
RTC@Scale is Facebook’s virtual WebRTC event, covering current and future topics. Here’s the summary for RTC@Scale 2023 so you can pick and choose the relevant ones for you.
See also the most resent RTC@Scale 2024 event summary
WebRTC Insights is a subscription service I have been running with Philipp Hancke for the past two years. The purpose of it is to make it easier for developers to get a grip of WebRTC and all of the changes happening in the code and browsers - to keep you up to date so you can focus on what you need to do best - build awesome applications.
We got into a kind of a flow:
- Once every two weeks we finalize and publish a newsletter issue
- Once a month we record a video summarizing libwebrtc release notes (older ones can be found on this YouTube playlist)
Oh - and we're covering important events somewhat separately. Last month, a week after Meta's RTC@Scale event took place, Philipp sat down and wrote a lengthy summary of the key takeaways from all the sessions, which we distributed to our WebRTC Insights subscribers.
As a community service (and a kind of a promotion for WebRTC Insights), we are now opening it up to everyone in this article 😎
Why this issue?
Meta ran their rtc@scale event again. Last year was a blast and we were looking forward to this one. The technical content was pretty good again. As last year, our focus for this summary is what we learned or what it means for folks developing with WebRTC. Once again, the majority of speakers were from Meta. At times they crossed the line of “is this generally useful” to the realm of “Meta specific” but most of the talks still provide value.
Compared to last year there were almost no “work with me” pitches (with one exception).
It is surprising how often Meta says “WebRTC” or “Google” (oh and Amazon as well).
Writing up these notes took a considerable amount of time (again) but we learned a ton and will keep referencing these talks in the future so it was totally worth it (again). You can find the list of speakers and topics on the conference website, the seven hours of raw video here (which includes the speaker introductions) or you just scroll down below for our summary.
SESSION 1
Rish Tandon / Meta - Meta RTC State of the Union

Duration: 13:50
Watch if you
- watch nothing else and don’t want to dive into specific areas right away. It contains a ton of insights, product features and motivation for their technical decisions
Key insights:
- Every conference needs a keynote!
- 300 million daily calls on Messenger alone is huge
- The Instagram numbers on top of that remain unclear. Huge but not big enough to brag about?
- Meta seems to have fared well and has kept their usage numbers up after the end of the pandemic, despite the general downward/flat trend we see for WebRTC in the browser
- 2022 being their largest-ever year in call volume this suggests eating someone else's market share (Google Duo possibly?)
- Traditionally RTC at Meta was mobile-first with 1-1 being the dominant use-case. This is changing with Whatsapp supporting 32 users (because FaceTime does? Larger calls are in the making), an improved desktop application experience with a paginated 5x5 grid. Avatars are not dead yet btw
- Meta is building their unified “MetaRTC” stack on top of WebRTC and openly talks about it. But it is a very small piece in the architecture diagram. Whatsapp remains a separate stack. RSYS is their cross-platform library for all the things on top of the core functionality provided by libWebRTC
- The paginated 4x4 grid demo is impressive
- Pagination is a hard problem to solve since you need to change a lot of video stream subscriptions at the same time which, with simulcast, means a lot of large keyframes (thankfully only small resolution ones for this grid size)
- You can see this as the video becomes visible from left to right at 7:19
- Getting this right is tough, imagine how annoying it would be if the videos showed up in a random order…
- End-to-end encryption is a key principle for Meta
- This rules out an MCU as part of the architecture
- Meta is clearly betting on the simulcast (with temporal layers), selective forwarding and dominant speaker identification for audio (with “Last-N” as described by Jitsi in 2015)
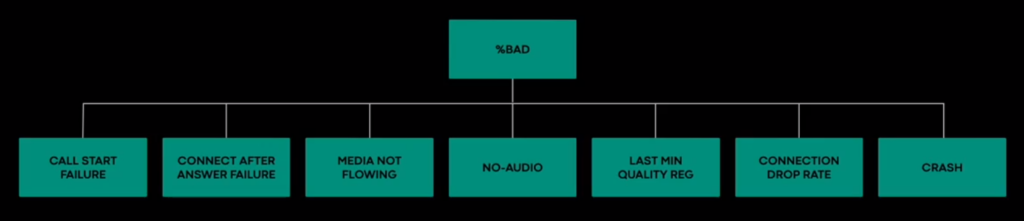
- Big reliability improvements by defining a metric “%BAD” and then improving that
- The components of that metric shown at 9:00 are interesting
- In particular “last min quality reg” which probably measures if there was a quality issue that caused the user to hang up:
- For mobile apps a grid layout that scales nicely with the number of participants is key to the experience. One of the interesting points made is that the Web version actually uses WASM instead of the browser's native video elements
- The “Metaverse” is only mentioned as part of the outlook. It drives screen sharing experiences which need to work with a tight latency budget of 80ms similar to game streaming
See also the article on Apple Vision.
Sriram Srinivasan / Meta - Real-time audio at Meta Scale

