
How do you choose the right architecture for a WebRTC audio conferencing service?
Last month, Lorenzo Miniero published an update post on work he is doing on Janus to improve its AudioBridge plugin. It touched a point that I failed to write about for a long time (if at all), so I wanted to share my thoughts and views on it as well.
I’ll start with a quick explanation - Lorenzo is adding to Janus a lot of layers and flexibility that is needed by developers who are taking the route of mixing audio in WebRTC conferences. What I want to discuss here is when to use audio mixing and when not to use it. And as everything else, there usually isn’t a clear cut decision here.
What’s mixing and what’s routing in WebRTC?
Group calls in WebRTC can take different shapes and sizes. For the most part, there are 3 dominant architectures for WebRTC multiparty calling: mesh, mixing and routing.
I’ll be focusing on mixing and routing here since they scale well to 100’s or more users.
Let’s start with the basics.
Assume there’s a conversation between 5 people. Each of these people can speak his mind and the others can hear him speaking. If all of these people are remote with each other and we now need to model it in WebRTC, we might think of it as something like this illustration:
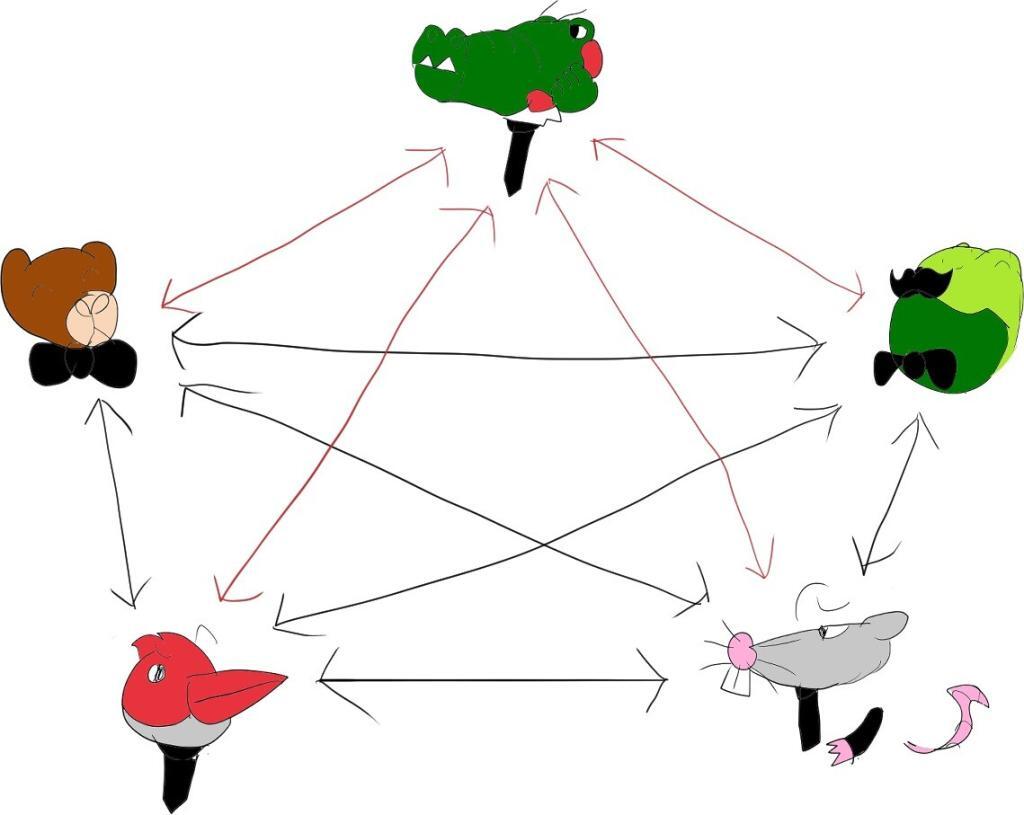
This is known as a mesh network. Its biggest disadvantage for us (though there are others) is the messiness of it all - the number of connections between participants that grows polynomially with the number of users. The fact that we need to send out the same audio stream to all participants individually is another huge disadvantage. Usually, we assume (and for good reasons) that the network available to us is limited.
