
How WebRTC media resilience works - what FEC, RED, PLC, RTX are and why they are needed to improve media quality in real-time communications.
Networks are finicky in nature, and media codecs even more so.
With networks, not everything sent is received on the other end, which means we have one more thing to deal with and care about when it comes to handling WebRTC media. Luckily for us, there are quite a few built-in tools that are available to us. But which one should we use at each point and what benefits do they bring?
This is what I’ll be focusing on in this article. See also WebRTC Resilience
Networks are lossy
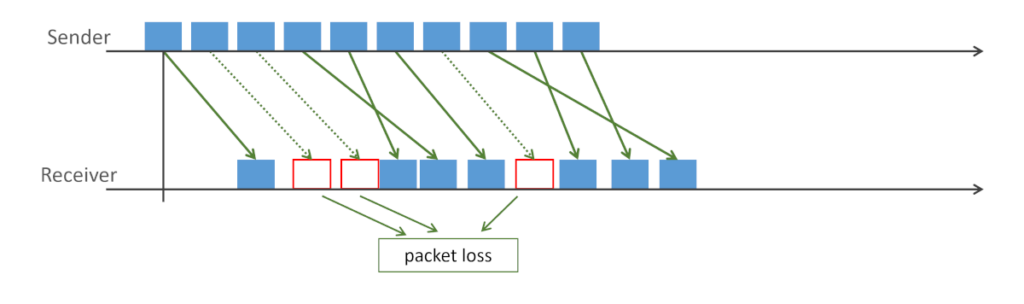
Communication networks are lossy in nature. This means that if you send a packet through a network - there’s no guarantee of that packet reaching the other side. There’s also no guarantee that packets are reached in the order you’ve sent them or in a timely fashion, but that’s for another article.
This is why almost everything you do over the internet has this nice retransmission mechanism tucked away somewhere deep inside as an assumption. That retransmission mechanism is part of how TCP works - and for that matter, almost every other transport protocol implemented inside browsers.
The assumption here is that if something is lost, you simply send it again and you’re done. It may take a wee bit longer for the receiver to receive it, but it will get there. And if it doesn’t, we can simply announce that connection as severed and closed.
We call and measure that “something is lost” aspect of networks as packet loss.
Stripping away that automatic assumption that networks are reliable and everything you send over them is received on the other side is the first important step in understanding WebRTC but also in understanding real-time transport protocols and their underlying concepts.
Media codecs are lossy (and sensitive)

Media codecs are also lossy but in a different way. When an audio codec or a video codec needs to encode (=compress) the raw input from a microphone or a camera, what they do is strip the data out of things they deem unnecessary. These things are levels of perceived quality of the original media.
👉 I remember many years ago, sitting at the dorms in the university and talking about albums and CDs. One of the roommates there was an audiophile. He always explained how vinyl albums have better audio quality than CDs and how MP3 just ruins audio quality. Me? I never heard the difference.
☝️ Perceived quality might be different between different people. The better the codec implementation, the more people will not notice degraded quality.
Back to codecs.
Most media codecs are lossy in nature. There are a few lossless ones, but these are rarely used for real time communications and not used in WebRTC at all. The reason we use lossy codecs is to have better compression rates:

Taking 1080p (Full HD) video at 30 frames per second will result in roughly 1.5Gbps of data. Without compressing it - it just won’t work. We’re trying to squeeze a lot of raw data over networks, and as always, we need to balance our needs with the resources available to us.
To compress more, we need:
- To reduce what we care about to the its bare minimum (the lossy aspect of the codecs we use)
- More CPU and memory to perform the compression
- Make every bit we end up with matter
That last one is where media codecs become really sensitive.
If every bit matters, then losing a bit matters. And if losing a bit matters, then losing a whole packet matters even more.
Since networks are bound to lose packets, we’re going to need to deal with media packets missing and our system (in the decoder or elsewhere) needing to fill that gap somehow

👉 More on lossy codecs
👉 More on the future of audio codecs (lossy and lossless ones)
Types of WebRTC media correction
Media packets are lost. Our media decoders - or WebRTC system as a whole - needs to deal with this fact. This is done using different media correction mechanisms. Here’s a quick illustration of the available choices in front of us:

Each such media correction technique has its advantages and challenges. Let's review them so we can understand them better.
PLC: Packet Loss Concealment