Duration: 19:30
Watch if you are
- An engineer working on audio. Audio reliability remains one of the most challenging problems with very direct impact to the user experience
Key insights:
- Audio in RTC has evolved over the years:
- We moved from wired-network audio-only calls to large multi party calls on mobile devices
- Our quality expectations (when dogfooding) have become much higher in the last two decades
- The Metaverse introduces new requirements which will keep us busy for the next one
- Great examples of the key problems in audio reliability starting at 2:30
- Participants can’t hear audio
- Participants hear echo
- Background noise
- Voice breakup (due to packet loss)
- Excessive latency (leading to talking over each other)
- On the overview slide at 4:20 we have been working on the essentials in WebRTC for a decade, with Opus thankfully enabling the high-end quality
- This is hard because of the diversity in devices and acoustic conditions (as well as lighting for video). This is why we still have vendors shipping their own devices (Meta discontinued their Portal device though)
- Humans have very little tolerance for audio distortions
- The basic audio processing pipeline diagram at 5:50 and gets walked through until 11:00
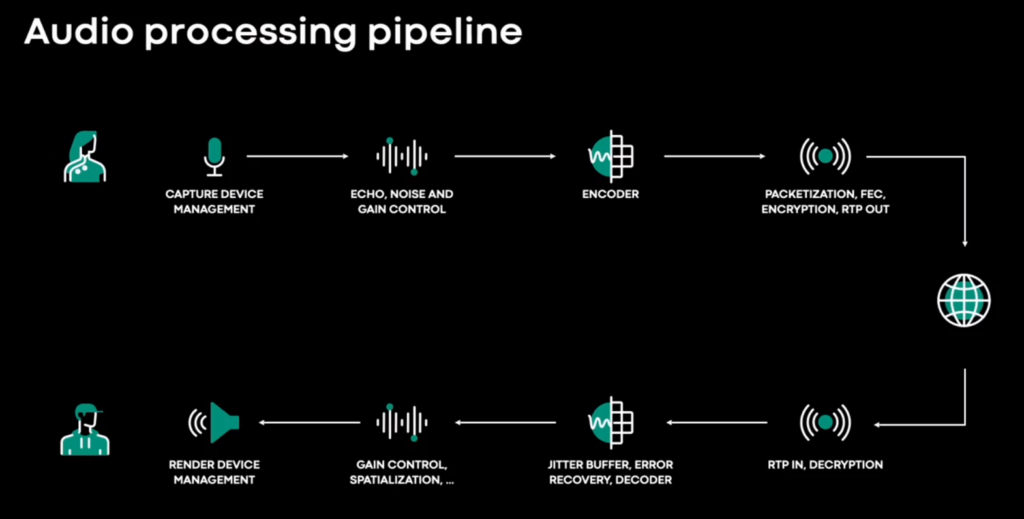
-
- Acknowledges that the pipeline is built on libWebRTC and then says it was a good starting point back in the day. The opinion at Google seems to be that the libWebRTC device management is very rudimentary and one should adopt the Chrome implementations. This is something where Google was doing better than messenger with duo. They are not going to give that away for free to their nemesis
- While there have been advances in AEC recently due to deep neural networks, this is a challenge on mobile devices. The solution is a “progressive enhancement” which enables more powerful features on high-end devices. On the web platform it is hard to decide this upfront as we can’t measure a lot due to fingerprinting concerns. You heard the term “progressive RTC application” or PRA here on WebRTC Insights first (but it is terrible, isn’t it?)
- For noise suppression it is important to let the users decide. If you want to show your cute baby to a friend then filtering out the cries is not appropriate. Baseline should be filtering stationary noise (fan, air condition)
- Auto gain control is important since the audio level gets taken into account by SFUs to identify the dominant speaker
- Low-bitrate encoding is important in the market with the largest growth and terrible networks and low-end devices: India. We have seen this before from Google Duo
- Audio device management (capture and rendering) starts at 11:00 and is platform-dependent
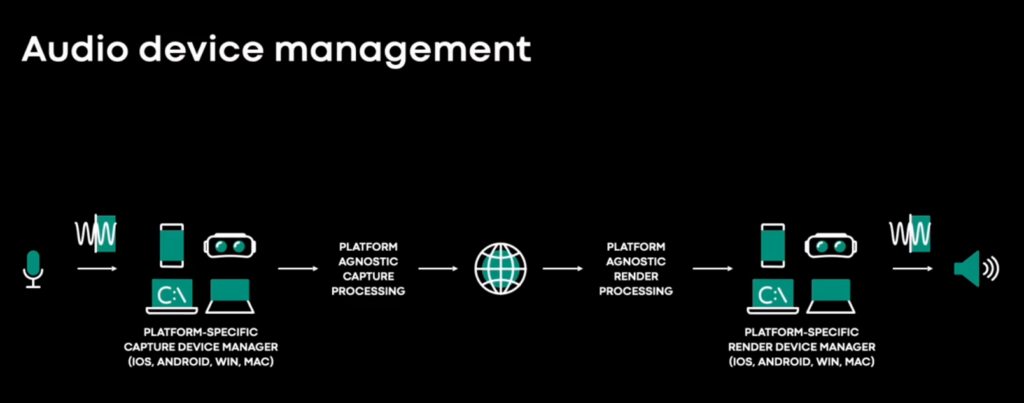
-
- This is hard since it cannot be tested at scale but is device specific. So we need at least the right telemetry to identify which devices have issues and how often
- End-call feedback which gets more specific for poor calls with a number of buckets. This is likely correlated with telemetry and the “last minute quality regression” metric
- While all of this is great it is something Meta is keeping to themselves. After all, if Google made them spend the money why would they not make Google spend the money to compete?
- 💡 This goes to show how players other than Google are also to blame for the current state of WebRTC (see Google isn’t your outsourcing vendor)
- Break-down of “no-audio” into more specific cases at 13:00
- The approach is to define, measure, fix which drives the error rate down
- This is where WebRTC in the browser has disadvantages since we rarely get the details of the errors exposed to Javascript hence we need to rely on Google to identify and fix those problems
- Speaking when muted and showing a notification is a common and effective UX fix
- Good war stories, including the obligatory Bluetooth issues and interaction between phone calls and microphone access
- Outlook at 17:40 about the Metaverse
- Our tolerance for audio issues in a video call is higher because we have gotten used to the problems
- Techniques like speaker detection don’t work in this setting anymore
Niklas Enbom / Meta - AV1 for Meta RTC

