WebRTC has many moving parts in it. You want to learn how WebRTC works?
When WebRTC works it seems like magic. You point your browser to a URL. Get someone else to point his browser to a URL - and - you now see each other.
How cool can that be?
If you look below the hood, there’s a lot going on in there.
Looking for a WebRTC course to dig deeper and build a solid architecture for your product?
I’ll try to give the explanation of how WebRTC works in a few different angles of a WebRTC Tutorial here. Together, they should create a pretty good picture of what’s going on.
WebRTC Basic Concept
Here’s the first thing I usually say about WebRTC:

WebRTC is the means to drive real time communications (voice, video and arbitrary data) directly inside a web browser. No need for any plugin or download to do that.
From a different perspective, WebRTC is just a media engine with a JavaScript API on top of it, so everyone knows how to use it (although browser implementations still varies from one another).
Somehow, that’s not saying much.
So let’s start with what makes WebRTC truly unique from a browser perspective.
If up until now, when you thought of a web application you were thinking client and server -
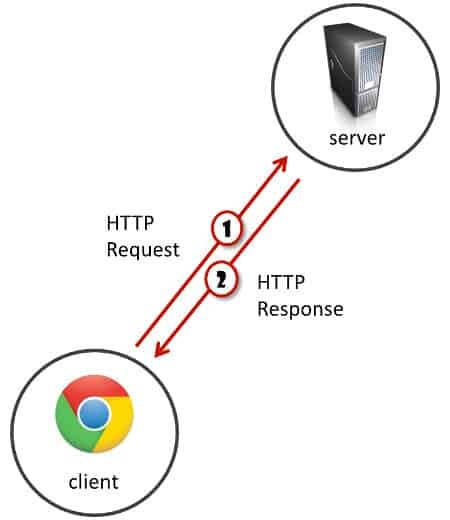
You have the browser as a client. It connects to the server to ask for stuff. Lets call these things requests. And the server obliged by sending responses. We’ve grown beyond that using WebSockets, but it still is rather the same. If I want to send a message to a friend who is looking at his own browser just now, the message needs to go to the server and from there to my friend. Much like the post office works.
WebRTC is where browsers and HTML diverges from this paradigm:
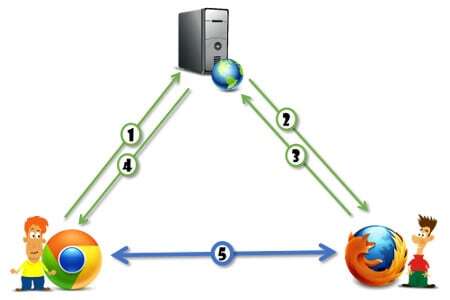
While we still need to somehow signal from one browser to the other so we will be able to locate each other, once that signaling is over, we can send them messages directly between the two browsers - without the web server ever touching the messages. Magic.
This is why many refer to WebRTC as a peer-to-peer technology. Or P2P in short. Because browsers can communicate directly.
See also: Beyond Network: How WebRTC and Open Source are Turning Video into a Geopolitical Battleground
Separation of Signaling and Media
When loading web pages, we are now used to the fact that the browser goes fetching a 100 different resources just to render a web page. These resources can come from various different servers - the host of the page, a CDN holding static files and a few third party sites. That said, this will mostly boil down to three types of files:
- HTML and CSS, which makeup the main content of the site and its style
- JS, which is usually there to run the interactive part of the website
- Image files and other similar resources
It ends up being a mixture of static stuff and a bit of code to hold it all together.
WebRTC is… different.
It requires two types of interactions that go over the network. Signaling and media.
Signaling takes place over an HTTPS connection or a websocket. It is implemented via JS code. What you do in signaling is decide how the users are going to find each other and start a conversation.
One important thing about signaling - it isn’t part of WebRTC itself. The developer is left to decide how to pass the information needed to create a WebRTC session. WebRTC will generate the bits of information it needs to send and process such bits of information that gets received but it won’t really do anything over the network about them. These bits of information are packed into SDP messages by WebRTC today.
The actual media goes off on a very different medium and connection. It goes through “media channels”. These use either SRTP (for voice and video) or SCTP (for the data channel).
Media takes a different route than signaling over the network and behaves very differently. This is true for the browser, the network AND the servers you need to make it work.
Audio and Video
Audio and video is the main thing you’ll notice with WebRTC. It is also what gets showcased in almost all demos and examples of WebRTC.
The reason for that is simple - video is VERY visual and interactive.
Audio and video in WebRTC works by using codecs. These are known algorithms that are used to compress and decompress audio and video data. There are different codecs you can use in WebRTC and I won’t get into it now.
Audio and video also gets interesting because it is sent with low latency in mind. If packets get lost along the way due to network issues - it might not be worth retransmitting them (another first in the HTML).
WebRTC uses known VoIP techniques to get media processed and sent through the network, and this is all done over SRTP - the secure and encrypted version of RTP. WebRTC did make some minor changes by using specific mechanisms in SRTP that were not in wide use before, making it a bit harder to interoperate with if you have a VoIP service deployed already.