Every WebRTC implementation needs a packet loss concealment strategy. Why? Because at some point, in some cases, you won’t have the packets you need to play NOW. And since WebRTC is all about real-time, there’s no waiting with NOW for too long.
What does packet loss concealment mean? It means that if we lost one or more packets, we need to somehow overcome that problem and continue to run to the best of our ability.
Before we dive a bit deeper, it is important to state: not losing packets is always better than needing to conceal lost packets. More on that - later.
This is done differently between audio and video:
Audio PLC
For the most part, audio packets are decoded frame-by-frame and usually also packet-by-packet. If one is lost, we can try various ways to solve that. There are the most common approaches:
- Play nothing, causing ugly robotic/metallic tint to the audio
- Duplicate the previous audio frame, sometimes reducing its volume level
- Try to predict what the lost frame sounds like. Today, using machine learning, maybe with something like Google’s proprietary WaveNetEQ algorithm
Video PLC
Packet loss on video streams has its own headaches and challenges.
In video, most of the frames are dependant on previous ones, creating chains of dependencies:
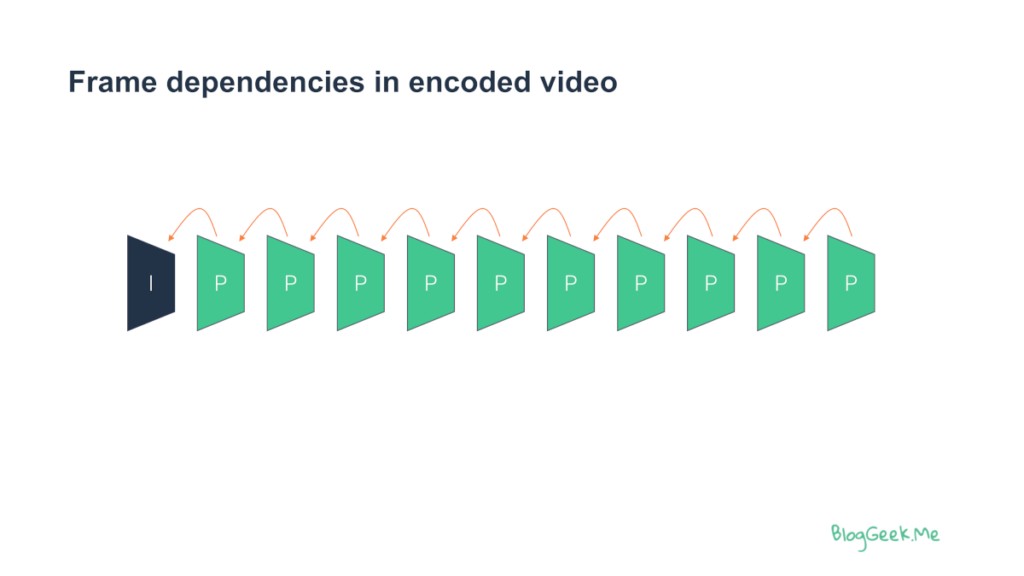
I-frames or keyframes (whatever they are called depending on the video codec used) break these dependency chains, and then one can use techniques like temporal scalability to reduce the dependencies for some of the frames that follow.
When you lose a packet, the question isn’t only what to do with the current video frame and how to display it, but rather what is going to happen to future frames depending on the frame with the lost packet.
In the past, the focus was on displaying every bit that got decoded, which ended up with video played back with smears as well as greens and pinks.