Duration: 18:00
Watch if you are
- An engineer working on video, the “system integrators” perspective makes this highly valuable and applicable with lots of data and measurements
- A product owner interested in how much money AV1 could save you
Key insights:
- Human perception is often the best tool to measure video quality during development
- AV1 is adopted by the streaming industry (including Meta who wrote a great blog post). Now is the time to work on RTC adaptation which lags behind:
- Hardware support is coming
- libaom is being actively developed with quite a few recent improvements for RTC use-cases
- AV1 is the next step after H.264 (a 20 year old codec) for most deployments (except Google who went after VP9 with quite some success)
- Measurements starting at 4:20
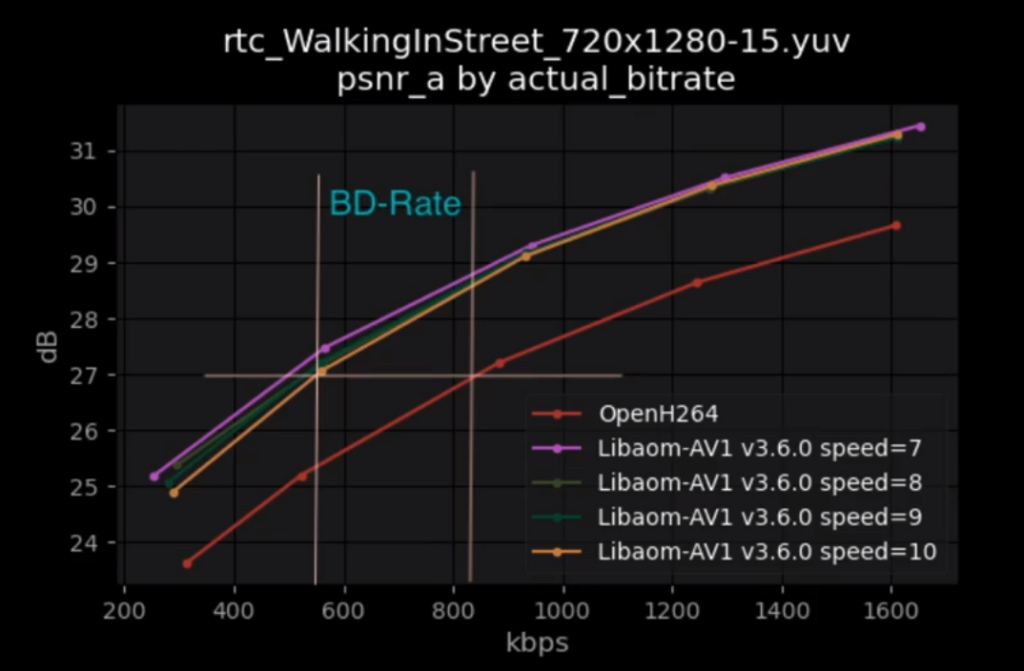
-
- The “BD-Rate” described the bitrate difference between OpenH264 and libaom implementations, showing a 30-40% lower bitrate for the same quality. Or a considerably higher quality for the same bitrate (but that is harder to express in the diagram as the Y-axis is in decibels)
- 20% of Meta’s video calls end up with less than 200kbps (globally which includes India). AV1 can deliver a lot more quality in that area
- The second diagram at 5:20 is about screen sharing which is becoming a more important use-case for Meta. Quality gains are even more important in this area which deals with high-resolution content and the bitrate difference for the same quality is up to 80%. AV1 screen content coding tools help address the special-ness of this use-case too
- A high resolution screen sharing (4k-ish) diagram is at 6:00 and shows an ever more massive difference followed by a great visual demo. Sadly the libaom source code shown is blurry in both examples as a result of H.264 encoding) but you can see a difference
- Starting at 6:30 we are getting into the advantages of AV1 for integrators or SFU developers:
- Reference Picture Resampling removes the need for keyframes when switching resolution. This is important when switching the resolution down due to bandwidth estimates dropping - receiving a large key frame is not desirable at all in that situation. Measuring the amount of key frames due to resolution changes is a good metric to track (in the SFU) - quoted as 1.5 per minute
- AV1 offers temporal, spatial and quality SVC
- Meta currently uses Simulcast (with H.264) and requires (another good metric to track) 4 keyframes per minute (presumably that means when switching up)
- Starting at 8:00 Niklas Enbom talks about the AV1 challenges they encountered:
- AV1 can also provide significant cost savings (the exact split between cost savings and quality improvements is what you will end up fighting about internally)
- Meta approached AV1 by doing an “offline evaluation” first, looking at what they could gain theoretically and then proceeding with a limited roll-out on desktop platforms which validated the evaluation results
- Rolling this out to the diverse user base is a big challenge of its own, even if the results are fantastic
- libAOM increases the binary size by 1MB which is a problem because users hate large apps (and yet, AV1 would save a lot more even on the first call) which becomes a political fight (we never heard about that from Google including it in libWebRTC and Chrome). It gets dynamically downloaded for that reason which also allows deciding whether it is really needed on this device (on low-end devices you don’t need to bother with AV1)
- At 11:40 “Talk time” is the key metric for Meta/Messenger and AV1 means at least 3x CPU usage (5x if you go for the best settings). This creates a goal conflict between battery (which lowers the metric) and increased quality (which increases it). More CPU does not mean more power usage however, the slide at 13:00 talks about measuring that and shows results with a single-digit percentage increase in power usage. This can be reduced further with some tweaks and using AV1 for low-bitrate scenarios and using it only when the battery level is high enough. WebRTC is getting support (in the API) for doing this without needing to resort to SDP manipulation, this is a good example of the use-case (which is being debated in the spec pull request)
- At 15:30 we get into a discussion about bitrate control, i.e. how quickly and well will the encoder produce what you asked for as shown in the slide:
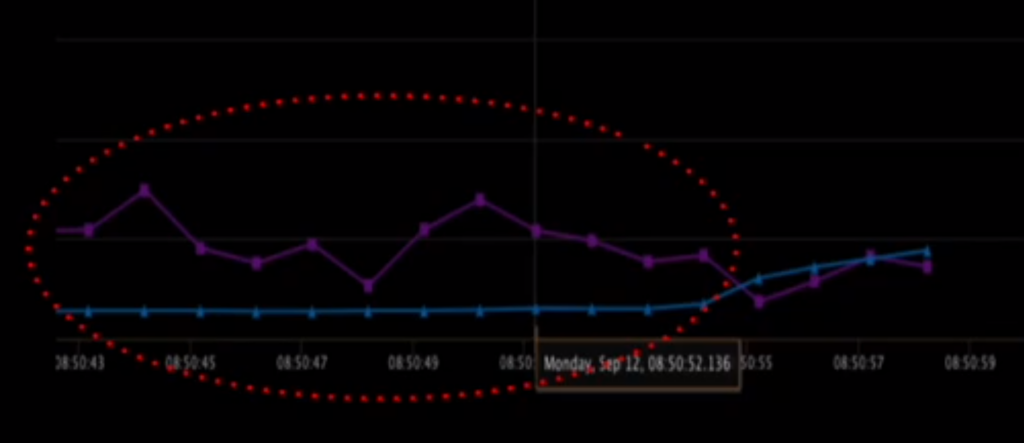
- Blue is the target bitrate, purple the actual bitrate and it is higher than the the bitrate for quite a while! Getting rate control on par with their custom H.264 one was a lot of work (due to Meta’s H.264 rate controller being quite tuned) and will hopefully result in an upstream contribution to libaom! The “laddering” of resolution and framerate depending on the target bitrate is an area that needs improvements as well, we have seen Google just ship some improvements in Chrome 113. The “field quality metrics” (i.e. results of getStats such as qpSum/framesEncoded) are codec-specific so cannot be used to compare between codecs which is an unsolved problem
- At 17:00 we get into the description of the current state and the outlook:
- This is being rolled out currently. Mobile support will come later and probably take the whole next year
- VR and game streaming are obvious use-cases with more control over devices and encoders
- VVC (the next version of HEVC) and AV2 are on the horizon, but only for the streaming industry and RTC lags behind by several years usually.
- H.264 (called “the G.711 of video” during Q&A) is not going to go away anytime soon so one needs to invest in dealing with multiple codecs
Jonathan Christensen / SMPL - Keeping it Simple

