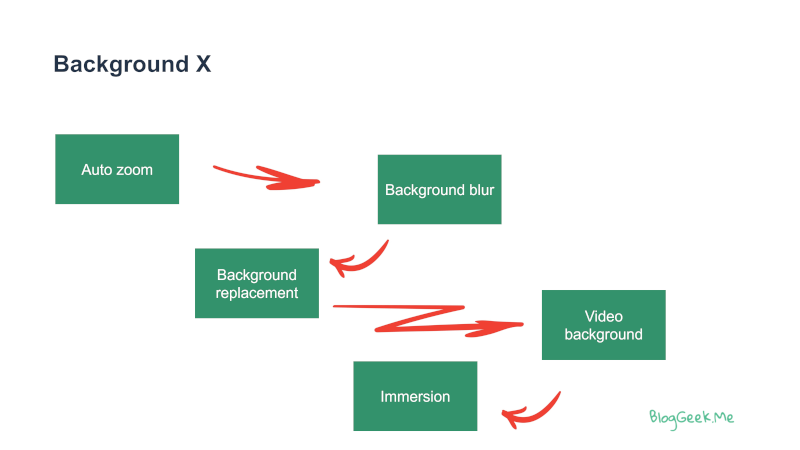
- Figure out where a user is. Here, you can even implement an auto zoom capability (many skip this, though this can be quite useful as well)
- Then focus on background blurring. It is the most tolerant of the alternatives
- Move on to background replacement. Replace the background with a static image
- Go for video backgrounds, where the user can replace the background with something moving
- Think of “teleporting” the user after you’ve cut him away from his background to place him directly on a slide deck or in a virtual environment
Video lighting
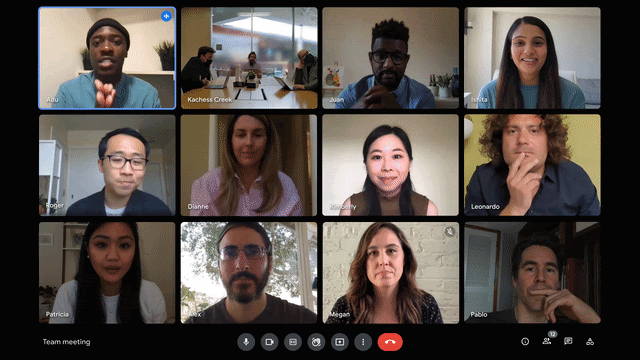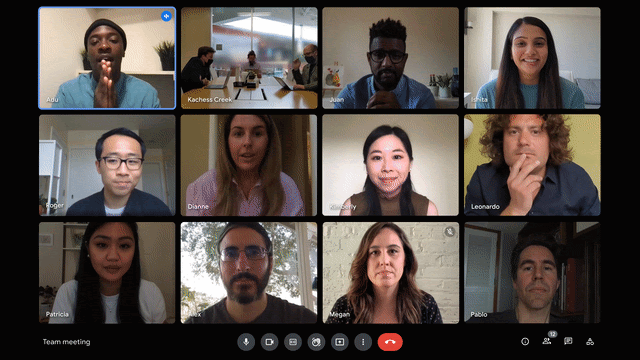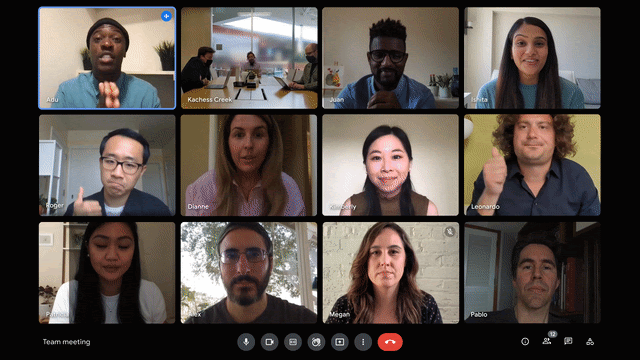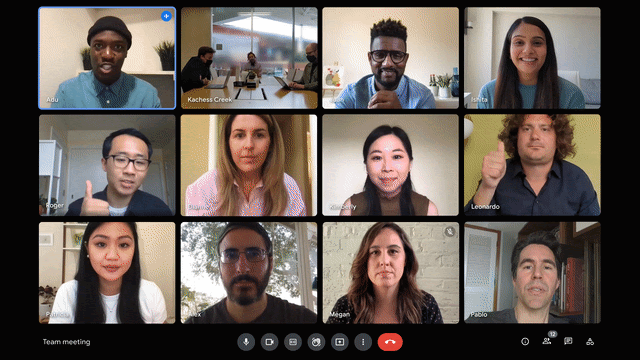
If I recall correctly, Google Meet started with this feature, and since then it started cropping into other meeting solutions. We all use webcams, but none of us has good lighting. It might be a window behind (or in my case to the side), the weather out the window, the hour in the day, or just poor lighting in the room.
While this can be fixed, it isn’t. Much like the cluttered room, the understanding is that humans are lazy or just not up to the task of understanding what to do to improve video lighting on their own. And just like background removal, we can employ machine learning to improve lighting on a video stream.
Noise suppression/cancellation

I started using this stock image when I started doing virtual workshops. It is how I like to think of my nice neighbor (truth be told - he really is nice). It just seems that every time I sit down for an important meeting, he’d be on one of his renovation sprees.
