If you are planning to use WebRTC P2P mesh to power your service, don’t expect it to scale to large sessions. Here’s why.

Every once in a while someone comes in with the idea to broadcast or conduct a large scale video session with WebRTC without the use of media servers. Just using pure WebRTC P2P mesh technology.
While interesting as a research topic for university, I don’t think that taking that route to production is a viable approach. Yet.
Table of contents
What is WebRTC P2P mesh?
If you are focusing on data only WebRTC mesh, then skip to the last section of this article.
When dealing with WebRTC and indicating P2P or mesh, the focus is almost always on media transport. The signaling still flows through servers (single or distributed). For a simple 1:1 voice or video call, WebRTC P2P is an obvious choice.

The diagram below shows that from the perspective of the WebRTC client, there is no difference between going through a media server or going P2P – in both cases, it sends out a single media channel and receives a single media channel. In both cases, we’d expect the bitrates to be similar as well.
Making this into a group call in P2P translates into a mesh network, where every WebRTC client has a peer connection opened to all other clients directly.
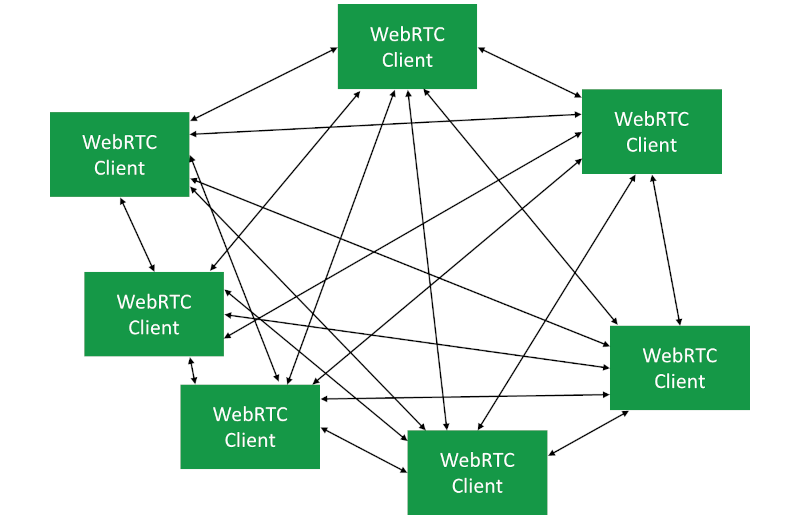
Why use WebRTC P2P mesh?
There are two main alluring reasons for vendors to want to use WebRTC P2P mesh as an architectural solution:
- It is cheaper to operate. Since there are no media servers, the media flows directly between the users. With WebRTC, oftentimes, the biggest cost is bandwidth. By not routing media through servers as much as possible (TURN relay will still be needed some of the time), the cost of running the service reduces drastically
- It is more private. Yap. As the service provider you don’t have any access to the media, since it doesn’t flow through your servers, so you can market your service as one that offers a higher degree of privacy for the end users
Why not use WebRTC P2P mesh?
If WebRTC P2P mesh is so great, with cheaper operating costs and better privacy, then why not use it?
Because it brings with it a lot of challenges and headaches when it comes to bandwidth and CPU requirements. So much so that it fails miserably in many cases.
It is also important to note here that in ALL cases of 3 users or more in a call, alternative solutions that rely on media servers give better performance and user experience. Always – at least as long as the media servers infrastructure is properly deployed and configured.
Bandwidth challenges in WebRTC P2P mesh
Assume we want pristine quality. Single speaker, 10 listeners.

The above layout illustrates what most users of this conference would like to see and experience. The speaker may alternate during the meeting, switching the person being displayed in the bigger frame.
As we’re all watching this on large screens (you do have a 28” 4K display – right?), we’d rather receive this at HD resolution and not QVGA. For that, we’d want at least 1.5Mbps of the speaker to be received by everyone.
Strain on the uplink
In a mesh topology, the speaker needs to send the media to all the participants. Here’s what that means exactly:

1.5Mbps times 10 equals 15Mbps on the uplink. Not something that most people have. Not something that I think my strained FTTH network will be able to give me whenever I need it. Especially not during the pandemic.
In an office setting, where people need to use the network in parallel, giving every user in a remote meeting 15Mbps uplink won’t be possible.
On top of that, we’ve got 10 separate peer connections to 10 different locations. WebRTC has its one internal bandwidth estimation algorithm that Google implemented in libwebrtc, which is great. But how well does it handle so many peer connections on the client’s side? Has anyone at Google ever tried to target or even optimize for this scenario? Remember – none of Google’s own services run in a mesh topology. Winning this one is going to be an uphill battle.
Bandwidth estimation on the downlink
Let’s look at the viewers/subscribers/participants/users or whatever else you want to call them.
If we pick a gallery view layout, then we are going to receive 10 incoming video streams. Reduce that to 9 for layout simplicity and we get this illustration:

There are 9 other users out there who generate video streams and send them our way. These 9 streams are competing on our downlink network resources and for our machine’s attention and CPU.
Each of them is independent of the others and have little knowledge about the others.
How can the viewer understand his downlink network conditions properly? Let alone try to instruct these sends on how and what to send. A media server has the same set of problems to deal with, but it does that with two main advantages:
- It controls all the videos that are sent to the viewer, and it can act uniformly as opposed to multiple browsers competing against each other (you can try to sync them, though good luck with that)
- You can put all incoming streams in a single peer connection from the server, which is what Google Meet does (and probably what Google is focused on optimizing for in their WebRTC implementation)
CPU challenges in P2P mesh
Then there’s the CPU to deal with in WebRTC P2P mesh.
Each video stream from our speaker to the viewers has its own dedicated video encoder. With our 10 viewers, that means 10 video encoders.
A few minor insights here if I may:
- If you aim for H.264 hardware encoding, then bear in mind that many laptops allow up to 3-4 encoded streams in parallel. All the rest will be black screens with the current WebRTC implementation
- Video coding is a CPU (and memory) hog. Encoding is a lot worse than decoding when it comes to CPU resources. Having 10 decoders is hard enough. 10 encoders is brutal
- 10 or more participants in a video call is hard to manage with an SFU without adding optimizations to alleviate the pains of clients and not burn their CPU. And that’s when each user has a single encoder (or simulcast) to deal with
- Your Apple MacBook Pro 2019 with 16 cores isn’t the typical device your users will have. If that’s what you’re testing your WebRTC mesh group video calling on then you’re doin’ it wrong
- I am sure you thought that using VP9 (or AV1 or HEVC, which aren’t really available in WebRTC at the moment) will save you on bandwidth and improve quality. But it eats even more CPU than VP8 or H.264 so not feasible at all
So. going for a group video call?
Want to use WebRTC P2P mesh?
You’re stuck at 300kbps or less for your outgoing video even if your network has great uplink. Because your device’s CPU is going to burn cycles on encoding multiple times.
Which also means that people aren’t going to like hearing their laptop’s fans or touch their heating smartphone (and depleting battery) on that call.
Can we do better?
Probably. A single encoder would make the CPU problem a wee bit smaller. It will bring with it headaches of matching the bitrate to all viewers (each has his own network and device limitations).
Using simulcast in some manner here may help, but that’s not how it is intended to be used or how it has been implemented either.
So this approach requires someone to make the modifications to the WebRTC codebase. And for Google to adopt them. Did I already say Google has no incentive in investing in this?
Alternatives to WebRTC P2P mesh
You can get a group video call to work in WebRTC P2P mesh architecture. It will mean very low bitrate and reduced video quality. But it will work. At least to some extent.
There are other models which perform better, but require media servers.
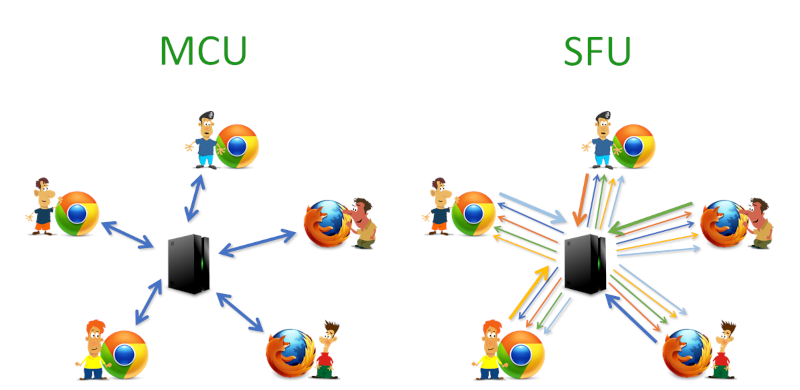
Using an MCU model, you mix all the video and audio streams in the MCU, making sure each participant receives and sends only a single stream towards the MCU.
With the SFU model, you route media around between participants while trying to balance their limitations with the media inputs the SFU receives.
You can learn more about in my WebRTC multiparty architectures article.
A word about WebRTC data channel mesh
I haven’t really touched WebRTC mesh architectures for data channels.
All the reasons and challenges detailed above don’t apply there directly. CPU and bandwidth relied on the concept of needing to encode, send, receive and decode live video. In most cases, this isn’t what we’re dealing with when trying to build mesh data channel networks. There, the main concern/challenge is going to be proper creation and connection of the peer connections in WebRTC.
If what you are doing isn’t a group video call (or live video broadcast from a browser to others) then a WebRTC P2P mesh architecture might work for you. If it will or won’t is something to analyze case by case.
Good job …thanks
You make a lot of good points
What about mesh architecture in audio only calls? If you had to take a rough guess, how many participants would audio only mesh support?
Kani,
I don’t know… I’d assume 10 or so users should be possible. You’d start dealing with instabilities on slow connections that would crap the experience more than it would for media servers probably, but should be doable.
That said, most don’t care that much since doing group calling in the cloud using mixing is considered quite a common solution and not too expensive. You can also use an SFU, which Discord were capable of deploying at some serious scale of 100s of users in a call.
Thanks Tsahi, this is very interesting. Do you know of any products / open-source solutions that rely on a mesh for their multiparty audio-only calls?
Any idea how much an SFU costs to run – e.g. supporting a million minutes of 4-person audio calls?
Haven’t seen any mesh solution that works well in production for voice or video calls. Sorry…
If I look at costs, then Agora prices its voice calling service at $0.00099/minute
Not sure if anyone remembers but p2p streaming through meshes of users via UDP is one of the last audio/video features that were built into Flash Player
https://www.adobe.com/devnet/adobe-media-server/articles/p2p_rtmfp_groups.html
What about streaming only (one-way)? I assume the overhead still gets big for multiple viewers?
Exact same problem. You still have too many encoders (one per outgoing stream). And too much bitrate on the uplink.