Duration: 18:40
Watch if you are
- A product manager who wants to understand the history of the industry, what products need to be successful and where we might be going
- Interested in how you can spend two decades in the RTC space without getting bored
Key insights:
- Great overview of the history of use-cases and how certain innovations were successfully implemented by products that shaped the industry by hitting the sweet spot of “uncommon utility” and “global usability”
- At 3:00: When ICQ shipped in 1996 it popularized the concept of “presence”, i.e. showing a roster of people who are online in a centralized service.
- At 4:40: next came MSN Messenger which did what ICQ did but got bundled with Windows which meant massive distribution. It also introduced free voice calling between users on the network in 2002. Without solving the NAT traversal issue which meant 85% of calls failed. Yep, that means not using a STUN server in WebRTC terms (but nowadays you would go 99.9% failure rate)
- At 7:00: While MSN was arguing who was going to pay the cost (of STUN? Not even TURN yet!) Skype showed up in 2003 and provided the same utility of “free voice calls between users” but they solved NAT traversal using P2P so had a 95% call success rate. They monetized it by charging 0.02$ per minute for phone calls and became a verb by being “Internet Telephony that just works”
- The advent of the first iPhone in 2007 led to the first mobile VoIP application, Skype for the iPhone which became the cash cow for Skype. The peer-to-peer model did however not work great there as it killed the battery quickly
- At 9:30: WhatsApp entered the scene in 2009. It provided less utility than Skype (no voice or video calls, just text messaging) and yet introduced the important concept of leveraging the address book on the phone and using the phone number as an identifier which was truly novel back then!
- When Whatsapp later added voice (not using WebRTC) they took over being “Internet Telephony that just works”
- At 11:40: Zoom… which became a verb during the 2020 pandemic. The utility it provided was a friction free model
- We disagree here, downloading the Zoom client has always been something WebRTC avoided, just as “going to a website” had the same frictionless-ness we saw with the earlyWebRTC applications like talky.io and the other we have forgotten about
- What it really brought was a freemium business model to video calling that was easy to use freely and not just for a trial period
- At 12:40: These slides ask you to think about what uncommon utility is provided by your product or project (hint: WebRTC commoditized RTC) and whether normal people will understand it (as the pandemic has shown, normal people did not understand video conferencing). What follows is a bit of a sales pitch for SMPL which is still great to listen to, small teams of RTC industry veterans would not work on boring stuff
- At 15:00: Outlook into what is next followed by predictions. Spatial audio is believed to be one of the things but we heard that a lot over the last decade (or two if you have been around for long enough; Google is shipping this feature to some Pixel phones, getting the name wrong), as is lossless codecs for screen sharing and Virtual Reality
- We can easily agree that the prediction that “users will continue to win” (in WebRTC we do this every time a Googler improves libWebRTC) but whether there will be “new stars” in RTC remains to be seen
First Q&A

Duration: 25:00
Watch if:
- You found the talks this relates to interesting and want more details
Key points:
- We probably needs something like Simulcast but for audio
- H.264 is becoming the G.711 of video. Some advice on what metrics to measure for video (freezes, resolution, framerate and qp are available through getStats)
- Multi-codec simulcast is an interesting use-case
- The notion that “RTC is good enough” is indeed not great. WebRTC suffers in particular from it
SESSION 2
Sandhya Rao / Microsoft - Top considerations for integrating RTC with Android appliances

Duration: 21:30
Watch if you are
- A product manager in the RTC space, even if not interested in Android
Key points:
- This is mostly a shopping list of some of the sections you’ll have in a requirements document. Make sure to check if there’s anything here you’d like to add to your own set of requirements
- Devices will be running Android OS more often than not. If we had to plot how we got there: Proprietary RTOS → Vxworks → Embedded Linux → Android
- Some form factors discussed:
- Hardware deskphone
- Companion voice assistant
- Canvas/large tablet personal device
- always-on ambient screen
- shared device for cross collaboration (=room system with touchscreen)
- Things to think through: user experience, hardware/OS, maintenance+support
- User experience
- How does the device give a better experience than a desktop or a mobile device?
- What are the top workloads for this device? focus only on them (make it top 3-5 at most)
- Hardware & OS
- Chipset selection is important. You’ll fall into the quality vs cost problem
- Decide where you want to cut corners and where not to compromise
- Understand which features take up which resources (memory, CPU, GPU)
- What’s the lifecycle/lifetime of this device? (5+ years)
- Maintenance & support
- Environment of where the device is placed
- Can you remotely access the device to troubleshoot?
- Security & authentication aspects
- Ongoing monitoring
Yun Zhang & Bin Liu / Meta - Scaling for large group calls