The immediate obvious solution is to get a central media server to mix all audio inputs, reducing all network traffic and processing from the users:
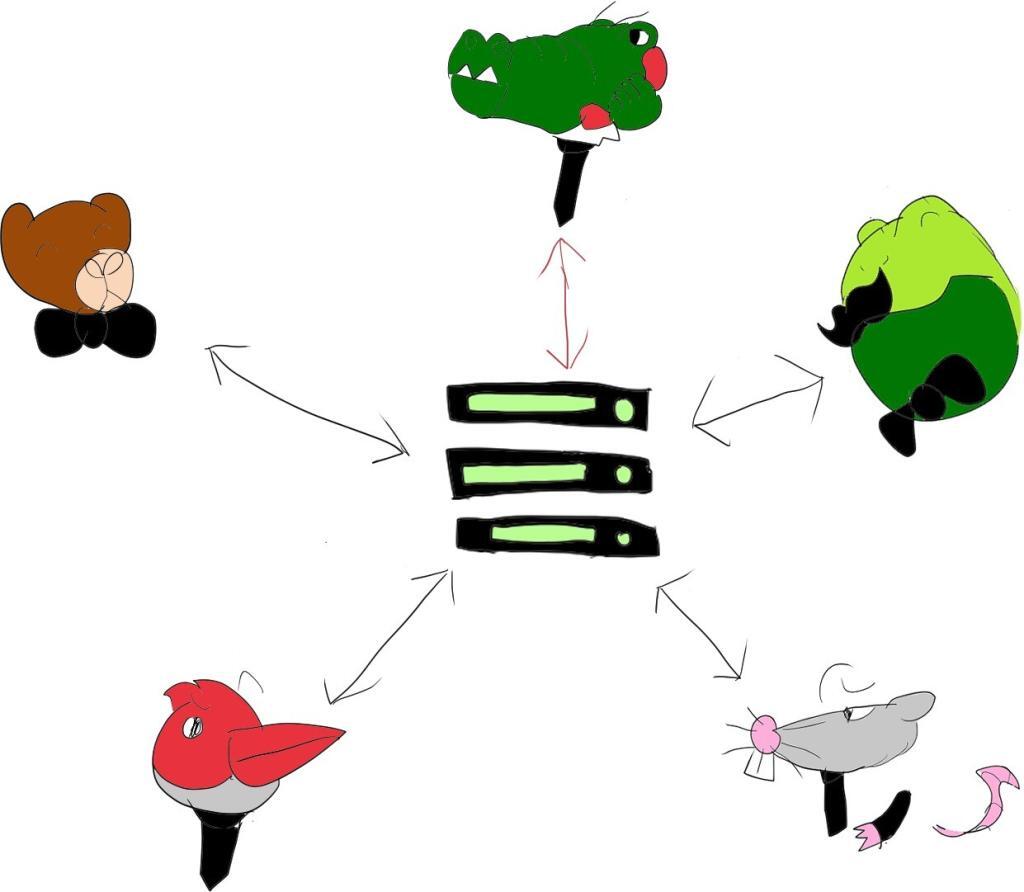
This media server is usually called an MCU (or a conferencing bridge). Users here “feel” as if they are in a session with only a single entity/user and the MCU is in charge of all the headaches on behalf of the users.