Data too
You can also send arbitrary data with WebRTC. This is done over what’s called the data channel in WebRTC.
The data channel can be used when what you want to do is send direct messages between browsers without going through any server (you may still need to relay it through a TURN server though).
NAT Traversal
Being able to communicate directly across browsers is great, but it doesn’t always work.
The internet was built on the client-server paradigm some 30-40 years ago. Since then it has changed somewhat. Today, most users access the internet from behind a firewall or a NAT. These devices usually change the IP address of the user’s device and mask it from the open web. This masking can be just that, or it can also offer some measure of “protection” where unsolicited traffic is not allowed towards the user’s device. The problem with this approach, is that WebRTC uses different mediums for signaling and media so understanding what’s solicited and what’s unsolicited traffic isn’t easy.
Furthermore, there are enterprises who make it a point not to let any type of traffic into (or out of) their network without vetting it.
Which brings us to these types of scenarios:
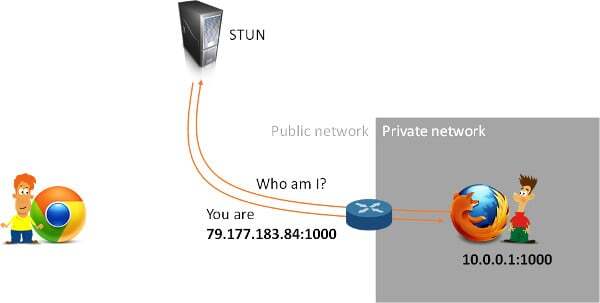
The guy there on the left? He now might actually know the public IP address of the guy on the right due to that STUN request that was made. But the public IP address might only be opened to the STUN server and having anyone else try to connect through that “pinhole” that was created may still fail.
In order to overcome these issues, a user’s device will not be able to directly communicate with another device located inside some other private network. And the workaround for that is to relay that blocked media through a public server. This is the whole purpose of TURN servers:
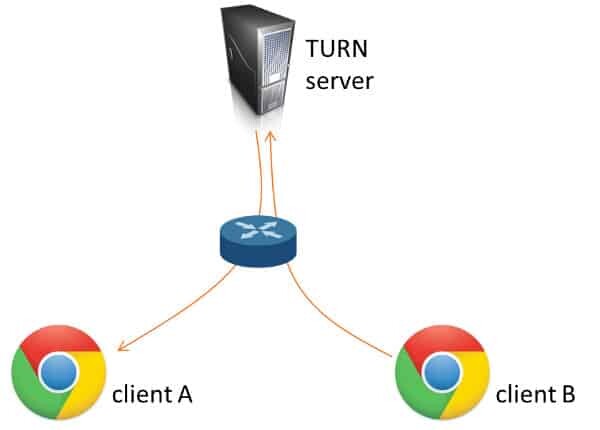
You can expect anywhere between 5-20% of your sessions to require the use of TURN servers.
Due to this complication, a WebRTC session takes the following steps:
- Send out an SDP offer to a web server. This SDP message outlines what are the media channels the device wants to exchange and how to find them
- Receive an SDP answer via the web server from the other device. Remember that that other device may be a media server
- Initiate a procedure called ICE negotiation, meant to find out if the devices are reachable directly, peer-to-peer or do they require media relay via TURN. This process is best done using trickle ICE, but that’s for another day
- Once done, media flows directly between the devices (see also WebRTC Flow)
All this mucking around requires asynchronous programming on the browser using JS code and can be done using JavaScript promises. On the server side, you can use whatever you want to manage media and signaling.
Oftentimes, developers won’t develop directly against the WebRTC APIs and will use third party frameworks and modules to do that for them - open source or commercial.
Quick Recap how WebRTC works
- WebRTC sends data directly across browsers - P2P
- It can send audio, video or arbitrary data in real time
- It needs to use NAT traversal mechanisms for browsers to reach each other
- Sometimes, P2P must go through a relay server (TURN)
- With WebRTC you need to think about signaling and media. They are separate from one another
- P2P is not mandated. It is just possible. You can place media servers if and when you need them. It “breaks” P2P, but we’re looking to solve problems, not write an academic dissertation
- Servers you’ll need in a WebRTC product:
- Signaling server (either as part of your application server or as a separate entity)
- STUN/TURN servers (that’s what gets used for NAT traversal
- Media servers (optional. Only if your use case calls for it)
WebRTC API Viewpoint
WebRTC has 3 main API groups:
getUserMedia
getUserMedia is in charge of giving the user access to the camera, microphone and screen. It alone gives value for those who need to do things locally, without implementing real time conversations.
Here are a few uses of standalone-getUserMedia:
- Take a user’s profile picture
- Collect audio samples and send them to a speech to text engine
- Record audio and video with no quality degradation due to packet loss
I am sure you can come up with more uses to it.