Duration: 19:00
Watch if you are
- A developer dealing with group calling and SFUs, covers both audio and video. Some of it describes the very specific problems Meta ran into scaling the group size but interesting nonetheless
Key points:
- The audio part of the talk starts at 2:00 with a retrospective slide on how audio was done at Meta for “small group calls”. For these it is sufficient to rely on audio being relatively little traffic compared to video, DTX reducing the amount of packets greatly as well as lots of people being muted. As conference sizes grow larger this does not scale, even forwarding the DTX silence indicator packets every 400ms could lead to a significant amount of packets. To solve this two ideas are used: “top-N” and “audio capping”
- The first describes forwarding the “top-N” active audio streams. This is described in detail in the Jitsi paper from 2015. The slideshow uses the same mechanism with audio levels as RTP header extension (the use of that extension was confirmed in the Q&A; the algorithm itself can be tweaked on the server). The dominant speaker decision also affects Bandwidth allocation for video:
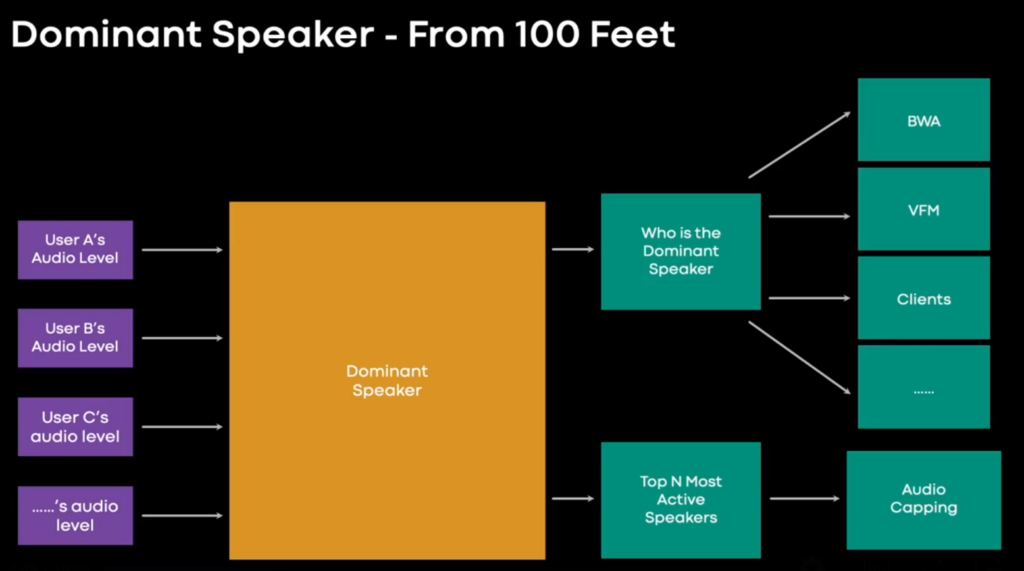
- The second idea is “audio capping” which does not forward audio from anyone but the last couple of dominant speakers. Google Meet does this by rewriting audio to three synchronization sources which avoids some of the PLC/CNG issues described on one of the slides. An interesting point here is at 7:50 where it says “Rewrite the Sequence number in the RTP header, inject custom header to inform dropping start/end”. Google Meet uses the contributing source here and one might use the RTP marker bit to signal the beginning or end of a “talk spurt” as described in RFC 3551
- The results from applying these techniques are shown at 8:40 - 38% reduction of traffic in a 20 person call, 63% for a 50 person call and less congestion from server to the client
- The video part of the talk starts at 9:30 establishing some of the terminology used. While “MWS” or “multiway server” is specific to Meta we think the term “BWA” or “bandwidth allocation” to describe how the estimated bandwidth gets distributed among streams sent from server to client is something we should talk more about:
- Capping the uplink is not part of BWA (IMO) but if nobody wants to receive 720p video from you, then you should not bother encoding or sending it and we need ways for the server to signal this to the client
- The slide at 10:20 shows where this is coming from, Meta’s transition from “small group calls” to large ones. This is a bit more involved than saying “we support 50 users now”. Given this mention “lowest common denominator” makes us wonder if simulcast was used by the small calls even because it solves this problem
- Video oscillation, i.e. how and when to switch between layers which needs to be done “intelligently”
- Similarly, bandwidth allocation needs to do something smarter than splitting the bandwidth budget equally. Also there are bandwidth situations where you can not send video and need to degrade to sending only one and eventually none at all. Servers should avoid congesting the downstream link just as clients do BWE to avoid congesting the upstream
- The slide at 13:00 shows the solution to this problem. Simulcast with temporal layers and “video pause”:
- Simulcast with temporal layers provides (number of spatial layers) * (number of temporal layers) video layers with different bitrates that the server can pick from according to the bandwidth allocation
- “Video pause” is a component of what Jitsi called “Video pausing” in the “Last-N” paper
- It is a bit unclear what module the “PE-BWA” replaces but taking into account use-cases like grid-view, pinned-user or thumbnail makes a lot of sense
- Likewise, “Stream Subscription Manager” and “Video Forward Manager” are only meaningful inside Meta since we cannot use it. Maximizing for a “stable” experience rather than spending the whole budget makes sense. So do the techniques to control the downstream bandwidth used, picking the right spatial layer, dropping temporal layers and finally dropping “uninteresting” streams
- At 18:10 we get into the results for the video improvements:
- 51% less video quality oscillation (which suggests the previous strategy was pretty bad) and 20% less freezes
- 34% overall video quality improvement, 62% improvement for the dominant speaker (in use-cases where it is being used; this may include allocating more bandwidth to the most recent dominant speakers)
- At 18:30 comes the outlook:
- Dynamic video layers structure sounds like informing the server about the displayed resolution on the client and letting it make smart decisions based on that
Saish Gersappa & Nitin Khandelwa / Whatsapp - Relay Infrastructure

Duration: 15:50
Watch if you are
- A developer dealing with group calling and SFUs. Being Whatsapp this is a bit more distant from WebRTC (as well as the rest of the “unified” Meta stack?) but still has a lot of great points
Key points:
- After an introduction of Whatsapp principles (and a number… billion of hours per week) for the first three minutes the basic “relay server” is described which is a media server that is involved for the whole duration of the call (i.e. there is no peer-to-peer offload)
- The conversation needs to feel natural and network latency and packet loss create problems in this area. This gets addressed by using a global overlay network and routing via those servers. The relay servers are not run in the “core” data centers but at the “points of presence” (thousands) that are closer to the user. This is a very common strategy we have always recommended but the number and geographic distribution of the Meta PoPs makes this impressive. To reach the PoPs the traffic must cross the “public internet” where packet loss happens
- At 5:30 this gets discussed. The preventive way to avoid packet loss is to do bandwidth estimation and avoid congesting the network. Caching media packets on the server and resending them from there is a very common method as well, typically called a NACK cache. It does not sound like FEC/RED is being used or at least not mentioned.
- At 6:30 we go into device resource usage. An SFU with dominant speaker identification is used to reduce the amount of audio and video streams as well as limit the number of packets that need to be encrypted and decrypted. All of this costs CPU which means battery life and you don’t want to drain the battery
- For determining the dominant speaker the server is using the “audio volume” on the client. Which means the ssrc-audio-level based variant of the original dominant speaker identification paper done by the Jitsi team.
- Next at 8:40 comes a description of how simulcast (with two streams) is used to avoid reducing the call quality to the lowest common denominator. We wonder if this also uses temporal scalability, Messenger does but Whatsapp still seems to use their own stack
- Reliability is the topic of the section starting at 10:40 with a particular focus on reliability in cases of maintenance. The Whatsapp SFU seems to be highly clustered with many independent nodes (which limits the blast radius); from the Q&A later it does not sound like it is a cascading SFU. Moving calls between nodes in a seamless way is pretty tricky, for WebRTC one would need to both get and set the SRTP state including rollover count (which is not possible in libSRTP as far as we know). There are two types of state that need to be taken into account:
- Critical information like “who is in the call”
- Temporary information like the current bandwidth estimate which constantly changes and is easy to recover
- At 12:40 we have a description of handling extreme load spikes… like calling all your family and friends and wishing them a happy new year (thankfully this is spread over 24 hours!). Servers can throttle things like the bandwidth estimate in such cases in order to limit the load (this can be done e.g. when reaching certain CPU thresholds). Prioritizing ongoing calls and not accepting new calls is common practice, prioritizing 1:1 calls over multi party calls is acceptable for Whatsapp as a product but would not be acceptable for an enterprise product where meetings are the default mode of operation
- Describing dominant speaker identification and simulcast as “novel approaches” is…
not quitenovel
Second Q&A

Duration: 28:00
Watch if:
- You found the talks this relates to interesting and want more details
Key points:
- There were a lot more questions and it felt more dynamic than the first Q&A
- Maximizing video experience for a stable and smooth experience (e.g. less layer switches) often works better than chasing the highest bitrate!
- Good questions and answers on audio levels, speaker detection and how BWE works and is used by the server
- It does sound like WhatsApp still refuses to do DTLS-SRTP…
SESSION 3
Vinay Mathew / Dolby - Building a flexible, scalable infrastructure to test dolby.io at scale