This mixer approach can be a wee bit expensive for the service provider and at times, not the most flexible of approaches. Which is why the SFU routed model was introduced, though mostly for video meetings. Here, we try to enjoy both worlds - we have the SFU route the media around, to try and keep bitrates and network use at reasonable levels while trying to reduce our hosting and media processing costs as service providers:
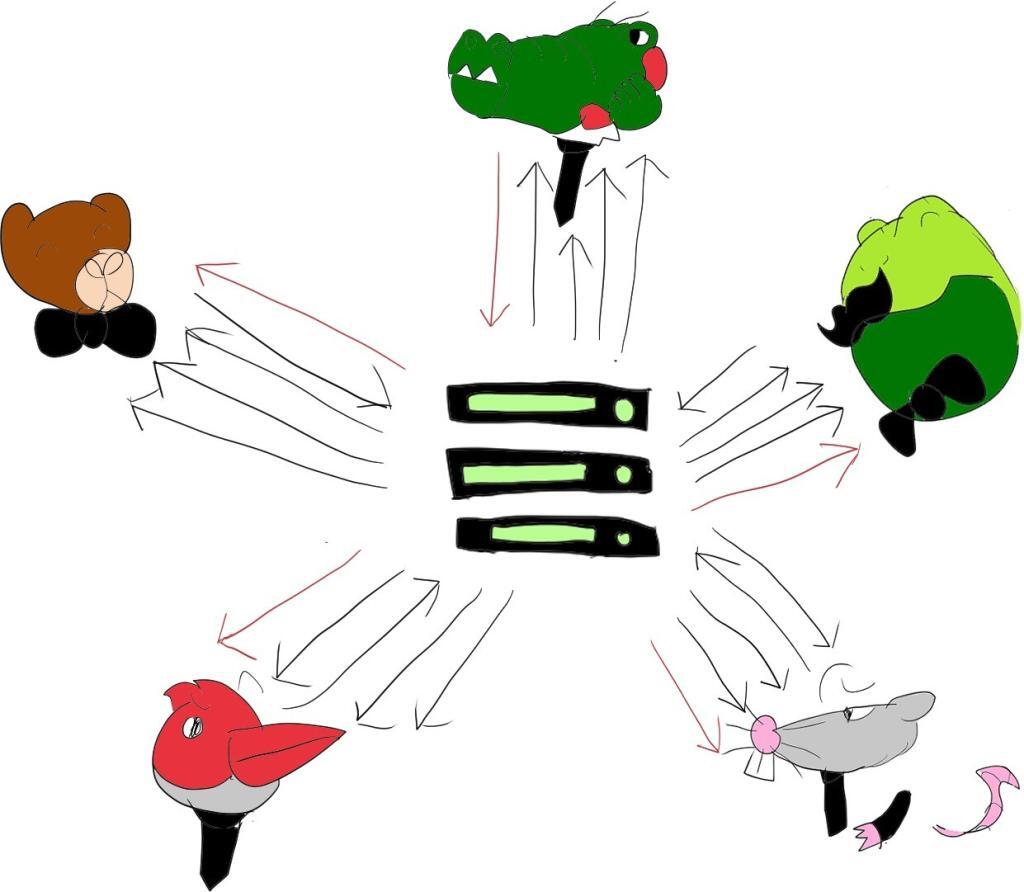
The SFU has become commonplace and the winning architecture model for video meetings almost everywhere. Voice only meetings though, have been somewhere in-between. Probably due to the existence and use of audio bridges a lot before WebRTC came to our lives.
This begs the question then, which architecture should we be using for our audio in group calls? Should we mix it in our media servers or just route it around like we do with video?
Before I go ahead to try and answer this question, there’s one more thing I’d like to go through, and that’s the set of media processing tools available to us today for audio in WebRTC.
Audio processing tools available for us in WebRTC

Encoding and decoding audio is the baseline thing. But other than that, there are quite a few media processing and network related algorithms that can assist applications in getting to the desired scale and quality of audio they need.
Before I list them, here are a few thoughts that came to mind when I collected them all:
- This list is dynamic. It changes a bit every year or so, as new techniques are introduced
- An example for this is active speaker detection, appearing in a paper a decade ago
- First adopted by Jitsi
- Then added to mediasoup by the team at hopin
- You can’t really use them all, all the time, for all use cases. You need to pick and choose the ones that are relevant to your use case, your users and the specific context you’re in
- We now have a machine learning based tool as well. We will have more of these in a year or two for sure
- It was a lot easier to compile this list now that we’ve finished recording and publishing all the lessons for the Higher-level WebRTC protocols course - we’ve covered most of these tools there in great detail
Audio level

There is an RTP header extension for audio level. This allows a WebRTC client to indicate what is the volume that can be found inside the encoded audio packet being sent.
The receiver can then use that information without decoding the packet at all.
What can one do with it?
Decide if you need to decode the packet at all or just discard it if there’s no or little voice activity or if the audio level is too low (no one’s going to hear what’s in there anyway).
You can replace it with DTX (see below) or not forward the packet in a Last-N architecture (see below).
Not mix its content with other audio channels (it doesn’t hold enough information to be useful to anyone).