The environment in which we’re conducting our calls is “polluted” with sounds. My mornings are full with lawn mower noises from the park below my apartment building. The rest of my days from the other family members in my apartment and by my friendly neighbor. For others, it is the classic dog barking and traffic noises.
Same as with video, since we’re now doing these sessions from everywhere at any time, it is becoming more important than ever to have this capability built into the service used.
Some services today offer the ability to suppress and cancel different types of noises. You don’t have the control over what to suppress, but rather get an on/off switch.
Four important things here:
- What noises are suppressed isn’t obvious. Each vendor picks and chooses what seems fit to his use case
- This can be implemented either on the sender side or on the receiver side or both
- It can be implemented on the device or in the cloud. Google Meet for example does that in the cloud while many others do it on the device
- Unlike the video features we’ve seen before, here as the sender, you can’t really hear what’s being suppressed of your end of the call…
And last but not least, this is a kind of a feature that can also be implemented directly by the microphone, CPU or operating system. Apple tried that recently in iOS and then reverted back.
Speech to text

Up until now, we’ve discussed capabilities that necessitated media processing and machine learning. Speech to text is different.
For several years now we’ve been hammered around speech to text and text to speech. The discussion was usually around the accuracy of the algorithms for speech to text and the speed at which they did their work.
It now seems that many services are starting to offer speech to text and its derivatives baked directly into their user experience. There are several benefits of investing in this direction:
- Switching to text enables us to process the meeting for its meaning. Usually in the form of extracting meeting minutes and action items
- Speech to text means we can get a transcript of a meeting, making it searchable
- Accessibility - doing so in real-time, means we can transcribe the meeting to the participants, assisting them with noisy environments of other participants or simply with understanding accents - my company, testRTC, was acquired by Spearline, an Irish vendor - I am just getting used to understanding their accent
- This is a step necessary for translation
The challenges with speech to text is first on how to pass the media stream to the speech to text algorithm - not a trivial task in many cases; and later, picking a service that would yield the desired results.
WebRTC meeting size
It used to be 9 tiles. Then when the pandemic hit, everyone scrambled to do 49 gallery view. I think that requirement has become less of an issue, while at the same time we see a push towards a greater number of participants in sessions.
How does that work exactly?
- The assumption that everyone is seen, needs to be seen or wants to be seen is not realistic in many scenarios
- Meetings are mostly asymmetric in nature. Not everyone has the same level of participation, and oftentimes, we aren’t aware of this in advance
- Quarantines and later remote work got us to the point where a lot more media streams join a meeting:
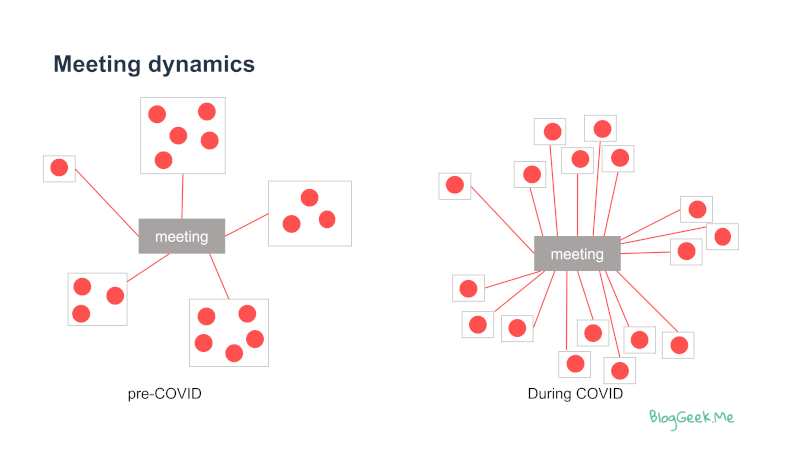
If in the past we had a few meeting rooms joining in to a meeting, with a few people seated in each room, now most of the time, we will have these people join in remotely from different locations. The number of people stayed the same, yet the number of media streams grew.
We’re also looking to get into more complex scenarios, such as large scale virtual events and webinars. And we want to make these more interactive. This pushes the boundary of a meeting size from hundreds of participants to thousands of participants.
This requirement means we need to put more effort into implementing optimizations in our WebRTC architecture and to employ capabilities that offer greater flexibility from our media servers and client code.
Getting there requires WebAssembly and constant optimization
These new requirements and capabilities are becoming table stakes. Implementing them has its set of nuances, and each of these features is also eating up on our CPU and memory budget.
It used to be that we had to focus on the new shiny toys. Adding new cool features and making them available on the latest and greatest devices. Now it seems that we’re in need of pushing these capabilities into ever lower performing devices:
- Older PCs and laptops, to deal with the majority of the population and not only early adopters and tech savvy users
- Plethora of peripherals - headsets, mics, speakers and webcams - all with their own quirks and proprietary features (echo canceling, latency inducing bluetooth headsets anyone?)
So we now have less capable devices who need more features to work well, requiring us to reduce our CPU requirements to serve them. And did I mention most of these new table stakes need machine learning?
The tool available to us for all this is WebAssembly on the browser side. This enables us to run code faster in the browser and implement algorithms that would be impossible to achieve using Javascript.
It also means we need to constantly optimize the implementation, improving performance to make room for more of these algorithms to run.
10 years into WebRTC and 2 years into the pandemic, we’re only just scratching the surface of what is needed. How are you planning to deal with these new table stakes?