Duration: 22:00
Watch if you are
- A software developer or QA engineer working on RTC products
Key points:
- Dolby.io today has the following requirements/limits:
- Today: 50 participants in a group call; 100k viewers
- Target: 1M viewers; up to 25 concurrent live streams; live performance streaming
- Scale requires better testing strategies
- For scale testing, Dolby split the functionality into 6 different areas:
- Authentication and signaling establishment - how many can be handled per second (rate), geo and across geo
- Call signaling performance - maximum number of join conference requests that can be handled per second
- Media distribution performance - how does the backend handle the different media loads, looking at media metrics on client and server side
- Load distribution validation - how does the backend scale up and down under different load sizes and changes
- Scenario based mixing performance - focus on recording and streaming to huge audiences (a specific component of their platform)
- Metrics collection from both server and client side - holistic collection of metrics and use a baseline for performance metrics out of it
- Each component has its own set of metrics and rates that are measured and optimized separately
- Use a mix of testRTC and in-house tools/scripts on AWS EC2 (Python based, using aiortc; locust for jobs distribution)
- Homegrown tools means they usually overprovision EC2 instances for their tests. Something they want to address moving forward
- Dolby decided not to use testRTC for scale testing. Partly due to cost issues and the need to support native clients
- The new scale testing architecture for Dolby:
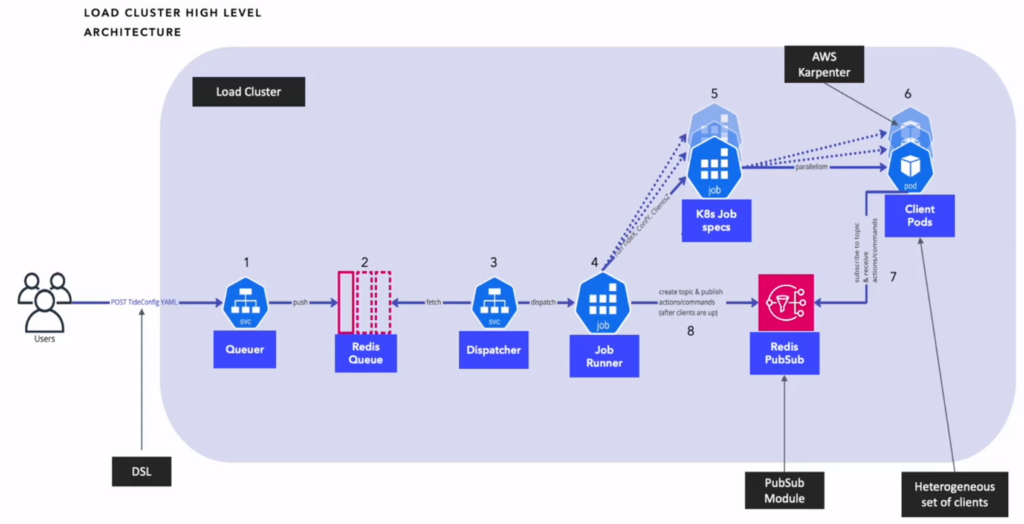
- Mix of static and on demand EC2 instances, based on size of the test
- Decided on a YAML based syntax to define the scenario
- Scenarios are kept simple, and the scripting language used is proprietary and as a domain specific language
- This looks like the minimal applicable architecture for stress testing WebRTC applications. If you keep your requirements of testing limited, then this approach can work really well
Jay Kuo / USC - blind quality assessment of real-time visual communications

Duration: 18:15
Watch if you
- Want to learn how to develop ways to measure video quality in an RTC scenario
Key points:
- We struggled a bit with this one as it is a bit “academic” (with an academic sales pitch even!) and not directly applicable. However, this is a very hard problem that needs this kind of research first
- Video quality assessment typically requires both the sender side representation of the video and the receiver side. Not requiring the sender side video is called “blind quality assessment” and is what we need for applying it to RTC or conversational video
- Ideally we want a number from such a method (called BVQA around 4:00) that we can include in the getStats output. The challenge here is doing this with low latency and efficiently in particular for Meta’s requirements to run on mobile phones
- We do wonder how background blur affects this kind of measurement. Is the video codec simply bad for those areas or is this intentional…
Wurzel Parsons-Keir / Meta - Beware the bot armies! Protecting RTC user experiences using simulations