Today, we mostly not display frames until we have a clean enough bitstream, opting to freeze the video a bit or skip video frames than show something that isn’t accurate enough. With the advances in machine learning, they may change in the future.
PLC is great, but there’s a lot to be done to get back the lost packets as opposed to trying to make do with what we have. Next, we will see the additional techniques available to us.
RTX: Retransmissions (WebRTC media resilience)
Here’s a simple mechanism (used everywhere) to deal with packet loss - retransmission.
In whatever protocol you use, make sure to either acknowledge receiving what is sent to you or NACKing (sending a negative acknowledgement) when not receiving what you should have received. This way, the sender can retransmit whatever was lost and you will have it readily available.
This works well if there’s enough time for another round trip of data until you must play it back. Or when the data can help you out in future decoding (think the dependency across frames in video codecs). It is why retransmissions don’t always work that well in WebRTC media correction - we’re dealing with real time and low latency.
Another variation of this in video streams is asking for a new I-frame. This way, the receiver can signal the sender to “reset” the video stream and start encoding it from scratch, which essentially means a request to break the dependency between the old frames and the new ones that should be sent after the packet loss.
RED: REDundancy Encoding
Retransmission means we overcome packet losses after the fact. But what if we could solve things without retransmissions? We can do that by sending the same packet more than once and be done with it.
Double or triple the bitstream by flooding it with the same information to add more robustness to the whole thing.
RED is exactly that. It concatenates older audio frames into fresh packets that are being sent, effectively doubling or tripling the packet size.
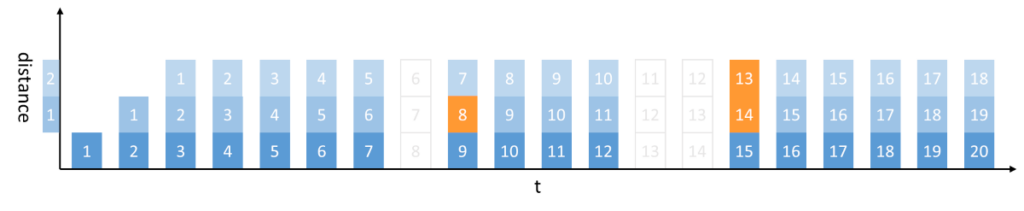
If a packet gets lost, the new frame it was meant to deliver will be found in one of the following packets that should be received.
Yes. it eats up our bandwidth budget, but in a video call where we send 1Mbps of video data or more, tripling the audio size from 40kbps to 90kbps might be a sacrifice worth making for cleaner audio.
FEC: Forward Error Correction

Redundancy encoding requires an additional 100% or more of bitrate. We can do better using other means, usually referred to as Forward Error Correction.
👉 Mind you, redundancy encoding is just another type of forward error correction mechanism
With FEC, we are going to add more packets that can be used to restore other packets that are lost. The most common approach for FEC is by taking multiple packets, XORing them and sending the XORed result as an additional packet of data.
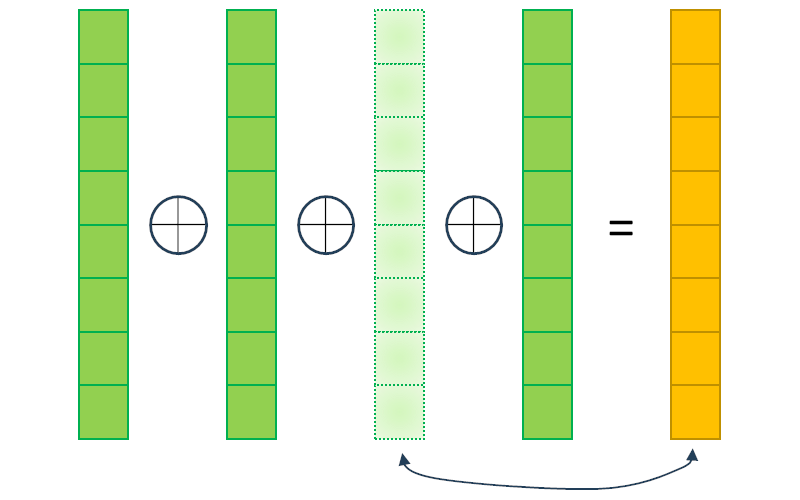
If one of the packets is lost, we can use the XORed packet to recreate the lost one.
There are other means of correction algorithms that are a wee bit more complex mathematically (google about Reed-Solomon if you’re interested), but the one used in WebRTC for this purpose is XOR.
FEC is still an expensive thing since it increases the bitrate considerably. Which is why it is used only sparingly:
- When you know there’s going to be packet losses on the network
- To protect only important video frames that many other frames are going to be dependent on
Making sense of WebRTC media correction
PLC, RTX, FEC, RED, …
How is each one signaled over the network? When would it make sense to use it? How does WebRTC implement it in the browser and what exactly can you expect out of it?
All that is mostly arcane knowledge. Something that is passed from one generation of WebRTC developers to another it seems.

Lucky for you, Philipp Hancke and myself are working on a new course - Higher Level WebRTC Protocols. In it, we are covering these specific topics as well as quite a few others in a level of detail that isn’t found anywhere else out there.
Most of the material is already written down. We just need to prettify it a bit and record it.