DTX
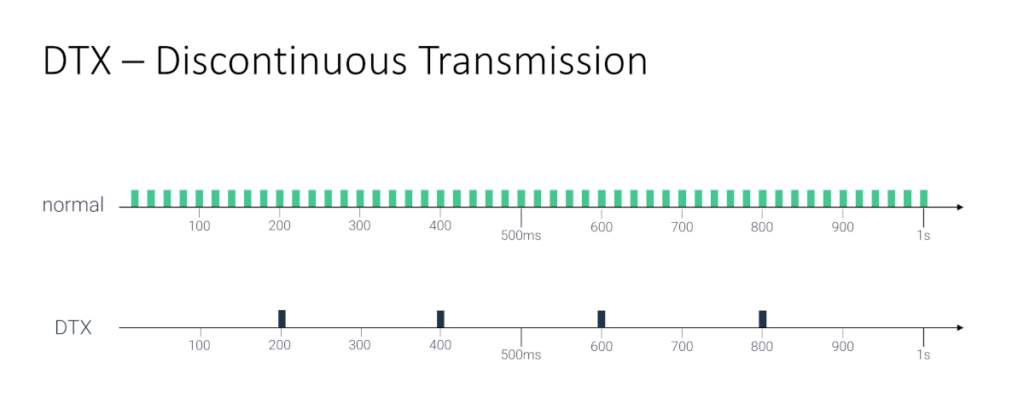
If there’s nothing really to send - the person isn’t speaking but the microphone is open - then send “silence” but with less packets over the network.
That’s what DTX is about, and it is great.
In larger meetings, most people will listen and not speak over one another. So most audio streams will just be “silence” or muted. If they aren’t muted, then sending DTX instead of actual audio reduces the traffic generated. This can be a boon to SFUs who end up processing less packets.
An SFU media server can also decide to “replace” actual audio it receives from users (because they have a low audio level in them or because of Last-N decisions he is making) with DTX data when routing media around.
PLC
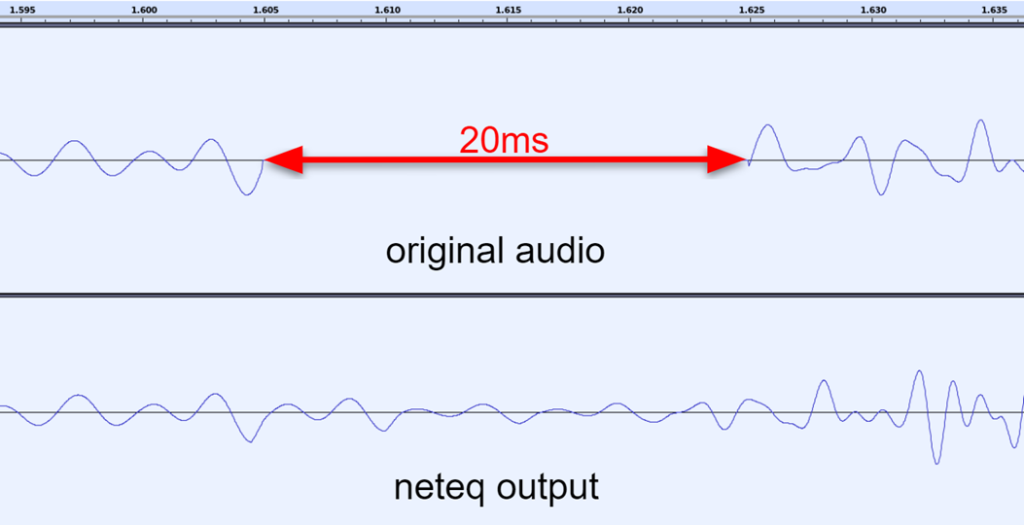
Packets are going to be lost, but there would be content that still needs to be played back to the user.
You can decide to play silence, a repeat of the last heard packet, lower its volume a bit, etc.
This can be done both on the server side (especially in the case of an MCU mixer) or on the client side - where such algorithms are implemented in the browser already. SFUs can ignore this one, mostly since they don’t decode and process the actual media anyway.
At times, these can be done using machine learning, like Google’s proprietary WaveNetEq, which tries to estimate and predict what was in the missing packet based on past packets received.