Duration: 25:00
Watch if you are
- Interested in a better way to test than asking all your coworkers to join you for a test (we all have done that many times)
- A developer that wants to test and validate changes that might affect media quality (such as bandwidth estimation)
- Want to learn how to simulate a ten minute call in just one minute
- Finally want to hear a good recruiting pitch for the team (the only one this year)
- Yes, Philipp really liked this one. Wurzel’s trick of making his name more appealing to Germans works so please bear with him.
Key takeaways:
- This is a long talk but totally worth the time
- At 3:00 some great arguments for investing in developer experience and simulation, mainly by shifting the cost left from “test in production” and providing faster feedback cycles. It also enables building and evaluating complex features like “Grid View and Pagination” (which we saw during the keynote) much faster
- After laying out the goals we jump to the problem at 6:00. Experiments in the field take time and pose a great risk. Having a way to test a change in a variety of scenarios, conditions and configuration (but how representative are the ones you have?) shortens the feedback cycle and reduces the risk
- At 7:30 we get a good overview of what gets tested in the system and how. libWebRTC is just a small block here (but a complex one) followed by the introduction of “Newton” which is the framework Meta developed for deterministic and faster than real-time testing. A lot of events in WebRTC are driven by periodic events, such as a camera delivering frames at 30 frames per second, RTCP being sent at certain intervals, networks having a certain bits-per-second constraints and so on
- At 9:20 we start with a “normal RTC test”, two clients and a simulated network. You want to introduce random variations for realism but make those reproducible. The common approach for that is to seed the random generator, log the seed and allow feeding it in as a parameter to reproduce
- The solution to the problem of clocks is sadly not to send a probe into the event horizon of a black hole and have physics deal with making it look faster on the outside. Instead, a simulated clock and task queue is used. Those are again very libWebRTC specific terms, it provides a “fake clock” which is mainly used for unit tests. Newton extends this to end-to-end tests, the secret sauce here is how to tell the simulated network (assuming it is an external component and not one simulated by libWebRTC too) about those clocks as well
- After that (around 10:30) it is a matter of providing a great developer experience for this by providing scripts to run thousands of calls, aggregate the results and group the logging for these. This allows judging both how this affects averages as well identifying cases (or rather seed values!) where this degraded the experience
- At 12:00 we get into the second big testing system built which is called “Callagen” (such pun!) which is basically a large scale bot infrastructure that operates in real-time on real networks. The system sounds similar to what Tsahi built with testRTC in many ways as well as what Dolby talked about. Being Meta they need to deal with physical phones in hardware labs. One of the advantages of this is that it captures both sender input video as well as receiver output video, enabling traditional non-blind quality comparisons
- Developer experience is key here, you want to build a system that developers actually use. A screenshot is shown at 14:40. We wonder what the “event types” are. As suggested by the Dolby talk there is a limited set of “words” in a “domain specific language” (DSL) to describe the actions and events. Agreeing on those would even make cross-service comparisons more realistic (as we have seen in the case of Zoom-vs-Agora this sometimes evolves into a mud fight) and might lead to agreeing on a set of commonly accepted baseline requirements for how a media engine should react to network conditions
- The section starting at 16:00 is about how this applies to… doing RTC testing @scale at Meta. It extends the approach we have seen in the slides before and again reminds us of the Dolby mention of a DSL. As shown around 17:15 the “interfaces” for that are appium scripts for native apps or python-puppeteer ones for web clients (we are glad web clients are tested by Meta despite being a niche for them!)
- At 17:40 the challenge of ensuring test configurations are representative. This is a tough problem and requires putting numbers on all your features so you can track changes. And some changes only affect the ratios in ways that… don’t show up until your product gets used by hundreds of millions of users in a production scenario. Newton reduces the risk here by validating with a statistically relevant number of randomized tests at least which increases the organizational confidence. Over time it also creates a feedback loop of how realistic the scenarios you test are. Compared to Google, Meta is in a pretty good position here as they only need to deal with a single organization doing product changes which might affect metrics rather than “everyone” using WebRTC in Chrome
- Some example use-cases are given at 19:15 that this kind of work enables. Migrating strategies between “small calls” and “large calls” is tricky as some metrics will change. Getting insight into which ones and whether those changes are acceptable (while retaining the metrics for “small ones”) is crucial for migrations
- Even solving the seemingly “can someone join me on a call” problem provides a ton of value to developers
- The value of enabling changes to complex issues such as anything related to codecs cannot be underestimated
- Callagen running a lot of simulations on appium also has the unexpected side-effect of exposing deadlocks earlier which is a clear win in terms of shifting the cost of such a bug “left” and providing a reproduction and validation of fixes
- Source-code bisect, presented at 21:00, is the native libWebRTC equivalent of Chromium’s bisect-build.py together with bisect-variations.py. Instead of writing a jsfiddle, one writes a “sim plan”. And it works “at scale” and allows observing effects like a 2% decrease in some metric. libWebRTC has similar capabilities of performance monitoring to identify perf regressions that run in Google’s infrastructure but that is not being talked about much by Google sadly
- A summary is provided at 23:00 and there is indeed a ton to be learned from this talk. Testing is important and crucial for driving changes in complex systems such as WebRTC. Having proof that this kind of testing provides value makes it easier to argue for it and it can even identify corner cases
- At 24:00 there is a “how to do it yourself” slide which we very much appreciate from a “what can WE learn from this”. While some of it seems like generally applicable to testing any system, thinking about the RTC angle is useful and the talk gave some great examples. That small, take baby steps. They will pay off in the long run (and for “just” a year of effort the progress seems remarkable)
- There is a special guest joining at the end!
Sid Rao / Amazon - Using Machine learning to enrich and analyze real-time communications

Duration: 17:45
Watch if you are
- A developer Interested in audio quality
- A product manager that wants to see a competitor’s demo
Key points:
- This talk is a bit sales-y for the Chime SDK but totally worth it. As a trigger warning, “SIP” gets mentioned. This covers three (and a half) use cases:
- Packet loss concealment which improves the opus codec considerably
- Deriving insights (and value) from sessions, with a focus on 1:1 use-cases such as contact centers or sales calls
- Identifying multiple speakers from the same microphone (which is not a full-blown use-case but still very interesting)
- Speech super resolution
- Packet loss concealments start at 3:40. It is describing how Opus as a codec is tackling the improvements that deep neural networks can offer. Much of is also described in the Amazon blog post and we describe our take on it in WebRTC Insights #63. This is close to home for Philipp obviously:
- RFC 2198 provides audio redundancy for WebRTC. It was a hell of a fight to get that capability back in WebRTC but it was clear this had some drawbacks. While it can improve quality significantly It cannot address bigger problems such as burst loss effectively
- Sending redundant data only when there is voice activity is a great idea. However, libWebRTC has a weird connection between VAD and the RTP marker bit and fixing this caused a very nasty regression for Amazon Chime (in contact centers?) which was only noticed once this hit Chrome Stable. This remains unsolved, as well as easy access to the VAD information in APIs such as Insertable Streams that can be used for encoding RED using Javascript
- It is not clear how sending redundant audio which are part of the same UDP packet is making the WiFi congestion problem worse at 4:50 (audio NACK would resend packets in contrast)
- The actual presentation of DRED starts at 5:20 and has a great demo. What the demo does not show is that the magic is how little bitrate is used compared to just sending x10 the amount of data. Which is the true magic of DRED. Whether it is worth it remains to be seen. Applying it to the browser may be hard due to the lack of APIs (we still lack an API to control FEC bandwidth or percentage) but if the browser can decode DRED sent by a server (from Amazon) thanks to the magic tricks in the wire format that would be a great win already (for Amazon but maybe for others as well so we are approving this)
- Deriving insights starts at 9:15 and is great at motivating why 1:1 calls, while considered boring by developers, are still very relevant to users:
- Call centers are a bit special though since they deal with “frequently asked questions” and provide guidance on those. Leveraging AI to automate some of this is the next step in customer support after “playbooks” with predefined responses
- Transcribing the incoming audio to identify the topic and the actual question does make the call center agent more productive (or reduces the value of a highly skilled customer support agent) with clear metrics such as average call handle time while improving customer satisfaction which is a win-win situation for both sides (and Amazon Chime enabling this value)
- Identifying multiple speakers from the same microphone (also known as diarisation) starts at 10:55:
- The problem that is being solved here is using a single microphone (but why limit to that?) to identify different persons in the same room speaking when transcribing. Mapping that to a particular person’s “profile” (identified from the meeting roster) is a bit creepy though. And yet this is going to be important to solve the problem of transcription after the push to return to the office (in particular for Amazon who doubled down on this). The demo itself is impressive but the looks folks give each other… 🥸
- The diversity of non-native speakers is another subtle but powerful demo. Overlapping speakers are certainly a problem but people are less likely to do this unintentionally while being in the same room
- We are however unconvinced that using a voice fingerprint is useful in a contact center context (would you like your voice fingerprint being taken here), in particular since the caller's phone number and a lookup based on that has provided enough context for the last two decades
- Voice uplift (we prefer “speech super resolution”) starts at 14:35. It takes the principle of “super resolution” commonly applied to video (see this KrankyGeek talk) and applies it to… G.711 calls:
- With the advent of WebRTC and the high-quality provided by Opus we got used to the level of quality it provides which means that we perceive the worse quality of a G.711 narrowband phone call much more which causes fatigue when listening to those. While this may not be relevant to WebRTC developers this is quite relevant to call center agents (whose ears are on the other hand not accustomed to the level of quality Opus provides)
- G.711 reduces the audio bandwidth by narrowing the signal frequency range to [300Hz, 3.4 kHz]. This is a physical process and as such not reversible. However, deep neural networks have listened to enough calls to reconstruct the original signal with sufficient fidelity
- This feature is a differentiator in the contact center space, where most calls still originate from PSTN offering G.711 narrowband call quality. Expanding this to wideband for contact center agents may bring big benefits to the agent’s comfort and by extension to the customer experience
- The summary starts at 16:00. If you prefer just the summary so far, listen to it anyway:
- DRED is available for integration “into the WebRTC” platform. We will see whether that is going to happen faster than the re-integration of RED which took more than a year
Third Q&A