PeerConnection
PeerConnection is at the heart of WebRTC and the most complex to implement and to understand. In a way, it does EVERYTHING.
- It handles all the SDP message exchange (not sending them through the network itself, but generating them and processing the incoming ones).
- It implements ICE in order to connect the media channels, going through TURN relays if needed
- It encodes and decodes the audio and video data in realtime
- It sends and receives the media over the network
- It handles network issues by employing adaptive jitter buffer, bandwidth estimation, packet loss concealment, forward error correction and other algorithms that you really don’t want to know, but eventually will need to learn
- It handles local audio issues using algorithms such as acoustic echo cancellation
Much of what goes on inside peer connection that affects the resulting media quality is based on heuristics. A specific set of arbitrary rules. Different implementations may have different behaviors and different media quality due to this.
DataChannel
I’ve discussed the data channel somewhat earlier.
The only thing to add here is that:
- Data channels can be configured to be reliable or unreliable. If you set them to unreliable then messages will not be automatically retransmitted on them. Sometimes, that would be your preference. They can also be configured to be ordered or unordered in the way they deliver messages
- Data channels were designed to work on the API level similar to WebSocket, so once you open it, you can think about it in a similar fashion.
You can find a few ideas of what people are doing with data channels here. There are more ways you can make use of it.
The WebRTC Implementer’s Viewpoint
If what you’re looking for is to implement an application that makes use of WebRTC, then here are some activities you’ll need to deal with:
- Client side
- Signaling
- NAT traversal
- Media
Before you continue, you may want to check out this article about programming languages in WebRTC.
Client Side
The client side can be a browser, mobile application, PC application or an embedded device.
For web browsers, you’ll be developing using JavaScript. Either using WebRTC’s APIs directly (unlikely) or by using an existing framework of sorts (github is where many people start - just make sure you pick something popular that got updated recently).
For mobile applications, this is mostly about finding an SDK you’re comfortable with. There are again a few available on github, along with the official ones coming from Google for iOS and Android. There are also some commercial mobile SDK out there that are pretty good.
You can go for a PC application. Most do it by using Electron. And there’s also the embedded approach, which means either taking the official Google WebRTC codebase and porting it to whatever device you have or developing something on your own - I’ve seen both approaches work.
Signaling
You will need a signaling server. The first thing a WebRTC client will do is call the mothership. That is used to coordinate whatever session you have in mind for it.
The signaling server isn’t in the scope of the WebRTC specification so it is up to you to figure out what to use here. Most of the code you’ll find in the github for the browser client is actually going to be an implementation of a signaling server.
Remember that the signaling server can be separate from your web server or they can reside within the same process - up to you. And in any case, the first thing to do is to check if there’s already some kind of a signaling mechanism that you have in place for your application for things that aren’t WebRTC. You might be able to piggyback your SDP messages and other WebRTC related signaling over that mechanism (I know that’s what I’d try to do first).
NAT Traversal
For NAT traversal you will need to deploy STUN/TURN servers.
We’ll first start with what NOT to do:
- Don’t assume you won’t be needing TURN
- Don’t use public STUN servers
- Don’t have a single server for everything
- Don’t start by building a world-class global network of servers. You’ll get there, but it can wait
Now what you should do:
- Deploy STUN and TURN in the same server. On the same process
- Use coturn. That’s what everyone else is using
- Or instead, just get a hosted NAT traversal service from someone. XirSys, Twilio, Metered and Cloudflare offer such a service
Media
if you are planning on group voice and video sessions, connectivity to PSTN or other networks, recording or other fancy features, then media servers are in your immediate future.
Look for something that fits well with your use case.
I’d even say start here before picking anything else in your technology stack.
There are a few open source and commercial alternatives out there. They are different from one another in many ways.
How to figure out root causes for your WebRTC architecture problems in 10 minutes
FAQ on how WebRTC works
Yes. WebRTC works across browsers and operating systems, including iOS and Android. As an open source project, many have ported it to their own environments as well.
Besides a browser supporting WebRTC, you will need to install your own signaling server as well as TURN server(s). Depending on your use case, you may also need media servers.
The WebRTC Weekly and webrtcHacks are great resources to follow. There's always the official webrtc.org site. Other than these, you can also check out my online WebRTC training below.
Looking for a WebRTC Training?
The purpose of this article is to get you the most basic understanding of WebRTC if you’re a newb. I didn’t want to take the approach of building a “hello world” application - you can find many of these on the internet already. What I wanted to do instead is go somewhat higher and take a look at the bigger picture - you’ll be needing it soon enough.
In many cases, people start with a “hello world” implementation of WebRTC and try to fit it to their own scenario. I find that it is the wrong way in many cases, as it all depends on what it is you are trying to build - it will dictate the starting point you’ll need to make in your journey.
Spend the time to read this article, and then go read a “hello world” manual or two for WebRTC. It will make it a lot more effective if you do.
Looking for a WebRTC course to dig deeper and build a solid architecture for your product?