Packet loss concealment isn’t great at all times, but it is a necessary evil.
RTX & NACK
Theoretically, you could use retransmissions for lost packets.
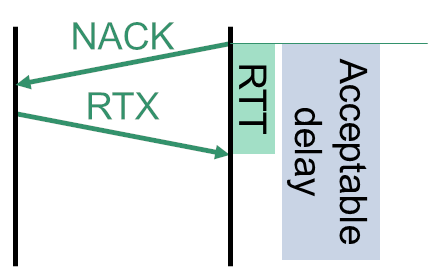
WebRTC does that mostly for video packets, but this can also find a home for audio.
It is/was a rather neglected area because PLC and Opus inband FEC techniques worked nicely.
For the time being, you’re likely to skip this tool, but it is one I’d keep an eye on if I were highly interested in audio quality advancements.
FEC and RED
Forward Error Correction is about sending redundant data that can be used to reconstruct lost packets. Redundancy coding is what we usually do for audio, which is duplicating encoded frames.
Audio bandwidth requirements are low, so duplicating frames doesn’t end up taxing much of our network, especially in a video call.
This approach enables us at a “low cost” to gain higher resiliency to packet losses.
This can be employed by the client sender, or even from the server side, beefing up what it received - both as an SFU or an MCU.
Check Philipp Hancke’s tal at Kranky Geek about Advanced in Audio Codecs
Then there’s the nuances and headaches of when to duplicate and how much, but that’s for another article.
Last-N
A known technicality in WebRTC’s implementation is that it only mixes the 3 loudest incoming audio channels before playing back the audio.
Why 3? Because 2 wasn’t enough and 4 seemed unnecessary is my guess. Also, the more sources you mix, the higher the noise levels are going to be, specially without good noise suppression (more on that below)
Well… Google just decided to remove that restriction. Based on the announcement, that’s because the audio decoding takes place in any case, so there’s not much of a performance optimization not to mix them all.
So now, you can decide if you want to mix everything (which you just couldn’t before) or if you want to mix or route only a few loudest volume (or most important) audio streams if that’s what you’re after. This reduces CPU and network load (depending on which architecture you are using).
Google Meet for example, is employing Last-3 technique, only sending up to 3 loudest audio streams to users in a meeting.
Oh, and if you want to dig deeper into the reasoning, there’s a nice Jitsi paper from 2016 explaining Last N.
Noise suppression: RNNoise and other machine learning algorithms
Noise suppression is all the rage these days.
RNNoise is a veteran among the ML-based noise suppression algorithms that is quite popular these days.
Janus for example, have added it to their AudioBridge and implemented optional RNNoise logic to handle channel-based noise suppression in their MCU mixer for each incoming stream.
Google added this in their Google Meet cloud - their SFU implementation passes the audio to dedicated servers that process this noise suppression - likely by decoding, noise suppression and encoding back the audio.
Many vendors today are introducing proprietary noise suppression to their solutions on the client side. These include Krisp, Dolby, Daily, Jitsi, Twilio and Agora - some via partnerships and others via self development.
Mixing keeps the headaches away from the browser

Why use an MCU for mixing your audio call? Because it takes all the implementation headaches and details away from the browser.
To understand some of what it entails on the server though, I’d refer you again to read Lorenzo’s post.
The great thing about this is that for the most part, adding more users means throwing more cloud hardware on the problem to solve it. At least up to a degree this can work well without thinking of scaling out, decentralization and other big words.
It is also how this was conducted for many years now.