Duration: 19:45
Watch if
- You found the talks this relates to interesting and want more details
Key points:
- A lot of questions about open sourcing the stuff that gets talked about
- Great questions about Opus/DRED, video quality assessment, getting representative network data for Newton (and how it relates to the WebRTC FakeClock)
- The problem with DRED is that you don’t have just a single model but different models depending on the platform. And you can’t ship all of them in the browser binary…
SESSION 4
Ishan Khot & Hani Atassi / Meta - RSYS cross-platform real-time system library

Duration: 18:15
Watch if you are
- A software architect that has worked with libWebRTC as part of a larger system
Key points:
- This talk is a bit of an internal talk since we can’t download and use rsys which makes it hard to relate to it which is only possible if you have done your own integration of libWebRTC into a larger system
- rsys is Meta’s RTC extension of their msys messaging library. It came out of Messenger and the need to abstract the existing codebase and make it more usable for other products. This creates an internal conflict between “we care only about our main use-case” and “we want to support more products” (and we know how Google’s priorities are in WebRTC/Chrome for this…). For example, Messenger made some assumptions about video streams and did not consider screen sharing to be something that is a core feature (as we saw in the keynote that has changed)
- You can see the overall architecture at 8:00
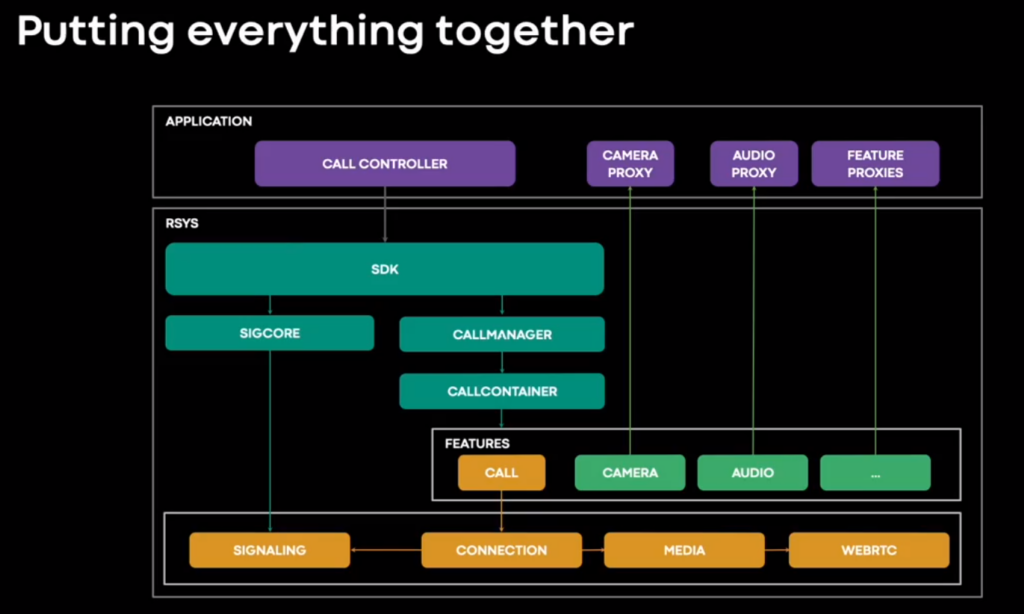
- With (lib)WebRTC being just one of many blocks in the diagram (the other two interesting ones are “camera” and “audio” which relate to the device management modules from the second talk. Loading libWebRTC is done at runtime to reduce the binary size of the app store download
- The slides that follow are a good description of what you need besides “raw WebRTC” like signaling and call state machines
- The slides starting at 12:20 focus on how testing is done as well as debuggability and monitoring
- The four-minute outlook which starts at 14:00 makes an odd point about 50 participants in a call being a challenge
Raman Valia & Shreyas Basarge / Meta - Bringing RTC to the Metaverse

Duration: 22:00
Watch if you are
- Interested in the Metaverse and what challenges it brings for RTC
- A product manager that wants to understand how it is different from communication products
- An engineer that is interested in how RTC concepts like Simulcast are applicable to a more generic “world state” (or game servers as we think of them)
Key points:
- The Metaverse is not dead yet but we still think it is called Fortnite
- The distinction between communicating (in a video call) and “being present” is useful as the Metaverse tries to solve the latter and is “always on”
- Around 5:00 delivering media over process boundaries is actually something where WebRTC can provide a better solution than IPC (but one needs to disable encryption for that use-case)
- Embodiment is the topic that starts at 7:00. One of the tricky things about the Metaverse is that due to headsets you cannot capture a person’s face or landmarks on it since they are obscured by AR/VR devices
- The distinction between different “levels” of Avatars, stylized, photorealistic and volumetric at 8:30 is interesting but even getting to the second stage is going to be tough
- Sharing the world state that is being discussed at 15:00 is an adjacent problem. It does require systems similar to RTC in the sense that we have mediaserver-like servers (you might call them game servers) and then need techniques similar to simulcast. Also we have “data channels” with different priorities. And (later on) even “floor control”
- For the outlook around 20:30 a large concert is mentioned as a use-case. Which has happened in Fortnite since 2019
Fourth Q&A

Duration: 14:10
Watch if
- You found the talks this relates to interesting and want more details
Key points:
- rsys design assumptions which led to the current architecture and how its performance gets evaluated. And how they managed to keep the organization aligned on the goals for the migration
- Never-ending calls in the Metaverse and privacy expectations which are different in a 1:1 call and a virtual concert
Closing remarks
We tried capturing as much as possible, which made this a wee bit long. The purpose though is to make it easier for you to decide in which sessions to focus, and even in which parts of each session.
Oh - and did we mention you should check out (and subscribe) to our WebRTC Insights service?