Here are the tools I’d aim for in using for an audio MCU:
| Tool | Use? | Reasoning |
| Audio level | ✔️ | Decoding less streams will get higher performance density for the server. Use this with Last-N logic |
| DTX | ✔️ | Both when decoding and while encoding |
| PLC | ✔️ | On each incoming audio stream separately |
| RTX & NACK | ❌ | To early to do this today |
| FEC and RED | ✔️ | Today, for an MCU, this would be rare to see as a supported featureConsider on outgoing audio streams; as well as enable for incoming streams from devices |
| Last-N | ✔️ | Last-3 is a good default unless you have a specific user experience in mind (see below examples) |
| Noise suppression | ✔️ | On incoming channels, those that passed Last-N filtering, to clean them up before mixing the incoming streams together |
Things to note with an audio MCU, is that the MCU needs to generate quite a few different outgoing streams. For 10 participants with 4 speakers (at Last-4 configuration), it would be something like this:
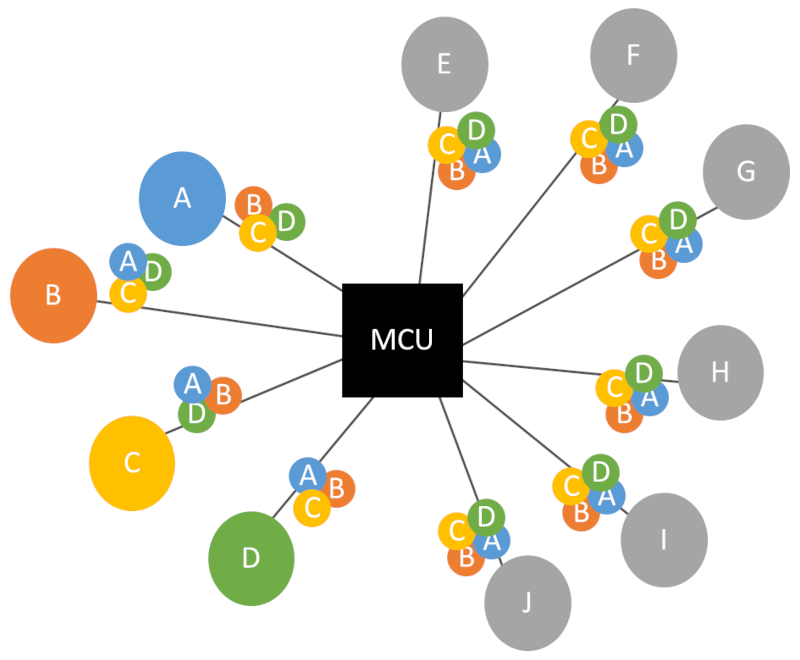
We have 5 separate mixers at play here:
- 1 mixing all 4 active speakers
- 4 mixing only 3 out of the 4 each time - we don’t want to send the person speaking his own audio mixed in the stream
Routing gets you better flexibility

Why do we use an SFU for audio conferences? Because we use it for video already… or because we believe this is the modern way of doing things these days.
When it comes to routing audio, the thing to remember is that we have a delicate balance between the SFU and the participants, each playing a part here to get a better experience at the end of the day.
Here are the tools I’d use for an audio SFU:
| Tool | Use? | Reasoning |
| Audio level | ✔️ | We must have this thing implemented and enabled, especially since we really really really want to be able to conduct Last-N logic and not send each user all audio channels from all other participants |
| DTX | ✔️ | We can use this to detect silence as well here (and remove from Last-N logic). On the sending logic, the SFU can decide to DTX the channels in Last-N that are silent or at a low volume to save a bit of extra bandwidth (a minor optimization) |
| PLC | ❌ | Not needed. We route the audio packets and let the participants fix any losses that take place |
| RTX & NACK | ❌ | To early to do this today |
| FEC and RED | ✔️ | This can be added on the receiver and sender side in the SFU to improve audio quality. Adding logic to dynamically device when and how much redundancy based on network conditions is also an advantage here |
| Last-N | ✔️ | Last-3 is a good default. Probably best to keep this at most at Last-5 since the decision here means more CPU use on the participants’ side |
| Noise suppression | ❌ | Not needed. This can be done on the participants’ side |
In many ways, an audio SFU is simpler to implement than an audio MCU, but tweaking it just right to gain all the benefits and optimizations from the client implementation is the tricky part.
Where the rubber hits the road - let’s talk use cases

As with everything else I deal with, which approach to use depends on the circumstances. One of the main deciding criteria in this case is going to be the use case you are dealing with and the scenario you are solving this for.
Here are a few that came to mind.
Gateway to the old world
The first one is borderline “obvious”.
Before WebRTC, no one really did an audio conference using an SFU architecture. And if they did, it was unique, proprietary and special. The world revolved and still revolves around MCU and mixing audio bridges.
If your service needs to connect to legacy telephony services, existing deployments of VoIP services running over SIP (or god forbid H.323), connect to a large XMPP network - whatever it may be - that “other” world is going to be running as an MCU. Each device is likely capable of handling only one incoming audio stream.
So trying to connect a few users from your service (no matter if you are using an SFU or an MCU) would need to mix these users when connecting them to the legacy service.
Video meetings with mixed audio

There are services that decide to use an SFU to route video streams and an MCU for the audio streams.
Sometimes, it is because the main service started as an audio service (so an audio bridge was/is at the heart of the service already) and video was bolted on the platform. Sometimes it is because gatewaying to the old world is central to the service and its mindset.
Other times, it is due to an effort to reduce the number of audio streams being sent around, or to reduce the technical requirements of audio only participants.
Whatever the reason, this is something you might bump into.
The big downside of such an approach is the loss of lip synchronization. There is no practical way you can synchronize a single audio stream that represents mixed content of multiple video streams. In fact, no lip synchronization with any of the video streams takes place…
Usually, the excuse I’ll be hearing is that the latency difference isn’t noticeable and no one complained. Which begs the question - why do we bother with lip synchronization mechanisms at all then? (we do because it does matter and is noticeable - especially when the network is slightly bumpier than usual)
Experience the crowd

Think of a soccer game. 50,000 people in a stadium. Rawring when there’s a goal or a miss.
With Last-3 audio streams mixed, you wouldn’t be hearing anything interesting when this takes place “remotely” for the viewers.
The same applies to a virtual online concert.
Part of the experience you are trying to convey is the crowds and the noises and voices they generate.
If we’re all busy reducing noise levels, suppressing it, picking and choosing the 2-3 voices in the crowd to mix, then we just degrade the experience.
Crowds matter in some scenarios. And keeping their experience properly cannot be done by routing audio streams around. Especially not when we’re starting to talk about hundreds of more active participants.
This case necessitates the use of MCU audio bridging. And likely a distributed approach the moment the numbers of users climb higher.
Metaverse and spatial audio

The metaverse is coming. Or will be. Maybe. Now that Apple Vision Pro is upon us. But even before that, we’ve seen some metaverse use cases.
One thing that comes to mind here is the immersion part of it, which leads to spatial audio. The intent of hearing multiple sounds coming from different directions - based on where the speaker is.
This means several things:
- For each user, the angle and distance (=volume level) of each other person speaking is going to be different
- That Last-3 strategy doesn’t work anymore. If you can distinguish directionness and volume levels individually, then more sources might need to be “mixed” here
Do you do that on the client side by way of an SFU implementation, or would it be preferable to do this in an MCU implementation?
And what about trying to run concerts in the metaverse? How do you give the notion of the crowds on the audio side?
These are questions that definitely don’t have a single answer.
In all likelihood, in some metaverse cases, the SFU model will be the best architectural approach while in others an MCU would work better.
Recording it all

Not exactly a use case in its own right, but rather a feature that is needed a lot.
When we need to record a session, how do we go about doing that?
Today, in at least 99% of the time that would be by mixing all audio and video sources and creating a single stream that can be played as a “regular” mp4 file (or similar).
Recording as a single stream means using an MCU-like solution. Sometimes by implementing it in a headless browser (as if this is a silent participant in the session) and other times by way of dedicated media servers. The result is similar - mixing the multiple incoming streams into a single outgoing one that goes directly to storage.
The downside of this, besides needing to spend energy on mixing something that people might never see (which is a decision point to which architecture to pick for example), is that you get to view and hear only a single viewpoint of a single user - since the mixed recording is already “opinionated” based on what viewpoint it took.
We can theoretically “record” the streams separately and then play them back separately, but that’s not that simple to achieve, and for the most part, it isn’t commonplace.
A kind of a compromise we see today with professional recording and podcast services is to record by mixed and separated audio streams. This allows post production to take either based on the mixing needs, but done manually.
Which will it be? MCU or SFU for your next audio meeting?

We start with this, and we will end with this.
It depends.
You need to understand your requirements and from there see if the solution you need will be based on an MCU, and SFU or both. And if you need help with figuring that out, that’s what my WebRTC courses are for - check them out.
